
Azure SQL DB’s Automatic Tuning will create and drop indexes based on your workloads. It’s easy to enable – just go into your database in the Azure portal, Automatic Tuning, and then turn “on” for create and drop index:
Let’s track what it does, and when. I set up Kendra Little‘s DDL trigger to log index changes, which produces a nice table showing who changed what indexes, when, and how:

I wanted to do that because the documentation is a little hand-wavy about when these changes actually take effect:
You can either manually apply tuning recommendations using the portal or you can let Automatic tuning autonomously apply tuning recommendations for you. The benefits of letting the system autonomously apply tuning recommendations for you is that it automatically validates there exists a positive gain to the workload performance, and if there is no significant performance improvement detected, it will automatically revert the tuning recommendation. Please note that in case of queries affected by tuning recommendations that are not executed frequently, the validation phase can take up to 72 hrs by design.
To give my Azure SQL DB some horsepower to crank through these truly terrible queries, I gave it 8 cores, then fired up SQLQueryStress to run 20 simultaneous queries against it, and let it run for a day.
Setting up my workload
I took the queries from lab 2 in my Mastering Index Tuning class. We start with the Stack Overflow database with every table having a clustered index, but no nonclustered indexes at all. Students run a workload with SQLQueryStress, which populates the missing index DMVs and the plan cache, and then you have to put the pieces together to figure out the right indexes. Needless to say, it’s a Mastering class, and it’s purposely designed with pitfalls: if you rely on Clippy’s missing index recommendations, you’re gonna have a bad time.
I didn’t expect Clippy to be a master by any means – this automatic tuning feature is included with your Azure SQL DB bill at no extra charge. It’s free index tuning. I’m pretty much happy with ANY index improvements when they’re free! It’s a great feature for businesses that can’t afford to have a professional performance tuner hand-craft the finest artisanal indexes. (Also, those folks make mistakes.)
After letting the workload run overnight, here’s what Azure SQL DB’s performance metrics looked like:

