
by Dafna Rosenblum
How I established a good release process in JavaScript
With Git Workflows, NPM, and 3rd party libraries
Lately, I’ve sat down to define the release procedures for my team. I went through git workflows, best practices for versioning, and methods to upgrade external libraries. I wanted to have all my learning in one place, because I know I’ll get back to that in the future. I hope you’ll find it helpful as well.
In this article I will explain how to combine git workflow, semver, and NPM to create healthy library management and CI in JavaScript. It began bothering me when my team became bigger and we had to create a better process that worked for everyone and that we agreed upon. I read about 20 articles to create this elaborate combined summary of different practices and official recommendations.

GIT FLOW
There are different patterns to using Git. The patterns dictate what types of branches will exist in the project, their naming conventions, when to use each type and so on. The most well-known pattern is Git Flow.
GitFlow is like Agile — everyone is using some version of it.
It was created in January 2010 by Vincent Driessen. It has been heavily used since then, although there are many critics of it. I’ll elaborate on their perspective after explaining the methodology itself.
I highly recommend reading it entirely and using the below summary as a cheat sheet only (it contains some extra insights as well).
Two Types Of Branches
Infinite lifetime branches: master and develop
- origin/master is always production ready.
- origin/develop always includes the latest delivered changes for the next release. When it’s ready, it’s merged to master and the changes are tagged with a release number.
Limited lifetime branches
- Feature branches
- Release branches
- Hot-fix branches
Let’s go through each of these in more detail.
Feature Branches
- Branched off from and merged back to develop.
- Naming convention: anything except master, develop, release-*, or hotfix-*. I love to use the prefix
feature/, for examplefeature/fix-texts.
When merging back to develop, Vincent recommends using the —-no-ff flag, that always creates a new commit for the merge. This allows you to have as better understanding of tracking of history and know what commits were released together as a feature. It also simplifies reverting a feature.
Release Branches
- Branched off from develop and merged back to develop and master.
- Naming convention: release-*, for example: release-1.2.
- Purpose: last minute small changes, so that develop is clear to receive changes for the next release.
Until branching off the release branch, the changes for the next release can’t be merged to develop. The version number is defined when creating the release branch, and used as its name.
npm-version
After creating the release branch, you should running ./bump-version.sh. This is a fictional script that updates the version number of the project. As I mentioned, the Git Flow article is from January 2010. This is also the month NPM was first released (coincidence??), and I prefer using npm-version like below:
> npm version patchThe output will be the new version number. A commit will be added to the branch with the new version updated in the package.json and package-lock.json files.
Run git log -1 and then git show <commit hash> to see the changes.
For changing minor version or major, use npm version minor or npm version major, accordingly.
Use -m flag to add a commit message, otherwise it will be the number of the new version.
If preversion, version, or postversion are in the scripts property of the package.json — they will be executed as well.
It will also create a git tag. You can see that by running git tag before and after running npm version patch, and notice the difference.
As explained in the git tag documentation, by default, the git push command doesn’t transfer tags to remote servers. You will have to explicitly push tags to a shared server after you have created them. This process is just like sharing remote branches . You can run git push origin v1.5.1. It’s also possible to delete and check-out local and remote tags.
An alternative to npm-version is the popular tool release-it, that can bump version, create tags and releases, and more.
Back To Release Branches
So you created a release branch, ran npm version patch and pushed. Maybe you also added minor bug fixes. The next step is to merge to master and release.
