How Change Data Capture Powers Modern Apps


At its core, Change Data Capture (CDC) is a method used to track insert, update, and delete operations made to a database.
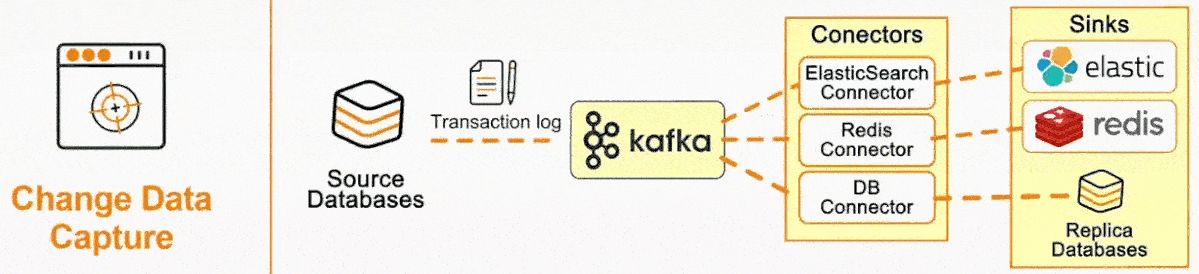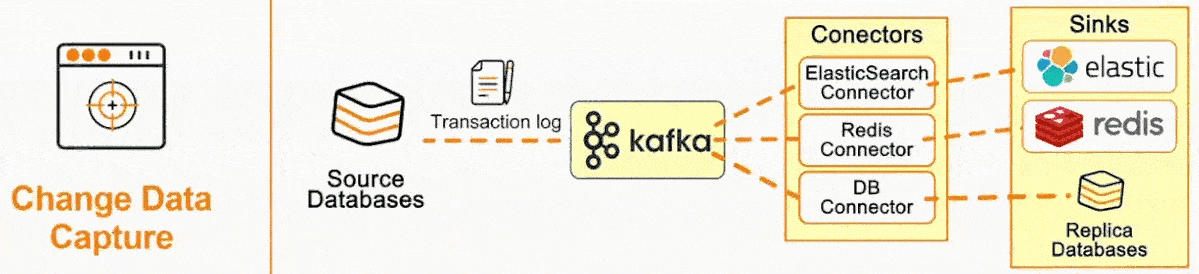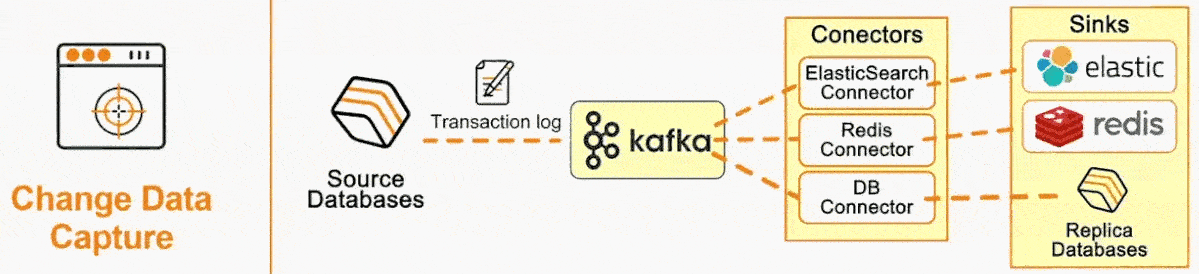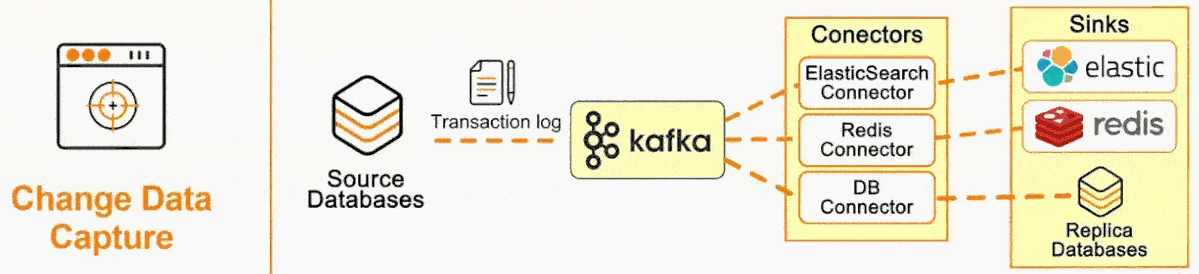
CDC is becoming an increasingly popular software pattern, with dev tooling startups centered around CDC such as Airbyte and Fivetran having cumulatively raised nearly a billion dollars in funding in recent years. The surge in CDC's popularity begs the questions: why has it become so important to today’s developer, and how does it work?