100% CPU and 100% IO – for those of you who are new to performance tuning, the idea isn’t to score 100 points out of 100. (At the same time, it’s not to score 0 either, because then you’re overspending on resources.) We definitely need some index help – and good news, sp_BlitzIndex reports lots of opportunities for tuning:
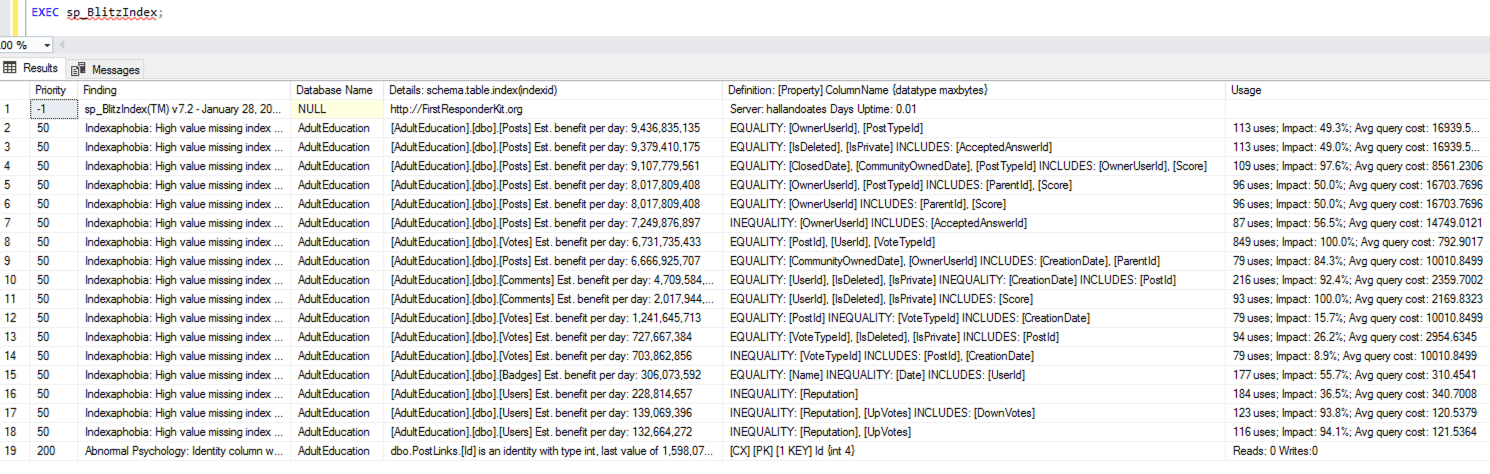
Zooming in a little:
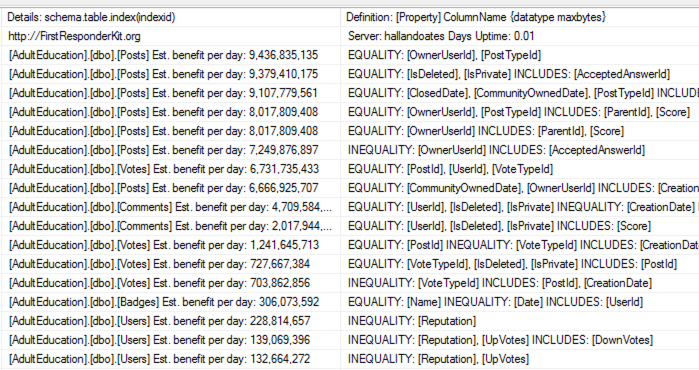
Plenty of opportunities on the Posts, Votes, Comments, Badges, and Users tables.
What did Automatic Tuning PLAN to do?
Over in the Azure portal, you can see what recommendations Automatic Tuning came up with:

I love it! All three of those look like good choices. I’m not disappointed that it only picked indexes on 3 of the 5 tables, nor am I disappointed that it picked so few indexes – I would always much rather have it err on the conservative side. That’s great!
That page in the portal doesn’t show the index includes, but if you drill down a level on each index, the includes are shown:
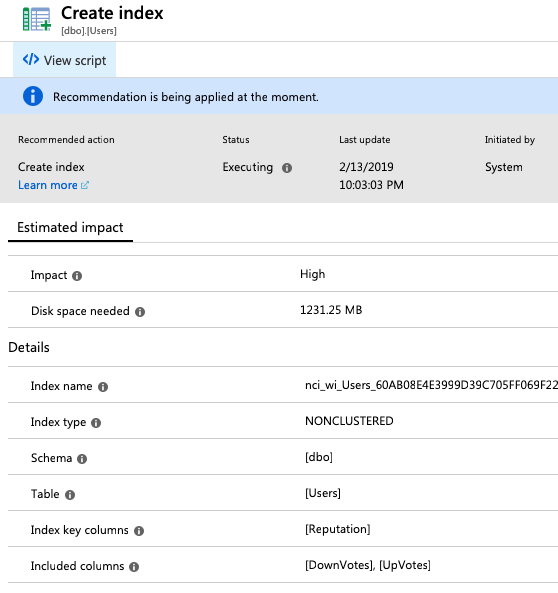
You can even click “View script” to get the creation T-SQL. I do wish they’d name ’em with the fields they’re on, but I understand that might be challenging given that folks may use really long field names. I can live with these names.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE NONCLUSTERED INDEX [nci_wi_Badges_6E3E4E1FB3A8DD0F4201053BD6EA0D5F] ON [dbo].[Badges] ([Name], [Date]) INCLUDE ([UserId]) WITH (ONLINE = ON) CREATE NONCLUSTERED INDEX [nci_wi_Votes_CA77C838AF3A22438365553699CCA079] ON [dbo].[Votes] ([PostId], [VoteTypeId], [UserId]) INCLUDE ([CreationDate]) WITH (ONLINE = ON) CREATE NONCLUSTERED INDEX [nci_wi_Users_60AB08E4E3999D39C705FF069F220FFE] ON [dbo].[Users] ([Reputation]) INCLUDE ([DownVotes], [UpVotes]) WITH (ONLINE = ON) |
The Badges and Users indexes exactly matched the missing index DMVs’ recommendations. However, the Votes index was different, and it’s different in a way that gets me all tingly inside. Here were the missing index recommendations on the Votes table:

And here was the recommendation from Azure:
|
1 2 3 |
CREATE NONCLUSTERED INDEX [nci_wi_Votes_CA77C838AF3A22438365553699CCA079] ON [dbo].[Votes] ([PostId], [VoteTypeId], [UserId]) INCLUDE ([CreationDate]) WITH (ONLINE = ON) |
Azure managed to merge the first two recommendations together in a way that works successfully! Neither of the DMVs had included all 4 of those fields in a single index, but Azure did. Oh, Clippy, I love you, you’ve gone off to boarding school and passed high school chemistry. (Or maybe this is Clippy’s big sister, and I’m falling in love. Look, let’s not get bogged down in this metaphor.)
