
Update March 19: Microsoft has since acknowledged a hidden limit, then documented it, then raised it – but it’s still disappointingly slow.
In my last post, I explored how fast a $5,436/mo Azure SQL DB Hyperscale could load data. I’d had a client who was curious about spinning up their dev environment up there to see how query plans might look different. Well, as long as I was running this test, I thought – “How does this compare with Azure SQL DB?”
There are 3 different products with similar names: Azure SQL DB, Managed Instances, and Hyperscale. In this post, I’m specifically talking about Azure SQL DB – not Managed Instances or Hyperscale. Managed Instances have a way easier method to ingest data – simply restore a database backup – so that one isn’t really worth exploring. There are a bunch of similar restore-a-backup requests for features to make restores easier in Azure SQL DB, they don’t exist today, so we’re stuck with the same options we had with Hyperscale:
- Offline: use the Data Migration Assistant (also, useful white paper)
- Offline: generate a BACPAC, and then import the BACPAC in Azure SQL DB
- Online: set up transactional replication to keep the two in sync, and then cut over
- Offline (for a SQL Server source): Azure Database Migration Service
To do this quickly and easily, I went with the first option (as I did in the last post with Hyperscale.)
Attempt #1: 80 cores, $20,088 per month.
The Data Migration Assistant and its documentation strongly suggest that you shouldn’t start small: you should over-provision your Azure SQL DB during the migration process:

That seems fair – a P15 is 4,000 DTUs and up to 4TB storage. I was using the new Business Critical vCore model, though, so I maxed it out at 80 cores, 408GB RAM, $20,088 per month:
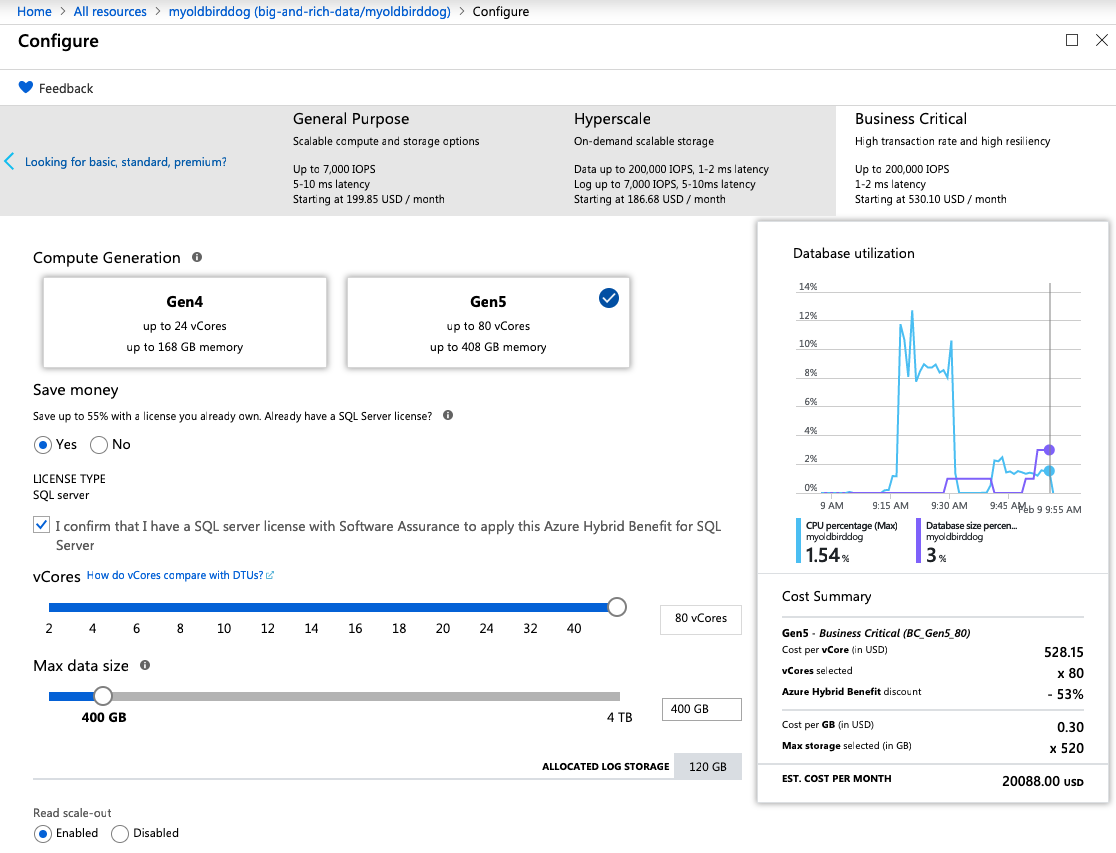
Note that it sys up to 200,000 IOPs, 1-2ms latency – that sounds like a pretty good target for data ingestion. Nothing in the wizard (or the documentation that I could find) seemed to tie data size to storage throughput – which is surprising, because I’ve seen that kind of relationship all over the cloud – but since it wasn’t mentioned, I just left it at 400GB (my database is 340GB.)
