
The more SQL Server knows about your data, the better your query plans can get.
Say you’ve got an app that’s designed to store multiple companies in a single database – but you don’t actually use it that way. All of the data in a given database is actually for the same company.
We’ll use the Stack Overflow 2010 (10GB) database as an example – say the Posts table (questions & answers) has a CompanyCode column that would let us store multiple companies in there. Here’s the setup script. The end result is a Posts_MultiTenant table with a leading field called CompanyCode, and all of the rows have ‘BOU’ as our company:

All of our app’s queries have CompanyCode in their WHERE clauses – even though that doesn’t really do any filtering, but the app is a 3rd party app that always filters for just the company you’re logged into:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
SELECT Id FROM dbo.Posts_MultiTenant WHERE OwnerUserId = 26837 AND PostTypeId = 1 AND CompanyCode = 'BOU'; SELECT Id FROM dbo.Posts_MultiTenant WHERE PostTypeId = 3 AND LastEditorUserId = 15639 AND CompanyCode = 'BOU'; SELECT TOP 100 Id FROM dbo.Posts_MultiTenant WHERE LastActivityDate >= '2018-08-01' AND CompanyCode = 'BOU' ORDER BY FavoriteCount DESC; |
Their actual execution plans get missing index requests, which at first seems like a good thing:
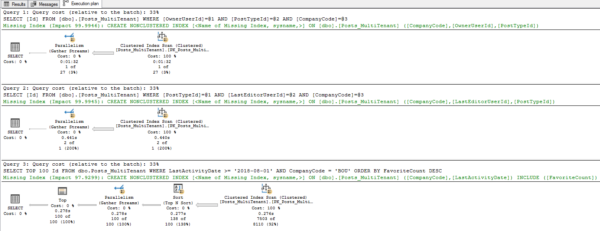
Until you read the missing index requests:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Posts_MultiTenant] ([CompanyCode],[OwnerUserId],[PostTypeId]) GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Posts_MultiTenant] ([CompanyCode],[LastEditorUserId],[PostTypeId]) GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Posts_MultiTenant] ([CompanyCode],[LastActivityDate]) INCLUDE ([FavoriteCount]) GO |
They all lead with the least useful field because CompanyCode happened to be one of the first fields in our table – that’s how missing indexes are generated, based on field order.
That creates a few different problems:
- The indexes are larger than necessary (since they include a useless field)
- The statistics are nearly worthless (since they’re based on a leading field that isn’t selective)
- The indexes can be less useful for searching, depending on your field order and sorting
That’s where check constraints come in.
Tell SQL Server more about your data by building a constraint, a business rule about your data:
|
1 2 3 |
ALTER TABLE dbo.Posts_MultiTenant WITH CHECK ADD CONSTRAINT CK_CompanyCode_BOU CHECK (CompanyCode = 'BOU'); |
And suddenly SQL Server levels up. If I look for non-BOU users, SQL Server knows there can’t possibly be any data:

