
A little while back I found myself in a position where my team and I were implementing a rather heavy runtime operation on our ecommerce website. It involved the percolator functionality in Elasticsearch (I'm planning to do a write-up of how we're using that and how we optimized its performance shortly, so please click follow below if you'd like to read more about that).

When developing software, performance is or should always be a concern, but when working on a large ecommerce platform the results of performance changes become extremely visible since we can immediately correlate decreased conversion and thus lost revenue to increased page load times. Running percolate queries in Elasticsearch is a heavy and in performance terms "expensive" operation by nature, so that gave us an even bigger incentive to focus on keeping it fast.
Once we had implemented the feature and put it "live" behind a feature switch for our internal users, without any caching, we saw the feature worked as intended, and the time it took to run the query was acceptable. We did however notice it was putting strain on our Elasticsearch cluster to a certain extent. Nothing particularly worrisome, but we should be able to do better.
Optimizing our cache usage
When writing items to our cache, we usually consider how up-to-date we need them to be. For example, a product price or stock status can't be cached for more than a few minutes, but the name of a product can safely be cached for an hour or longer, since the latter is not as likely to change as the former. Realizing what type of data you're dealing with and how volatile that data is, is a good first step in determining how long you should persist it in cache.
In our case a lot of data we're caching is based on the work done by our colleagues in our commercial teams. New products are added, the navigation structure of the site is changed, content is written, etc. Within our company a workday usually doesn't start before 8am and ends before 6pm. That's valuable input for our caching strategy, because that means the result of our Elasticsearch query will not change between 6pm and 8am the next day. Or between friday 6pm and monday morning 8am even.
We started using this as input for determining our cache TTLs:
- Storing the result of the query in cache on a Tuesday at 8pm? Expire it the next morning at 8am.
- Storing the result of the query in cache on a Saturday at 11am? Expire it on Monday morning at 8am.
This is how what our cache TTLs look like now, the horizontal axis obviously being time, the vertical axis being number of seconds we allow the item to live in cache.