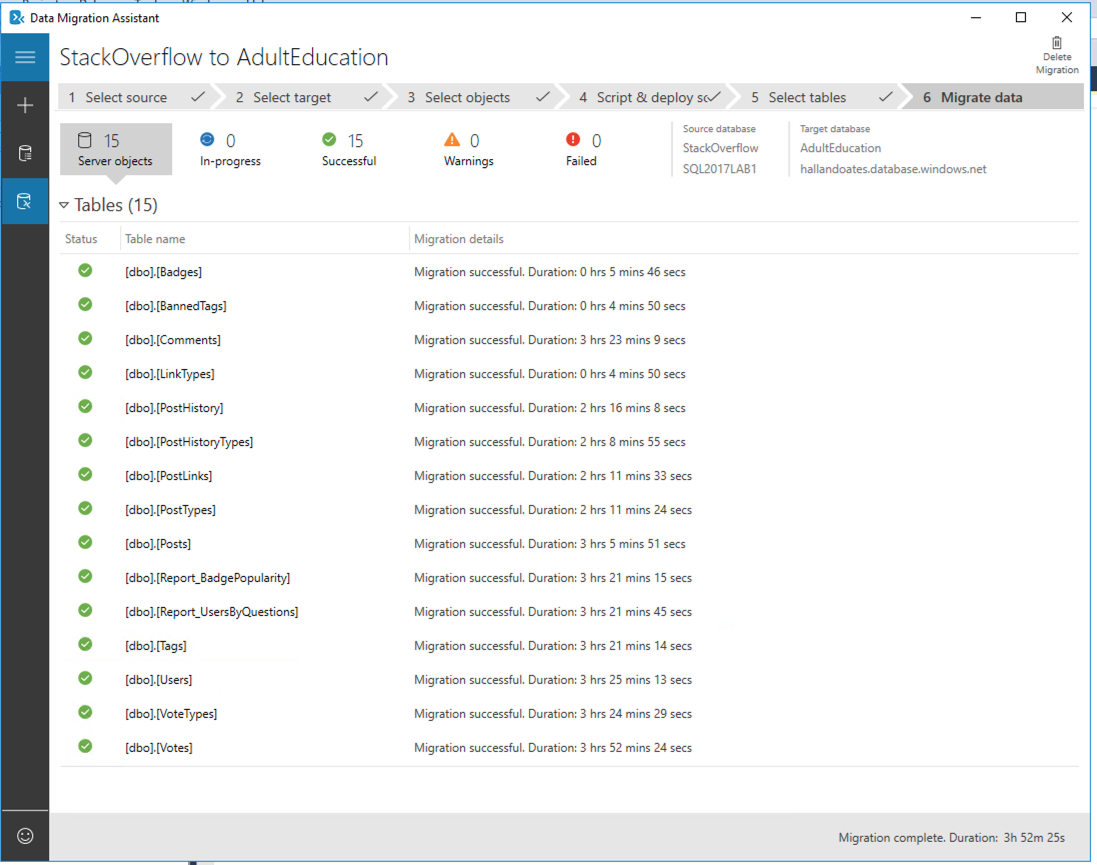
I fired up the Data Migration Assistant and let ‘er rip:

You can’t read anything into the time numbers on this screenshot compared to the last post because the Data Migration Assistant doesn’t load tables in the same predictable order every time, and the times represent the point-in-time in the total load at which the table completed.