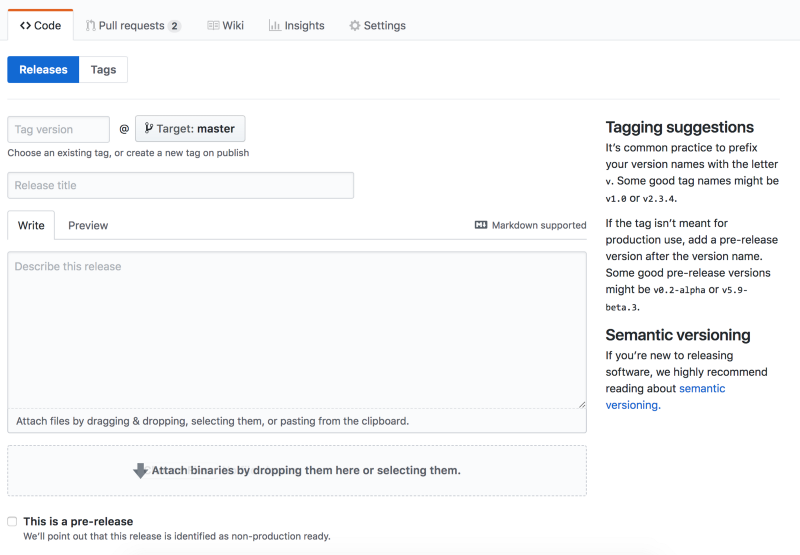
Creating a Release From Tag
As explained in GitHub documentation, when creating a release, you need to type a version number for it. Versions are based on Git tags. Below the version input area, you’ll see the text: Choose an existing tag, or create a new tag on publish. You can choose whether to push the tag created by npm-version and then type it again when creating the release, or you can choose not to push it, and type it when creating the release. Of course, you can create automatic release instead of manually using GitHub website.
Merge Back To develop
Don’t forget to merge back the release branch to develop. Then the release branch can be deleted. You might experience merge conflicts here, so just fix them and commit.
Hotfix Branches
- Contain fixes for urgent production bugs.
- Branched off from master, and merged back to develop and master.
- Naming convention:
hotfix-*.
Like release branches, they’re meant to prepare for a new release, and the process of creating the branch and finishing it is exactly the same.
If you work with Release Branches, and a release branch exists, try not to merge it back to develop, but to the release branch, that will be merged into develop later.
Is That So?
This is the Git Flow way. It will work better with waterfall methodology. The recommended way to work today is Continuous Deployment — be fully covered by tests, have no develop branch, merge the feature branches to master and deploy immediately.
But the type of product and market might dictate a different kind of deployment process sometimes. For example, in healthcare, it’s not always possible to have continuous deployment, due to regulations. In the gaming industry, there are release dates to games and they often don’t work with continuous integration and delivery.
OPPONENETS
If you look for “don’t use gitflow” on Google, you can find a lot of articles. Here are the main points in some of them:
#1
In his blog “End Of Line”, Adam Ruka states that using the --no-ff flag results with “git train maps” (see photo), that are very hard to track in retrospective. He highly recommends using rebase instead.
He also claims that the methodology is too complex, and that it’s impossible for developers not to make mistakes and merge from/to the wrong branch.
While I agree with the first point, I think that build automation (like automatic tagging) and well-configured branches on GitHub can solve most of the human errors. He offers a different take on Git Flow in this article.
#2
In his article “Git: How I use it and Why I don’t use GitFlow”, Matthew DeKrey says about the develop branch:
“Having code in a common place where it’s not fully tested and not necessarily working towards a feature that is to be released ends up being a ghost town of half-completed architectures and not-released features if the team is ever busy.”
I think that with some discipline and a decent CI, the team will merge (or rebase) to develop only features that are ready and passed unit tests and integration tests, and then the nightly test suit (or system tests) can run on develop and make sure features work together.
The other problem that he mentions is supporting old versions: “once you cut release v1.2, you can no longer patch v1.1”. And in this article you can also find his recommended way to work with Git branches.
#3
In his article GitHub workflows inside of a company, Nicholas C. Zakas says:
“The general feeling is that git-flow works well for products in a more traditional release model, where releases are done once every few weeks, but that this process breaks down considerably when you’re releasing once a day or more”.
A year and a half after the publication of Git Flow, Scott Chacon, an engineer who helped start GitHub, published GitHub flow, which is a simpler version of Git Flow that works better for CD projects.
WHAT TO CHOOSE THEN?
One of the problems we are facing in the industry today is battling the perception that there’s only one way to do things right. We ignore the fact that different teams, products and markets require different solutions.
Of course, before choosing a technology or pattern, the team needs to understand the pros and cons of using it. But there’s no “one solution fits all”. In this recommended article of Atlassian (BitBucket), they review some possible Git workflows, and say:
“Remember that these workflows are designed to be guidelines rather than concrete rules. We want to show you what’s possible, so you can mix and match aspects from different workflows to suit your individual needs. When evaluating a workflow for your team, it’s most important that you consider your team’s culture.”