What did it ACTUALLY do, and when?
The above screenshots imply that this create-index statement is executing right now. The documentation says “Executing” means “The recommendation is being applied.” but that definitely isn’t true: the Users index shows as “Executing” as of 10:03PM, but hours later, the index still wasn’t there, and no create-index scripts were running.
I guessed maybe Azure was waiting for a lull in the load (love it!) so I stopped the load test and waited. About half an hour later, the index on Users magically appeared. I say “magically” because the DDL trace on index creations didn’t capture what Azure did. That is a bit of a bummer because it’ll make tracking what happened just a little bit harder. We’re going to have to use one mechanism (DDL triggers) to track user-modified indexes, and another mechanism to track Azure-modified indexes.
Azure exposes its tuning actions in sys.dm_db_tuning_recommendations:

Buckle up: the state and details columns are…JSON. Here are the example details for an index. <sigh> Developers love JSON because they can change the contents without having to change the database structure – they can just name a column “details” and then stuff it full of hot garbage without any forethought. I know, it’s not normalized stuff like you’re used to with the DMVs, but stay with me – this will come in handy a few paragraphs from now.
I happened to catch one of the indexes as it was being created. Here’s the live query plan in PasteThePlan:

It’s building the index with the Power of Dynamic SQL™. Here’s the query it’s running – it’s parameterized, but I switched the parameters into a declare, and ran it through format-sql.com to make it easier to read:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
DECLARE @sql_exception_autotuning_disabled int, @sql_exception_null_table_name int, @sql_exception_null_index_name int, @schema_name nvarchar(3), @table_name nvarchar(5), @index_name nvarchar(45), @is_online int, @is_auto_created int, @index_field0 nvarchar(6), @index_field1 nvarchar(10), @index_field2 nvarchar(6), @included_field0 nvarchar(12) SET DEADLOCK_PRIORITY LOW; DECLARE @isAutotuningOn SMALLINT; DECLARE @advisor_name NVARCHAR(120) = 'CREATE_INDEX'; DECLARE @exception_msg AS NVARCHAR(MAX); SELECT @isAutotuningOn = actual_state FROM sys.database_automatic_tuning_options WHERE name = @advisor_name; IF (@isAutotuningOn IS NULL OR @isAutotuningOn = 0) BEGIN SET @exception_msg = 'Autotuning is not enabled for advisor ' + @advisor_name; THROW @sql_exception_autotuning_disabled, @exception_msg, 1; END; DECLARE @exception_message AS NVARCHAR(MAX); DECLARE @stmt NVARCHAR(MAX); IF QUOTENAME(@schema_name) IS NULL SET @schema_name = 'dbo'; IF QUOTENAME(@table_name) IS NULL BEGIN SET @exception_message = 'table_name can not be null.'; THROW @sql_exception_null_table_name, @exception_message, 1; END IF QUOTENAME(@index_name) IS NULL BEGIN SET @exception_message = 'index_name can not be null.'; THROW @sql_exception_null_index_name, @exception_message, 1; END SET @stmt = CONVERT(NVARCHAR(MAX), '') + 'CREATE NONCLUSTERED INDEX ' + QUOTENAME(@index_name) + ' ON ' + QUOTENAME(@schema_name) + '.' + QUOTENAME(@table_name) + ' (' + QUOTENAME(@index_field0) + ', ' + QUOTENAME(@index_field1) + ', ' + QUOTENAME(@index_field2) + ') ' + 'INCLUDE (' + QUOTENAME(@included_field0) + ')'; DECLARE @stmt_options NVARCHAR(MAX) = ''; IF @is_online = 1 BEGIN IF @stmt_options <> '' SET @stmt_options = @stmt_options + ', '; SET @stmt_options = @stmt_options + 'ONLINE = ON'; END IF @is_auto_created = 1 BEGIN IF @stmt_options <> '' SET @stmt_options = @stmt_options + ', '; SET @stmt_options = @stmt_options + 'AUTO_CREATED = ON'; END IF @stmt_options <> '' BEGIN SET @stmt = @stmt + ' WITH (' + @stmt_options + ')'; END SET @stmt = @stmt + ';'; EXEC (@stmt); |
Interesting. That means the script you get in the portal isn’t exactly the same index creation script that Microsoft is actually running – note that this one is terminated with a semicolon, for example, but the portal’s version wasn’t.