Why now?
CDC isn’t exactly new, but its surge in popularity can be attributed to a few key reasons.
Data fragmentation and growth
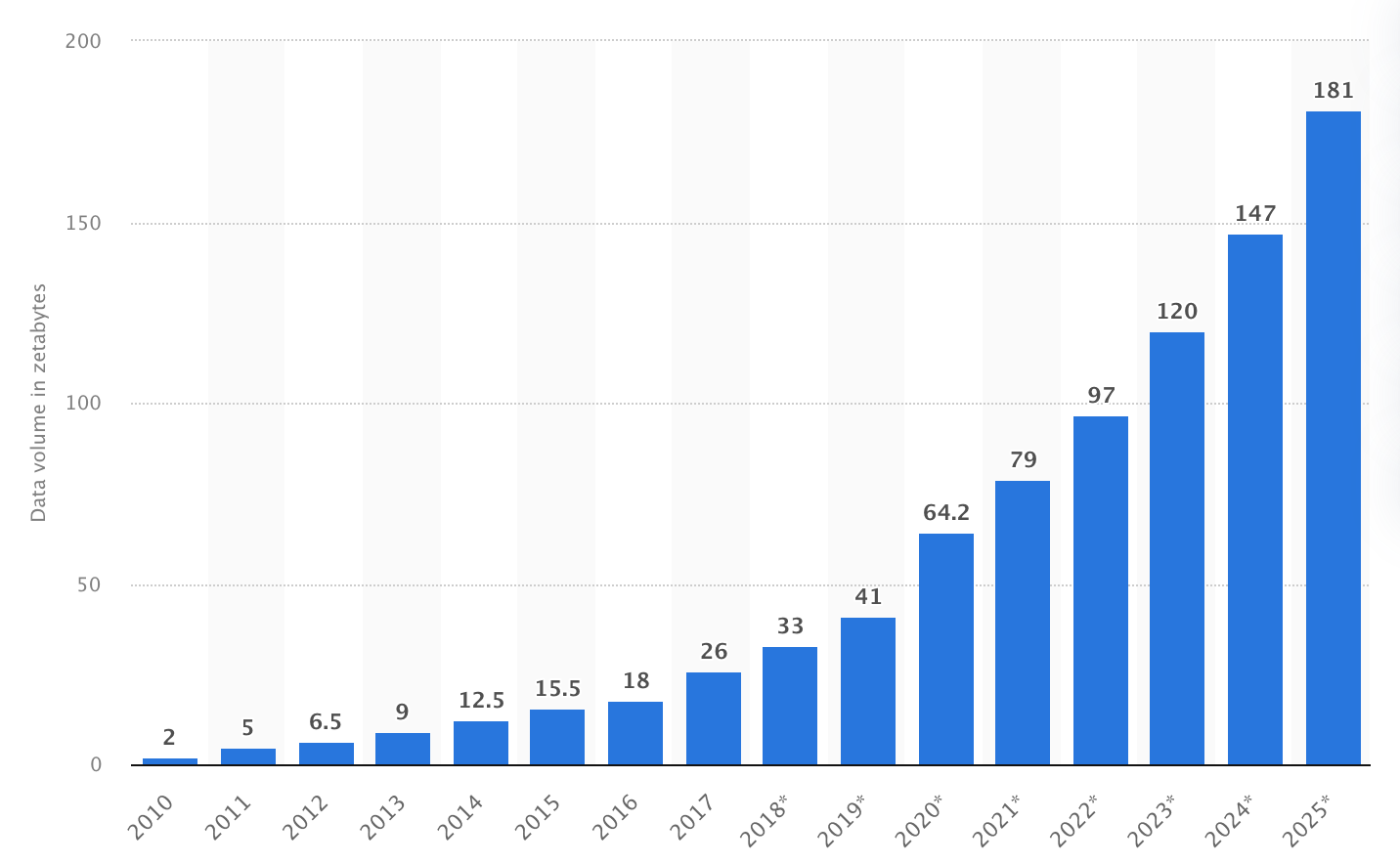
Not only is the amount of data that applications now generate exploding, but the data is increasingly fragmented between various isolated databases, making it a nightmare to keep everything in sync. CDC captures changes across independent data sources, allowing you to unify your data and ensure everyone has the correct info.
Real-time demands
Application data typically flows downstream to a data warehouse periodically on a schedule to be processed for analytics. Today's applications need to react to data changes as they happen, not wait for batch updates. For example, to be able to make faster decisions by not having stale data on dashboards. Since CDC lets you react to changes as they happen, it enables real-time analytics and event-driven architectures.
Ease of adoption
The CDC infrastructure ecosystem has matured to a point where it's now practical for companies at all stages. Open-source projects like Debezium and Kafka have made it easier to build systems that continuously react to data changes. These tools provide the robustness, scalability, and performance needed to process and distribute large volumes of change data in real-time. As CDC continues to get more approachable, it's igniting a surge in demand, creating a powerful feedback loop that's leading to even more tooling development efforts.
How does CDC work?
There are three main types of CDC implementations:
- Log-based captures changes from the existing database transaction logs and is the newest approach.
- Query-based periodically queries the database to identify changes. This approach is simpler to set up but won't capture delete operations.
- Trigger-based relies on database triggers to capture changes and write them to a change table. This approach reduces database performance since it requires multiple writes on each data change.