Why couldn’t it go faster? sp_BlitzFirst makes it easy to find out:

Note the “Database is Maxed Out” lines at the bottom, and in the details at the far right, we were bumping up against the max allowed log write percent. Ouch. The Azure portal showed writes maxing out too:
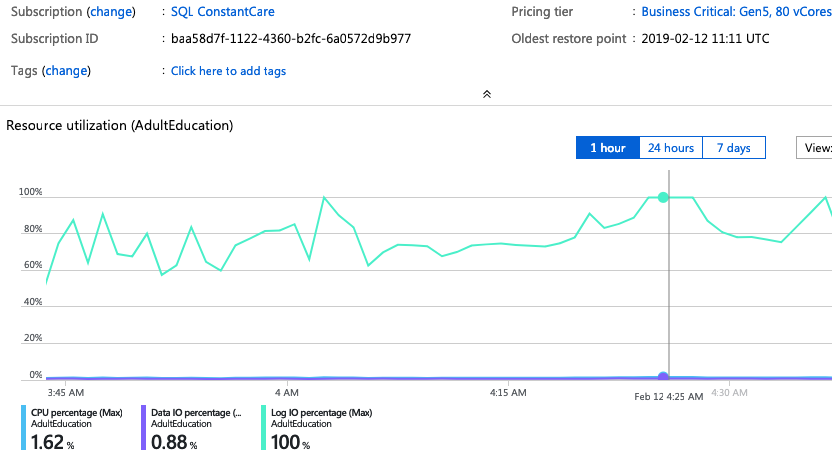
Well, that was disappointing. (Note that in these screenshots, you’ll see server & database names switch around – that’s because I tried these tests with several different servers and instances in the hopes of getting past the log throughput limits.)
Attempt #2: 80 cores, 4TB storage, $21,468 per month
In the Azure portal provisioning wizard, I only had one remaining slider, and I cranked it as far to the right as I would go, upsizing my storage to 4TB (even though I only needed 340GB for the database) – hoping it would upsize my log rate throughput:

One of the awesome things about the cloud is that you can make these kinds of changes on the fly, and sure enough, it took less than 3 minutes for Azure to report that my storage upsize was complete.
Except I was still banging up against the log rate governor:

There are several interesting things to note in that screenshot:
- At the time of this screenshot, queries are waiting on writelog waits (but you can’t rely on point-in-time checks of individual queries)
- I’m hitting my DTU limits, and I’m getting poison LOG_RATE_GOVERNOR waits
- I’m averaging 96.85% of my allowed log throughput – not peaking at, but averaging
- Log backups are happening at the same time, which is probably also affecting my log rate throughput, but I can’t blame Microsoft for taking log backups
- In a 60-second sample, 4GB of data was read from the logs (most likely the log backups)
- In that same sample, 1.6GB was written to the data file, and 1.7GB to the log file, and averaged a nice and tidy zero milliseconds for the log file writes (very nice) – but in 60 seconds, that’s a only 28 megabytes of data per second to the log file. That’s USB thumb drive territory.
Eventually, it finished in 3 hours, 52 minutes – remarkably similar to the Hyperscale speeds:
And at first you’re probably saying, “Well, Brent, that means you’re bottlenecked by the source. Both Hyperscale and Azure SQL DB had the same ingestion speeds, and they have something in common: your data source.” That’s what I thought too, so…
Attempt #3: synthetic local loads
Just in case there was a problem with something with my Azure SQL DB instance, I blew it away and started again from scratch. I also took the Data Migration Assistant and networking completely out of the equation. I created a new 80-core Azure SQL DB, maxed out on storage, and loaded a table with junk contents from sys.messages – this way, I didn’t have to worry about any cross-server communication at all:
|
1 2 3 4 |
SELECT m.* INTO dbo.Incoming1 FROM sys.messages m CROSS JOIN sys.all_columns ac; |
Waits while that happens:

We’re not hitting the log rate governor, but we might as well be. In any given 60-second sample, we waited for hundreds of log file growths, and we managed to write less than 2GB to the log file. 30MB/sec of write throughput is simply terrible – even if we’re growing out a 2GB log file, that’s just terrible for $21,468 per month. You really could do better with a USB thumb drive.