How did that affect the server while it ran?
Regular readers may recall our recent adventure, How fast can a $21,468/mo Azure SQL DB load data? In that, I kept bumping up against transaction log throughput limits that seemed strangely low, like USB thumb drive slow.
Well, this is only an 8-core (not 80-core) server, so I did expect index creation (which is a write-heavy activity) to bump up against the log limits hard, and it did. Here’s a screenshot of a 60-second sample of sp_BlitzFirst while the Votes index creation was happening:

A few notes:
- Log file growing – this strikes me as really odd because I’d loaded this entire database from scratch recently, going from 0 to 300+ GB. The log file shouldn’t have been small, and there hadn’t been write activity in the last half-hour before the index creations. There should have been plenty of space in the log file – which leads me to think that Microsoft is actually – and I hope you’re sitting down for this – shrinking the log file. For shame. That’s a real bummer, causing customer slowdowns for something that we all know is a terrible anti-pattern.
- CXCONSUMER waits with an average of 467 seconds each? Each?!?
- INSTANCE_LOG_RATE_GOVERNOR – ah, our throttle friend.
- Physical write volumes (bottom of the screenshot) – the 8-core instance was able to write about 2GB of data in 60 seconds. Again, terrible USB thumb drive territory, but…not that much worse than the 80-core instance, which really makes me question what’s happening with the scalability of the IO in Azure SQL DB. (I’ve got a blog post coming up on that, and the short story is that while the documentation says IO scales linearly per-core, it…doesn’t. Not even close.)
After the index creations finished, I fired up my workload again.
How Automatic Tuning validates its changes
After the workload started again, the Azure portal showed the measurements it was taking for each of the indexes:

This Badges index seems to have paid off well with huge DTU savings, although one of my queries regressed. (I’m curious how they’re measuring that given that many of the queries in my workload are joins across multiple tables, 3 of which got new indexes in this last round of index tuning.)
The Users table didn’t fare quite as well, only seeing minor improvements:
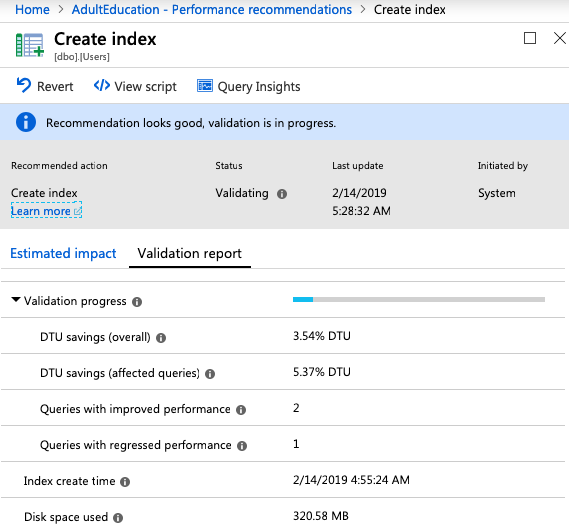
In a perfect world, I’d love to be able to click on “Queries with regressed performance,” see the queries involved, and figure out how to hand craft better indexes for them. Unfortunately, while you can go to Query Insights, you’re left to start over with the filtering, trying to figure out which queries were involved.
The portal doesn’t do that, but…we might be able to, someday. Remember how I said that the JSON data in sys.dm_db_tuning_recommendations would come in handy? Well, for the automatic-plan-forcing part of Azure’s Automatic Tuning, the improved & regressed query plan IDs are stored in the JSON, and Grant Fritchey wrote a query to fetch ’em. There’s no reason Microsoft couldn’t do that same thing with the improved & regressed queries for the automatic index tuning – after all, they made the Details column a generic JSON dumping ground. They could add the query data in there, and here’s a feedback request to make that happen.
