

This is a guest post from Shaun Elliott, Data Engineering Tech Lead and Sam Shuster, Staff Engineer at Edmunds.
What is Databricks and How is it Useful for Edmunds?
Databricks is a cloud-based, fully managed, big data and analytics processing platform that leverages Apache SparkTM and the JVM. The big selling point of the Databricks Unified Analytics Platform is that it unifies Big Data and Machine Learning.
Databricks lowers the barrier to entry and/or time needed to work with large quantities of data in several ways:
- Databricks Notebooks
- Cluster and Job Creation
- Polyglot Programming
Finally, Databricks is operated by active Apache Spark committers including many of the original creators. Because of this, Edmunds gets access to not only excellent Spark support, but also the newest versions and features that the framework has to offer.
Databricks Notebooks
Databricks notebooks are similar to Jupyter notebooks and are essentially a REPL with a nice Web UI for Spark. They allow for quick development cycles, interactive testing of code, and even visualizations of datasets in the terabyte (or beyond!) range. The code is programmed via a Web UI or you can run jars or eggs from an IDE (Note: The promise of directly connecting to an IDE is in the works through a feature called Databricks Connect which is currently in private preview). With the recent advances to make notebooks the standard in a data engineering org, we are excited to see what the possibilities are with a “notebook first” approach.
Easy Cluster and Job Creation
Databricks has an easy to use interface for creating clusters to run both interactive and scheduled jobs. This eliminates many operational hurdles of our in-house ticket system making a request that could easily days only take a matter of minutes. Other solutions, like EMR, are moving in this direction as well via the Amazon Console, but they still have a long way to go before they are as easy to use as Databricks. A big part of this is Databricks’ better UI experience which allows users without much software background to quickly hit the ground running on their own Spark cluster. It even provides easy to configure auto-scaling and auto-termination so precious dollars can be saved. Another benefit unique to Databricks is that they can offer the most up to date version of Spark as well as superior Spark support and tuning. As a company, we strive to write all new data engineering projects using the Spark framework, so this is a key consideration for us.
Polyglot Programming
Databricks gives the freedom to choose from five popular programming languages in order to achieve results (Note, using Java is in JAR form only). Languages supported in notebooks include Scala, Python, R, SQL, and Markdown. This opens up access to people from a wide swathe of backgrounds. No longer must you be a Scala or Java expert with experience in distributed programming to develop a scalable job.
Evolving on Databricks
As with most software stacks, software engineers require a set of tools, libraries, and processes that allow them to follow software-engineering best practices. We are no different and need solid ways of developing and deploying productionalized code to the Databricks runtime environment. So, why not build such a system up front? When we introduced Databricks at Edmunds, we focused on allowing for easy adoption of the framework to persuade users that Databricks could play an important role in their work. This meant that there was an emphasis on achieving the fastest velocities possible.
You are probably wondering why we would want to institute policies that could potentially take away from fast velocities which are consistently viewed as one of the most important factors of a company’s technological health. As with almost all things in technology, there are trade-offs to consider. Having absolutely no operative checks and few standards to our Databricks environment meant that every project that was deployed to Databricks on production became technical debt. This debt adds up over time and lowers the velocity of both the team’s deployment cycle but also of all users of Databricks as well. We needed to address requirements across four categories:
- Environment Standards
- Track down productionalized jobs easily with job names
- Make transparent S3 data location or table location to easily determine which tables were productionalized
- Ensure testing occurred in QA and not in PRODUCTION
- Source Control
- Ensure the code was written in a way that is easy to maintain by a team of engineers.
- Establish a means to perform unit-testing
- Architecture and Libraries
- Establish specific standards around jobs creation to further streamline the creation and maintenance of a Databricks jobs.
- Operations
- Establish a process to review cluster creation
- Extend methods of “Deployment” to Production beyond scheduling notebooks
So What Did We Build?
First, I want to call out that we were not the first team to try and solve this problem. Our advertising solutions team had already developed a strong Python solution. This includes scripts for syncing notebooks to and from Databricks, as well as a standardized workspace layout that allows for logical separation of workflows such as services, configuration management, and local dev testing. We referred to this process when creating our framework for JVM projects.
The goal of this project was to extend our capabilities on Databricks as well as also accommodate the following additional requirements:
- Ideally, the framework could be used by both JVM language projects and non-JVM language projects
- Ideally, the framework would handle both non-notebook and notebook projects
- Use existing tools that are used widely at the company wherever possible (such as Maven, Kingpin [our internal deployment UI], and Jenkins)
Here is what we built:
- Java REST Client (OSS!)
- We opted to only implement functions and resources that we needed for our build system, but built a codebase that allows for additional functionality. We implemented functions for:
- Cluster resource
- Dbfs resource
- Job resource
- Library resource
- Workspace resource
- We opted to only implement functions and resources that we needed for our build system, but built a codebase that allows for additional functionality. We implemented functions for:
- Maven Plugin (OSS!)