To really stress things out, I started 8 sessions all running that same insert query (with different table names.) I started hitting the log rate governor again, while still only writing about 1.5GB per minute:

And then all of a sudden, my wait stats dropped to nothing! Things were flying, because…uh…wait a minute…
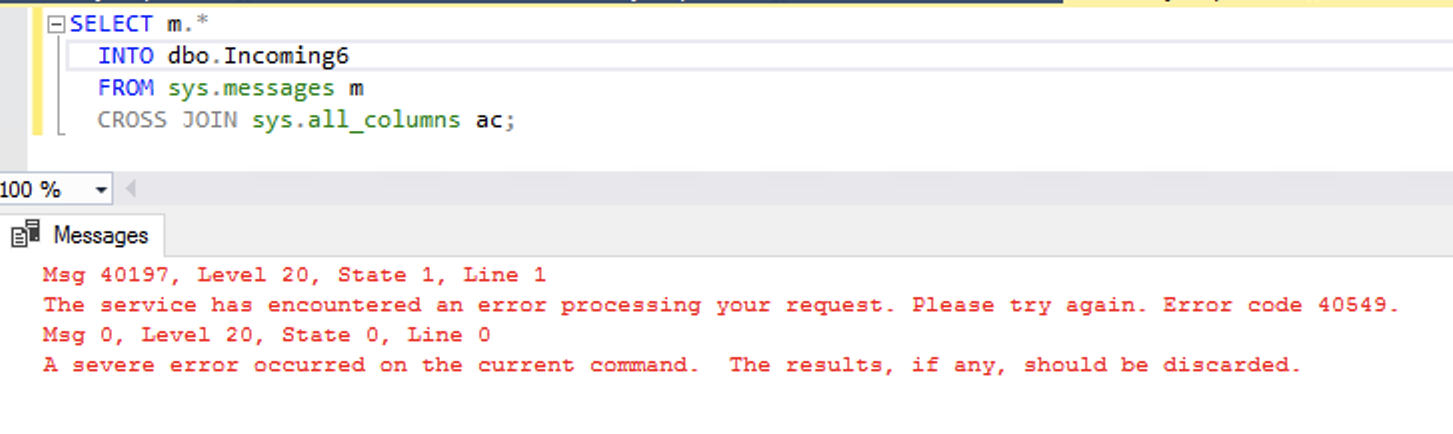
Huh. All my queries had crashed at once. That’s not good, and I’d dig deeper to do a repro query, but…the beach is calling.
They left the database in a bit of an odd state, too – the tables were there, with pages allocated, but no rows, indicating they’d all rolled back:
 j
jThat’s…not ideal.
Summary: Azure SQL DB’s log throughput
seems kinda slow for $21,468 per month.

You measure storage with 3 numbers:
- How many operations you can perform (often abbreviated as IOPs)
- The size of each operation (operations * size = total throughput, usually measured in MB/sec or GB/sec)
- Latency of each operation (how long individual operations take to complete)
The latency was great – fast and predictable – but the log rate governor is capping throughput. It means you can’t do too many things at once – but boy, those few things you can do, they sure are fast. Having reliably low-latency operations is great for day-to-day transactional workloads that only do a few writes per user transaction, but…for data ingestion, it makes for slow going.
For imports, I really wish Azure SQL DB would have a mode to let you temporarily optimize for ingestion throughput rather than low latency. I don’t need sub-millisecond latency when I’m dealing with insert commands coming from another machine (especially less-than-optimized commands like the ones from Data Migration Assistant, which even ran into blocking problems during my loads, blocking themselves across threads.)