So it bails out with a constant scan, not even doing any logical reads. Woohoo, faster queries!
Now run our 3 selects again and check out the actual plans:
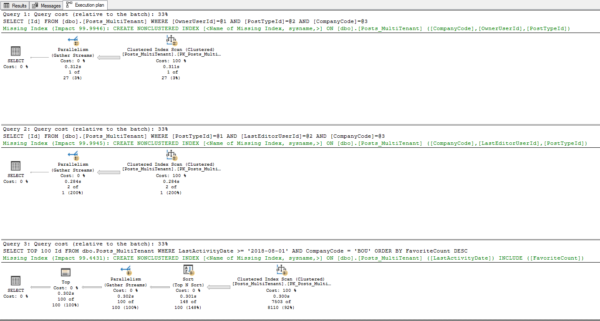
And the index recommendations are different this time – SQL Server knows there’s simply no purpose in leading with CompanyCode since it’s not selective:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Posts_MultiTenant] ([CompanyCode],[OwnerUserId],[PostTypeId]) GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Posts_MultiTenant] ([CompanyCode],[LastEditorUserId],[PostTypeId]) GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Posts_MultiTenant] ([LastActivityDate]) INCLUDE ([FavoriteCount]) GO |
Er…well…maybe not. The first two index recommendations still lead with CompanyCode, but at least the third one doesn’t! Query tuning geeks will be interested to see the actual plans and note that all 3 got full optimization with no early timeouts.
Clippy’s recommendations are rarely perfect.
But on the bright side, you would never use Clippy’s recommended indexes anyway – if you’ve been to Mastering Index Tuning, you know how to hand-craft index recommendations based on the query plan. You might create these instead:
|
1 2 3 4 5 6 7 8 9 |
CREATE NONCLUSTERED INDEX IX_OwnerUserId_PostTypeId ON [dbo].[Posts_MultiTenant] ([OwnerUserId],[PostTypeId]) GO CREATE NONCLUSTERED INDEX IX_LastEditorUserId_PostTypeId ON [dbo].[Posts_MultiTenant] ([LastEditorUserId],[PostTypeId]) GO CREATE NONCLUSTERED INDEX IX_LastActivityDate_FavoriteCount ON [dbo].[Posts_MultiTenant] ([LastActivityDate],[FavoriteCount]) GO |
Note that none of those indexes have CompanyCode in them. I shouldn’t need it – I have a constraint, right? So let’s run our three selects again, and see if SQL Server uses these covering indexes, or does a key lookup to fetch the CompanyCode:
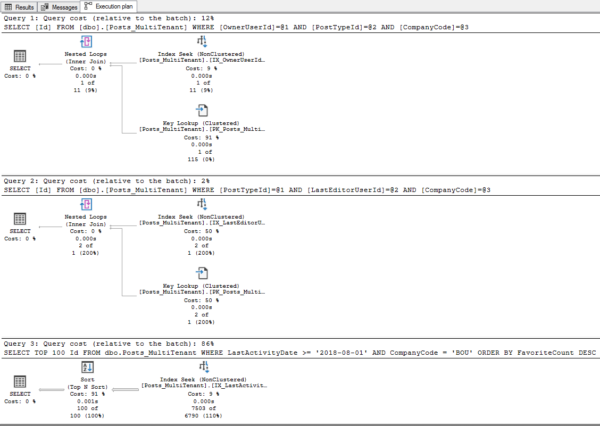
The first two queries still do an index seek plus a key lookup, but the third one wakes up, pays attention to the constraint, and knows it doesn’t need to check CompanyCode.
Why are 2 of the 3 plans bad?
Keen readers of the actual query plans will note that the first two queries were autoparameterized – meaning, SQL Server turned this:
|
1 |
WHERE CompanyCode = 'BOU' |
Into this:
|
1 |
WHERE CompanyCode = @SomeVariableThatCouldBeAbsolutelyAnything |
Because it believed it didn’t matter which string I use for CompanyCode. It made this decision early in the query optimization process – if you dive into the properties for the plan, you’ll notice that on the first two plans, SQL Server left the office early to go drinking:
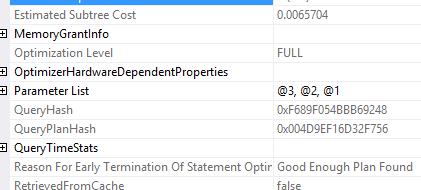
SQL Server believed it’d found a good enough query plan, and called time on optimization. In fairness, these are really fast queries – in most scenarios, they’d be good enough.
But if I happen to get plan reuse & parameter sniffing, and I run those for different parameters – like, say, the most popular IDs in this table:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT Id FROM dbo.Posts_MultiTenant WHERE OwnerUserId = 0 AND PostTypeId = 1 AND CompanyCode = 'BOU'; SELECT Id FROM dbo.Posts_MultiTenant WHERE PostTypeId = 1 AND LastEditorUserId = 0 AND CompanyCode = 'BOU'; |
Then that autoparameterization comes back to haunt me in the actual plans. SQL Server ignores the constraint, does a ton of key lookups, and hilariously, still asks for the missing index starting with CompanyCode!
Constraints help, but they’re not perfect.
The more expensive SQL Server thinks your queries are,
the further it goes into optimization,
and the more likely it is to consider things like constraints.
It won’t suggest constraints to you because it doesn’t know what you plan to put into the database in the first place. That’s your job. Implement constraints, and your tougher queries may – but also may not – take those constraints into account for missing index requests and execution plans. When they don’t, it’s time to roll up your sleeves and master index & query tuning by hand.

14 Comments. Leave new
‘Note that none of those indexes have CountryCode in them’ and why would they?
Because there are key lookups required if you don’t have CompanyCode. (Keep reading the post.)
CountryCode isn’t part of the table though….
Read the post carefully, especially the part about the setup script.
Oh, I think maybe there was confusion about the field name? It’s CompanyCode.
I think they are trying to say that the article refers to CountryCode (in one place) when it was supposed be to be CompanyCode.
How would a INNER join to another table joining by CountryCode and PostTypeId be handled? When the BOU CountryCode check constraint was present on both tables?
Steve – by all means, download the Stack Overflow database and find out. That’s why I love using the Stack databases for our blog posts and demos – you can follow along at home and expand on it, going further in your own time. Jump in! You’ll love it.
The bottom is is “It [still] Depends” and you still need to know what you’re doing when it comes to table and index design and implementation. 😉
Primary purpose of check constraints is to enforce data integrity, to protect the data. Helping optimizer is just a random benefit – it may help, it may not.
I don’t understand. Are you saying 100% of the data in this database has CompanyCode=’BOU’? Is that the kind of “multi-tenant” that has a separate database for each company?
On a related note, have you noticed in Azure SQL the kind of auto-generated indexes that it creates? What are they THINKING?
JRStrn – about the “multi-tenant” thing – yep, this is exactly how some third party software ships, like accounting software that can handle multiple companies (but ends up usually only getting used for a single company.)
Be careful! I have had a particular situation where adding CHECK constraints actually falls down performance of SELECT queries in a large Microsoft Dynamics AX database.
Wouldn’t it then be better to change the index to include the CompanyCode as the last indexed column, so instead of this suggested one:
CREATE NONCLUSTERED INDEX []
ON [dbo].[Posts_MultiTenant] ([CompanyCode],[OwnerUserId],[PostTypeId])
GO
you would create the index like
CREATE NONCLUSTERED INDEX []
ON [dbo].[Posts_MultiTenant] ([OwnerUserId],[PostTypeId],[CompanyCode])
GO
Since all the queries are using equality columns, the index would be fully usable by the query and will have the more selective columns first (which should be fine for the equality queries) and the query plan would not get a missing index request. Flipside would of course be, that your index would become a little bigger since it needs to hold the almost useless CompanyCode too – but the good thing would be that you did not “break” the applications intention of supporting multiple Companies in the table and queries for any CompanyCode will benefit of the index.