Comparing Llama3, Phi3 and Gemma performance on different machines
After playing around with ollama a couple of weeks ago, I was curious how much faster the models run on newer Macbooks. At the end of this, I was hoping to find an LLM that can run reasonably well on my Intel Macbook Pro, but also see how that compares to other machines I had around at the time.
I picked Llama3:8B, Phi-3:4B and Gemma:9B models and ran them on 4 devices:
- 2023 Macbook Pro 14” with M3 Pro
- 2021 Macbook Pro 14” with M1 Pro
- 2019 MBP 16” with 2.6 GHz 6-Core Intel Core i7
- Windows desktop (Ryzen 5 1600, RTX 1080Ti)
I installed the models using ollama, and used a simple prompt for comparing them: “What’s the best way for me to learn about LLMs?”
Comparison
Overall, the desktop is the fastest - almost twices as fast as the M-series Macbooks, and an order of magnitude faster than the Intel laptop. This is followed by M1 Pro and then M3 Pro which is shocking, but more on that below.
Although the desktop has 7 year old hardware, the desktop still has one of the best graphics cards that Nvidia has ever released and 48GB of RAM, so this isn’t too surprising. Ranging from 46 to 76 tokens/s, it generates text much faster than I can read it.
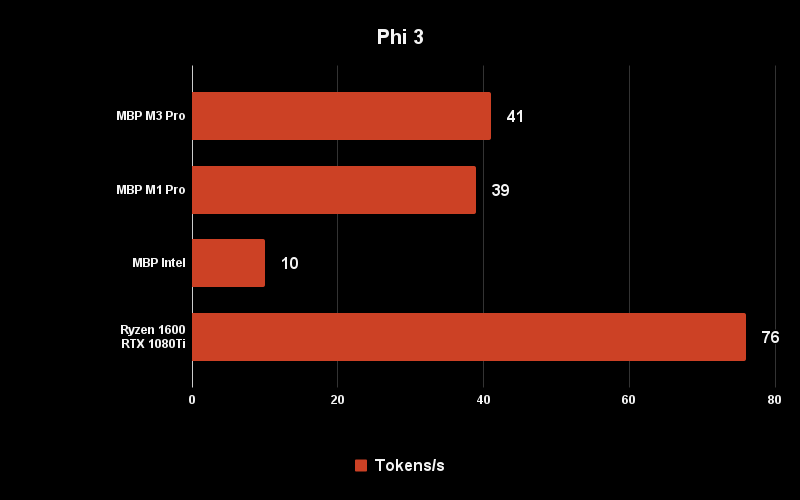
Phi is the smallest model here, and also the fastest. But that too is only 10 tokens/s on the Intel Mac, so not too practical to run on that. Llama and Gemma are slower, but not too much so.
Llama 3

Phi 3
Gemma

Why is M3 slower than M1?
The biggest surprise here is that the M3 chip is actually slightly slower than the M1 chip when running Llama 3 and Gemma. This is because LLMs are constrained by memory bandwidth, and the M3 Pro has 25% less bandwidth (150GB/s) compared to the M1 Pro (200 Gb/s). However, the difference is pretty small, and the M3 is actually a tiny bit faster with Phi-3.
Final thoughts
This is a highly unscientific benchmark, and something I only did to understand what to expect when running LLMs locally. However, it’s actually interesting to see how well these models run on local machines.
I was impressed by how fast a 7 year old desktop performed, with 2X the tokens/s compared to the latest M-series Macbooks. The M-series laptops are still fast enough to run LLMs locally.
The Intel Macbooks are slow enough to be frustrating to use, which is unfortunate because that’s the device I’d normally use to play with LLMs. I guess it’s time to set up WSL on Windows now. :)