Have any of you migrated a sizable database (at least 100GB) into Azure SQL DB? If so, did you measure how long it took, like how many GB per hour you were able to import? Any tricks you found to work around the log rate governor?
Update March 9: Microsoft
acknowledged & documented the limit.
Microsoft contacted me, agreed that there’s a limit, and that it wasn’t documented for the public. They’ve now updated a few pages:
- Single database limits – now shows the transaction log is limited 20 MBps for General Purpose, and 48 MBps for Business Critical.
- Those limits are reached at 8 cores for GP and BC Gen4, and 16 cores for BC Gen 5.
- Log limit workarounds – like load data into TempDB or use a clustered columnstore index for compression.
Ouch. 48 MBps really is bad, especially at $21,468 per month. This is such a great example of understanding the limitations of a product before you make that leap.
Update March 19: Microsoft raised the limit.
Within a few days of documenting the limit, Microsoft must have realized that it was just set entirely too low, and quietly raised it:
Looks like your Investigation got them to bump up the Limits, bravo https://t.co/5hU9fRJeKf https://t.co/PWDeQSmGhm although not as much as one would hope…
— Robin Sue (@Suchtiman) March 19, 2019
It’s twice as high now – 96 MB/sec – but…still uncompetitive with modern USB 3.0 thumb drives. Good to see that it’s moving in the right direction.

30 Comments. Leave new
I have been working with the Azure team on this same issue recently. FIrst, there is an issue with SELECT INTO and INSERT – if you dont add OPTION (MAXDOP 1), it will try to run it in parallel which isn’t working on Gen5 right now (ping me offline if you want to know why). Adding MAXDOP 1 to my parallel inserts and select into queries reduced insert times by 90%. Also, this isn’t published, but on Gen5, you get 3 MB/s log I/O throughput per vCore. It is 6 MB/s on Gen4. So, you get twice the I/O throughput at the same level with Gen4, which makes sense since Gen4_8 is 8 physical cpus, while Gen5_8 is 4 physical, 8 logical cpus. The reason for limiting log I/O throughput, as explained to me, is that if they increased that I/O throughput they cannot guarantee the 5 minute log shipping jobs could keep up with the transactional load.
Ooo, that’s very interesting! Will email you. Thanks!
Just to clarify – changing the parallel inserts to MAXDOP 1 obviously means that we’re not getting parallel inserts. In testing on the DTU 500 model a few months ago with different MAXDOP options, using MAXDOP 8 was twice as fast to do inserts as MAXDOP 1 was.
Brent, these migration speed tests are a great resource! Thank you!
Fantastic article and information! I’ve been trying to figure out why our ETL loads into Azure SQL dBs are as slow as they are. I believe this is exactly what we’re running into.
Thanks again, Brent, for all the great information!
You’re welcome folks! Glad I could help.
Oh yeah, ETL (and data warehousing) are a lot slower in Azure SQL DB than on-premises. In Azure SQL DB, you cannot switch off the full recovery model, so you’re stuck on the log file throughput. The “work around” is to use memory-optimized staging tables. Which are only available in the Premium edition. No thanks.
Yeah, the surprising part is just how slow the log file throughput is: that’s single-magnetic-hard-drive territory circa ten years ago.
A year ago I migrated a small on-premises ETL solution (in SSIS) from our local server (hardly faster than my laptop) to Azure, using an Azure SQL DB. The ETL runtime went from 10 minutes to an hour. Then I kicked the administrator and said he had to bump the Azure SQL DB from S0 to S4. Now it runs in about 20 minutes. Maybe it was wrong for me to assume that the S-tier can performance faster than a small server.
Koen, what do you mean by S0 and S4?
Are they Azure Storage types?
Cool! Goes back to the old saying you sometimes don’t get all you are paying for. Once again a DBA is needed (MAXDOP = 1) to resolve (most of) the issue.