- Can upload code to s3
- Can attach/detach library to cluster
- Smart enough to restart a cluster, as needed.
- Can create/edit a databricks job
- Uses a template model, that allows variable injection as well as smart defaults.
- Can start/stop a databricks job
- Can export/import notebooks
- Can validate certain job properties to make sure they follow standards
- Databricks Common Library (Closed source)
- Can obtain both application and environment specific runtime properties via different sources
- Can emit Wavefront metrics
- Can submit and monitor a Databricks job via Oozie
- Kingpin [our internal deployment UI] Integration (Closed source)
- Can deploy a specific version of a databricks job via Kingpin
What does it roughly look Like?
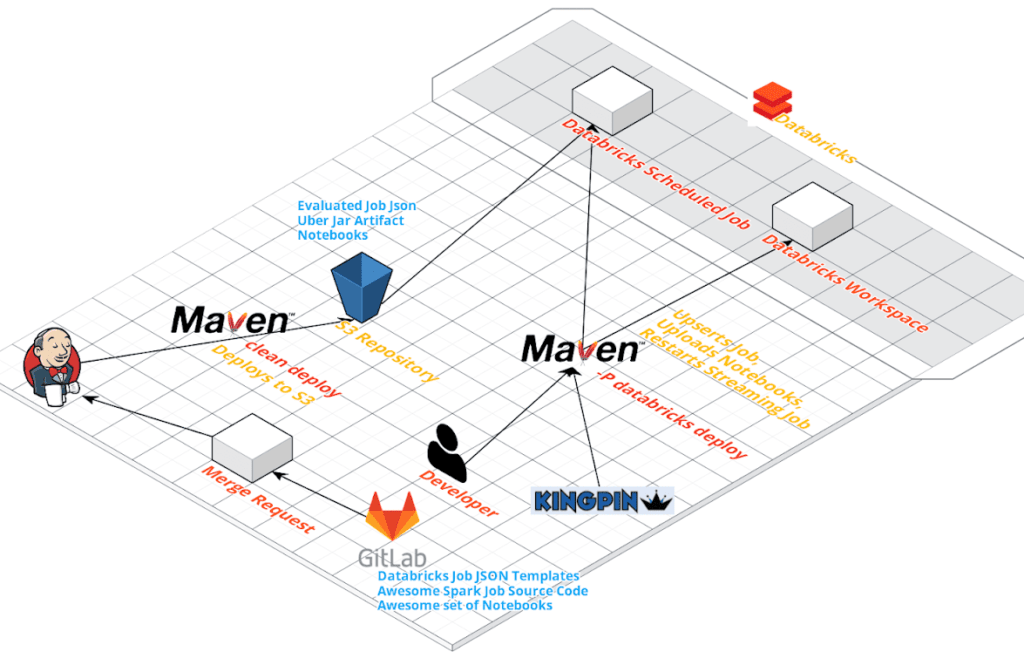
High Level What This Delivers for Us?
- Environment Standards
- Maven Plugin validates Job Names to track productionalized jobs
- Maven Plugin helps us to segment QA/PROD into respective Databricks instances
- Source Control
- All code (including both non-notebook and notebook sources) must be put into a Git repository.
- Architecture and Libraries
- Established additional standards when it came to creating and maintaining Databricks jobs
- Operations
- Cluster creation was manually done and was not reviewed
- Established a code review process by creating Cluster Descriptions as part of a gitlab project.
- Clusters/Jobs are created automatically via the plugin
- “Deployment” to Production was just manually editing Notebooks
- Automated deployment to production in a more reproducible manner via Jenkins/Kingpin
- Cluster creation was manually done and was not reviewed
Why did we open source the REST client and Maven Plugin?
At Edmunds, we believe in open source technology. Contributing what we’ve done will hopefully allow others to improve how they work with Databricks, and we hope contributors will return the favor. Are you interested? Submit pull requests to one of the “good first issues”, here.
Are you interested in solving big data problems or building tools to empower software engineers and data scientists? If so, check out our open positions!
Future Work
Interactive Cluster Management - we plan on adding functions to our maven-plugin to accommodate users who want to automate the management of interactive clusters and codify their creation.
- Environment Properties and Common Library - we plan on making these libraries, developed for internal use, more general so we can open source this work.
- Databricks Maven Plugin API Cleanup - currently the API has some organic growing pains and is inconsistent in how it is designed. One of our goals for a 2.0.0 release will be to make the api more user friendly.
- Moving to Notebook First - this is an ambitious goal that would seek to make Notebooks the entry point for all jobs. Libraries in the form of Python eggs and Scala jars would still be used to contain common functionality, but all job-specific code would be contained in a notebook. Integrating our workflow with Databricks Connect would enable development of notebooks to be much easier and eliminate the need to spend energy on syncing local notebook code with Databricks. Instead, time could be spent on integration tests as part of the deployment pipeline for notebook jobs.