About six hours later, 2 of the 3 indexes showed as validated. Here’s the validation for the Votes index:

Note that 2 queries got better, and 1 query got worse – but I can’t tell what that one query is. Again, no drilldown on “Queries with regressed performance,” and the Query Insights tab just takes you to the database’s overall insights, leaving you to start searching from scratch. Sure would be nice to have this here feature.
Summary: I love it.
Things I love:
- It’s conservative
- It’s doing deduplication, merging recommendations together
- It’s not trying to apply the indexes during peak loads
- It does a way better job of validating its changes than most DBAs
Things I don’t mind:
- The execution scheduling is opaque
- The index names aren’t great
- The indexes take a long time to apply (but that’s an Azure SQL DB storage limitation, apparently)
Things I don’t like:
- The validation report doesn’t show me which queries got worse or better (and I know Azure knows)
This feature is really appealing for the classic use case of a database server that doesn’t get any tender loving care from a database administrator. I’m sure the deeper I look at it, the more edge cases I’ll find, but…who cares? I have that same feeling about Clippy’s missing index recommendations, but I still rely on those every day as a starting point when I parachute into a new server. Used wisely, they can help you do a better job of tuning and let you focus more on the hard edge cases.

24 Comments. Leave new
I’d like to see Clippy (I guess if this is Clippy’s sister then Clippette?) notice that a unique index is already on one of the columns and to create any indexes that are going to have that column as unique as well. I realize that’s too much work for Clippy to do at runtime but I would think all the power and time at the disposal of Clippette should allow for it, right?
Automatic Tuning (Create Indexes) can recommend creating an index to improve performance of a statement or stored procedure that should instead be restructured to provide a much bigger performance boost than the index would. The recommended index may make the statement fast enough to drop off lists of “Top SQL”, depriving a DBA of the visibility that a performance improvement opportunity remains. One specific example is a view that is referenced without a NOEXPAND hint, which may cause Automatic Tuning (Create Indexes) to create an index on a base table, whereas if the hint was added to the affected statement, there would be a greater performance improvement without creating an additional index.
Automatic Tuning (Create Indexes) can hide code bugs. Consider the case where there is a compound foreign key (Col1, Col2), but a statement joins the two tables together using only one of the key columns (Col2) in the ON clause. This is a bug that will cause too many rows to be returned. Automatic Tuning (Create Indexes) will recommend adding an index on Col2. That will make the incorrect statement execute faster (by turning a scan into a seek), and therefore it will no longer appear in lists of “Top SQL” so it may never be found (until someone happens to notice the incorrect result).
Automatic Tuning (Create Indexes) can create overlapping indexes that differ only by the choice of include columns or additional trailing key columns. These can unnecessarily slow down insert, update, and delete statements, consume more disk space, and take up cache memory better used by something else. (To be fair, it may eventually recommend that the original index be dropped, but that isn’t a certainty if there is a statement that can be satisfied by using that original index or if the include columns in the original differ from those in the recommended one.) In many such cases, it is better to combine the existing index with the one being recommended into one new index to replace the original. It is a good thing that this feature doesn’t automatically modify indexes that it didn’t create, but work must be done to ensure that INSERT, UPDATE, and DELETE performance doesn’t suffer from having unnecessary overlapping indexes.
Mark – yes, I agree about all of those, but make sure to read the summary, especially the last paragraph. That first sentence in the last paragraph is super important. Thanks!
I agree. For a shop without a good performance tuning specialist, this is a great feature. I just wouldn’t want some manager thinking it was a good substitute for one. 🙂
I agree with this. Automatically creating indexing is like we are blindly creating indexes without researching on teh underlying queries. In most of the cases indexes suggested by SQL server are not needed, we can tune queries just by tweaking them.
Now I know what the first horse must have felt like when it saw a Model T on the road.
LOL
Brent’s last paragraph is applicable though. If this feature is eventually able to make perfect indexes 99.9% of the time based on queries in the system, it’s still not going to replace a DBA that looks at the underlying bad queries and stored procs and architectural changes, and by the time they get the AI able to pass a Turing test AND explain to the devs or managers or users why it’s a really bad idea to {insert latest asinine trending idea here} you and I will both be dead and/or retired.