I haven’t benchmarked this yet, but I’ve been loading data in to Azure by writing .Net code that uses SqlBulkCopy to push data. From looking at the cache in the AzureDB, it’s running an INSERT BULK statement. I do know I’ve heard other people complain that data ingestion is slow, but I haven’t really had that issue with the .Net export. Obviously, the downside is that your target table needs to exist for this to work. I have bits and pieces of code lying around that generate DDL create statements from the schema. A careful application of reading source structure to create and then copy the tables would be easy enough to do.
Just curious, does the wizard chunk up the tables into batches? That’s probably the one thing that saves the performance on the SqlBulkCopy. I’ve got the batch size set to 5000 records. I haven’t really needed to play around with that value, but Azure seems to respond well enough.
Steve – yeah, it chunks them up into batches and runs them simultaneously across 4 sessions.
Nice article, I am using .Net App using bulk copy from one Azure sql DB to another, a simple select from table with 600k records taking more than 5 min, what would be the correct batch size for fast loads and inserts, thank you
For personal advice on your application, click Consulting at the top of the screen.
@brent, Azure allows you to promote a traditional DTU database to Hyperscale. How long does it take to migrate that 340gb database from tranditional PaaS hosting to Hyperscale; given the different storage structure, that should run as fast as the databases can rewrite the data without any artificial limits.
Andrew – not exactly. Click on the very first link in the article. I tested Hyperscale’s load speeds in the previous post.
Amazing thanks for that
Did you try P15 service tier from regular premium Tiers?
I am working with Huge data setes but only in Premium tiers – also not migration to…. but only writes or small bulks
Pini – no. If you’re using them, you should totally give that a shot and blog or share your experiences.
Hi
So here you go:
http://www.sqlazure.co.il/2019/03/azure-sql-db-tiers-comparison.html
Brent – After seeing your past 2 articles, I have grown curious about how AWS and Google Cloud handles the same problem and how much it would cost for comparable services verses Azure. Are you planning such a test? I ask only because I am interested in comparing results.
Jeff – great question! No, right now both Azure SQL DB and Azure SQL DB Hyperscale are products that no other cloud offers. The other providers offer different solutions with different pros & cons.
Amazon offers RDS SQL Server, which is kinda like Azure SQL DB, but much more flexible since you can have up to ~30 databases per server, do cross-database queries, choose whether you want the overhead of writing to an additional replica, etc. However, it doesn’t offer readable replicas, nor does it offer the cool new auto-tuning features of Azure SQL DB. I don’t see it as better or worse – it’s just different.
Google doesn’t have a SQL Server database-as-a-service offering, only traditional VMs (IaaS), so comparing them isn’t really fair. AWS offers that same thing too (EC2), as does Azure (Azure VMs.) In the tests above, all 3 (AWS EC2, Azure VMs, and Google Compute Engine) would totally smoke Azure SQL DB’s ingestion rate (and have a lower price to boot) if you choose the appropriate VM types, but they come with the drawback of higher maintenance costs, since you have to manage those yourself.
Compare to on-prem,
then ill get 10000 feet close enough to recommending Azure as a Database
GW – you know it’s funny, I was going to do that (using a VM with local PCIe NVMe storage), and then ran out of time. I’d love to see someone write that post though.
[…] Brent Ozar: Azure SQL DB’s log throughput seems kinda slow for $21,468 per month. […]
[…] Brent Ozar: Azure SQL DB’s log throughput seems kinda slow for $21,468 per month. […]
[…] Brent Ozar heeft hier onderzoek naar gedaan: https://www.brentozar.com/archive/2019/02/how-fast-can-a-21468-mo-azure-sql-db-load-data/ […]
Thank you for pushing Microsoft to up their game!
No, no, no, wait a sec… Microsoft suggests Azure ExpressRoute when migrating SQL Server to Azure SQL Database but then limits the transaction to 96 MB/sec.
So I’m buying ExpressRoute for nothing, right?
Wow! Thanks Brent for saving our asses! There’s no way we could have run such tests ourselves. I mean 20+ grand a month!? WTF!?
It would be interesting to know how Amazon RDS compares to this, because these two (AWS and Azure) have been feuding over which is cheaper and more performant at the same time, regarding hosting SQL Server databases, for a while now. It seems to me like what AWS has been saying about Azure… is not far from the truth.