Later they add:
“There is no one size fits all Git workflow. It’s important to develop a Git workflow that is a productivity enhancement for your team. In addition to team culture, a workflow should also complement business culture. Git features like branches and tags should complement your business’s release schedule.”
They recommend working towards short-lived branches and aiming to minimize and simplify reverts.
Squashed commits or not?
Another question I was wondering about is what’s better: having one commit per feature or having small commits, so that you can look at the annotation of some line and understand exactly why this specific change has been made.
Now that I’ve educated myself with the healthy approach of the Atlassian article mentioned above, I think it highly depends on the project. For open source projects, with a lot of remote contributors, it’s better to squash, to keep the high level vision about the project.
For stable organizations in which at least part of the team continues working on the project at any given moment, it’s better to elaborate and keep small commits, but only if two conditions are met:
- With indicative messages and not “wip”, “fix”, etc.
- Every commit on its own does not break the build or the product, i.e., if a feature contains 3 commits, and we revert 2 of them, the product is stable and working well.
SEMVER
Semver, or Semantic Versioning, is a specification of name convention for versions of code projects. You can find the link to it on the release page of GitHub.
The idea is that every new release will have a version number of the form x.y.z, for example: 1.1.2. The x is increased when a major version is out — i.e. when an API breaks. The y — minor — new functionality but the API changes in a backwards compatible way, and the z — patch — is increased when doing a bug fix in a backwards compatible way.
This is an NPM tool to verify it.
JavaScript Versioning
NPM encourages JavaScript developers to keep the Semver methodology. It should definitely be something to take into consideration when creating your own git workflow.
Updating External Libraries Should Not be Part of Your Git Workflow
When working with NPM, if you don’t change your default configuration, installing new packages will install them with a carat: ^. You will see something like this in your package.json:
“dependencies”: { “my_dep”: “^1.0.0”,}If you don’t want to have the carat, and you want to use a fixed version, you can install like this:
npm install foobar --save --save-exactOr better, you can define it in your .npmrc config file, like this:
npm config set save=truenpm config set save-exact=trueThe above is from Heroku’s Best Practices for Node.js Development article. But why is it recommended?
To understand that, I highly recommend reading Pinning Dependencies and Lock Files by Renovate. To summarize the main points:
- “A lock file [package-lock.json] will lock down the exact dependencies and sub-dependencies that your project uses, so that everyone running
npm installwill install the exact same dependencies as the person that last updated the lock file.” You can see why it’s problematic not to use your lock file — things might break in production due to a change in some dependency, and it will be very hard to track the problem, because you’ll have a different version of this dependency on your local environment. - A lock file isn’t made to be human-readable. In case a new version of a third-party library you use is released, and it’s within the range of the allowed versions in the package.json file, the package-lock.json will make sure everyone just uses the fixed version that has been defined when it was last updated. For example, in your package.json you have this definition:
“dependencies”: { “my_dep”: “^1.0.0”,}Now if my_dep team releases a new major version, 2.0.0, it will never be used by your application, unless you manually update it.
But if they release minor version, 1.2.0, then it will not be used by your application as well, in any environment, because the lock file is making sure a fixed version is used — the one that was within the range that last time it was updated.
However, if you update your lock file (by running npm update, which updates the lock file according to the rule defined in the package.json file), 1.2.0 will become your fixed version that is defined in the lock file, and it will be hard to track that.
- The usual recommendation is to use a lock file regardless of whether you pin dependencies or not, and pinning even if you have a lock file.
In case you choose to pin dependencies, you need some automatic mechanism to upgrade them, so that security fixes and other useful new features won’t surprise you all the time and interfere with your product plan. Renovate is one solution for that, and Dependabot is also a good option. I’m sure you can find more. I think it’s a great solution even if you don’t pin the versions, because there are always new versions that can be outside of the range.
Summary
- It’s important for any engineer to know different Git workflows, and to understand the semver methodology and how to use lock files.
- Different teams need different workflows. It depends on the market and the team, and the workflow should make life as easy as possible for the engineers using it, allowing them to release stable code fast.
- I think the closest workflow to what I want to work with is described in this article — Feature Branch Workflow.
- It’s nice to use semver and fixed versions, together with a service that helps upgrading third party libraries.
- I’m a great fan of design patterns and I loved reading the different patterns to work with Git.