Brent, will you be submitting a feedback item for the non-scaling IO performance of those Azure instances?
Jeff – no, I haven’t had a lot of success with the feedback infrastructure. It’s frankly felt like a waste of my time.
I understand your feelings on the matter. I was hoping that maybe an MVP might throw a little more weight than say someone like myself. I did make sure to add 3 votes to your tagged feedback item. It would be a nice addition.
Ah, I gave up my MVP status a couple of years ago. Time to pass the mantle on to someone else.
Doh! Sorry.
Totally okay! That was part of the decision process – I figured nobody really cared whether I was an MVP or not, heh, and I’d put the same amount of work in whether Microsoft thanked me or not. I do what I do for the readers, not for an award. Y’all are reward enough!
Hi as usual Great tests and great post.
1 thing that is Big NO GO for me is the compression. why do not they created it already compressed? in a world of sizing and 1 TB max size we need them compressed
Maybe they’re dedupping and compressing on the storage level, though.
Hang on, the index creation is not caught by a DDL trigger?! This just feels so wrong, I feel violated LOL.
I would love to use Automatic Index Tuning but all our environments are using CI/CD (which is a GREAT thing!). So if we turn on this feature in production and it applies indexes and these indexes are not already in source control (which they won’t be), the next time we do an automatic deploy, it will DROP the indexes in production. I am sure there is a way to automate backward applying and trigger a code check in with GIT but not sure how involved/worth it would be.
Jason – it sounds like your CI/CD process might need to be modified to ignore nonclustered indexes, perhaps? I could make an argument that in some shops, the developers’ job is to do the clustered index design, but to leave the nonclustered index design to the performance tuning side after going live. (It’s certainly not true everywhere, but I’ve worked with shops where that’s the case.)
I’ve also worked in environments where the production indexes like that are never backported to source control, either.
I agree. Similarly, indexes dropped by Automatic Tuning (Drop indexes) can be recreated during such deployments. While it is likely possible to exclude nonclustered indexes as Brent mentioned, it may be a project policy to ensure the environments are kept identical in that respect as well. While this may not be a technical issue, it may well be an “above our pay grade” issue.
Even when that is not the case, having various environments (Development, Test, Acceptance, Load Test, Stage, Production, etc.) potentially all having different indexes can result in reports of application slowness that cannot be replicated in a “lower” environment – even if the data is a sanitized copy of production running on identical hardware.
In some companies, a change request needs to be submitted and approved before making a schema change to a database in production or even acceptance testing or staging. For some third-party databases, assurance may need to be obtained from the vendor/publisher that the new index(es) won’t cause them to refuse to provide support and won’t interfere with their version update scripts in the future.
So there can be many reasons why automatically applying these recommendations may not be a good idea (or permitted at all) in any given environment. But I sure find the recommendations themselves to be very useful.
I DO have to keep all environments in sync. I will say we do have exceptions. For example we have a “working” schema for tables and stored procedures that we use in ANY environment for troubleshooting that gets ignored via a filter file so they do not get dropped (Indexes are not one of them 🙂 ). I agree that the recommendations are VERY helpful and can be used to then create in Dev and promote up through the chain. We could automate getting an exception report weekly to review production missing indexes and create as needed.
Very impressive indeed!
So, how soon should I be worrying about re-qualification?
We have enabled this functionality in our test environment and it seems to work as designed but we have 1 problem. We are also working with devops and a release pipeline (Ci/Cd). But the newly added triggers are deleted when we do a new deployment from master. We have tested settings with sqlpackage and publish scripts but we have 2 use cases: we want to retain the indexes added by automatic tuning and we want to remove objects what are not any more in the master. For the users there is an option to not drop the users what are in the target. But for the indexes there isn’t anybody had the same issue and solved this?
I’m considering turning this on for some of our new applications, tho I’m worried about how it’ll handle primary keys if you allow Clippy to drop indexes. Is there any documentation to say that it WONT drop existing PK’s? (I’m going to keep on googling and see if something pops up)
I wish you could tell it to ignore certain tables as we know that some tables we want to leave alone, while others we dont mind if they get tuned… Love this article tho, it gives me a lot more confidence with the magical Clippy!