Notice the pattern? Every evening the cache TTL goes way up and every friday evening the TTL goes even further up. The flat line at the bottom is our default TTL of 3600 seconds during the workday, which is a balance between using the cache and allowing changes to pop up on the website quickly.
So what did that do to our cache hit percentage?
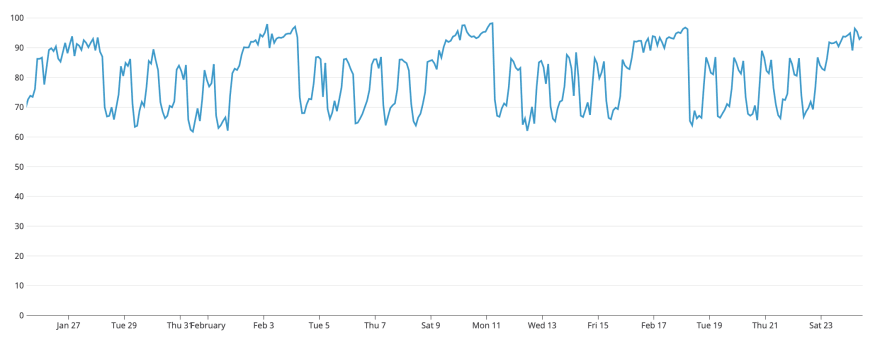
As you can see:
- On weekday evenings, cache hit percentage increases from roughly 65% to roughly 85%
- During weekends we usually see cache hit percentages between 90% and 100%.
Learnings
Initially we had missed one rather crucial point. It was easy to say, all these items expire next monday at 8am. However, if we had thought about that for a little bit longer, we would have realized this would cause a mass cache eviction at exactly that time. To prevent this and suddenly make this cache completely cold, we added some "fuzzing" (for the lack of a better word) to the expiration and started expiring within half an hour on either side of the actual threshold.
Getting started
I have created a tiny PHP library that you can use to start doing the same, although the concept is obviously not limited to PHP and porting the same functionality to any other language should be trivial. It can easily be installed through composer:
$ composer require erikbooij/cache-scheduler
The source can be checked out here:
 ErikBooij
/
php-cache-scheduler
ErikBooij
/
php-cache-scheduler
A tiny library to optimize cache TTLs for when your data will be inherently stale.
This Cache Scheduler is a library that allows you to vary your cache TTLs according to a self defined schedule. I've written a little blog post on why you might want to consider that.
Usage is simple:
-
install it with Composer:
$ composer require erikbooij/cache-scheduler
-
Create a schedule and scheduler:
$schedule = (new Schedule) ->requireUpToDateDataFrom(Schedule::MON, 8, 0) ->allowStaleDataFrom(Schedule::MON, 17, 30) ->requireUpToDateDataFrom(Schedule::TUE, 8, 0) ->allowStaleDataFrom(Schedule::TUE, 17, 30) ->requireUpToDateDataFrom(Schedule::WED, 8, 0) ->allowStaleDataFrom(Schedule::WED, 17, 30) ->requireUpToDateDataFrom(Schedule::THU, 8, 0) ->allowStaleDataFrom(Schedule::THU, 17, 30) ->requireUpToDateDataFrom(Schedule
…
You can use it to create the schedule and calculate the TTL:
// Create the schedule using
// ->requireUpToDateDataFrom(int $dayofTheWeek, int $hour, int $minute)
// ->allowStaleDataFrom(int $dayofTheWeek, int $hour, int $minute)
$schedule = (new Schedule)
->requireUpToDateDataFrom(Schedule::MON, 8, 0)
->allowStaleDataFrom(Schedule::MON, 17, 30)
->requireUpToDateDataFrom(Schedule::TUE, 8, 0)
->allowStaleDataFrom(Schedule::TUE, 17, 30)
->requireUpToDateDataFrom(Schedule::WED, 8, 0)
->allowStaleDataFrom(Schedule::WED, 17, 30)
->requireUpToDateDataFrom(Schedule::THU, 8, 0)
->allowStaleDataFrom(Schedule::THU, 17, 30)
->requireUpToDateDataFrom(Schedule::FRI, 8, 0)
->allowStaleDataFrom(Schedule::FRI, 17, 30);
// Create the scheduler, passing it a SystemClock instance to interface with system time
$scheduler = (new Scheduler(new SystemClock))
->setSchedule($schedule)
->setExpirationSpread(ExpirationSpread::minutes(30));
// Use ->calculateTimeToLive(int $defaultTTL) to get the applicable TTL
$cache->set('cache-key', 'cache-value', $scheduler->calculateTimeToLive(3600));
The schedule and expiration spread can either be attached to the scheduler, for example when you want to provide the cache scheduler from your DI container, or passed to the ->calculateTimeToLive() method if their values depend on the execution location. The latter will override the former if both are used.
Conclusion
With little effort, it might be possible to extend the life of some of your cache entries. This depends on your completely on what data you're caching and how business processes are shaped around it. I'd love to hear your opinions on the idea and the implementation.





Top comments (1)
Rather than using cache times, I've found other approaches to be better suited for my needs at least.
In one system, caches don't expire, ever. Cache hits at this point are nearly 100%. Cache is automatically invalidated once new data is written to the primary database. Cache is stored in Redis. Our ORM is smart enough to pull from cache when it is available, and to update the cache automatically when new content is written though it to the main database. If Redis is ever down or missing the cache data (such as when upgrading Redis instances), the ORM will fall back to the main database automatically and then push the data back into Redis.
Another scheme I have in place is to cache only certain information, and use the cached information to pull live data. One system is an inventory management system with over 10,000,000 SKUs with search queries returning results in real-time while typing (auto-complete). There is a cache table which is highly optimized and indexed for lookup, and nothing more. It contains search fragments and an associated integer key linking to the actual inventory table. Key press auto-complete script queries this fast lookup table and returns a list of integers. These integers are then used as keys to look up live data, and then the live data is returned.
Both of these systems are designed for very fast live-updating of data which can happen anytime 24/7, while using minimal resources.