Log-based CDC is quickly becoming embraced as the de facto approach because it's the least invasive and most efficient. It involves a few steps:
- Log creation: When a change is made to the database, a log entry is created that captures the details of the change.
- Log consumption: The change data is processed and made available for use.
- Data distribution: The data is distributed to the desired systems, such as a data warehouse, cache, or search index.
Let’s take a closer look at each step.
Log creation
Before a database such as PostgreSQL, MySQL, MongoDB, and SQLite stores data to disk, it first writes it to a transaction log.

This write-ahead logging technique allows writes to be more performant since the database can just do the lightweight log append operation before asynchronously making changes to the actual files and indexes. These transaction logs primarily serve as the database's source of truth to fall back on in case of a failure.
In Postgres, the volume of information recorded in the Write-Ahead Logs (WAL) can be adjusted. The wal_level setting offers three options, in ascending order of information logged: minimal, replica, and logical. CDC leverages these existing logs as the source of truth of all data changes, but requires a logical setting that enables changes to be read row-by-row, instead of by the physical disk blocks.
SHOW wal_level;
+-------------+
| wal_level |
|-------------|
| logical |
+-------------+
SQL command to check PostgreSQL's wal_level
The format and structure of the transaction logs depend on the implementation of the database type. For instance, MySQL generates a binlog, while MongoDB uses oplogs.
Log consumption
Fortunately, open-source projects like Debezium can now do most of the hard work of consuming entries from the transaction log and abstracting away the database implementation details with connectors that just produce generic abstract events.
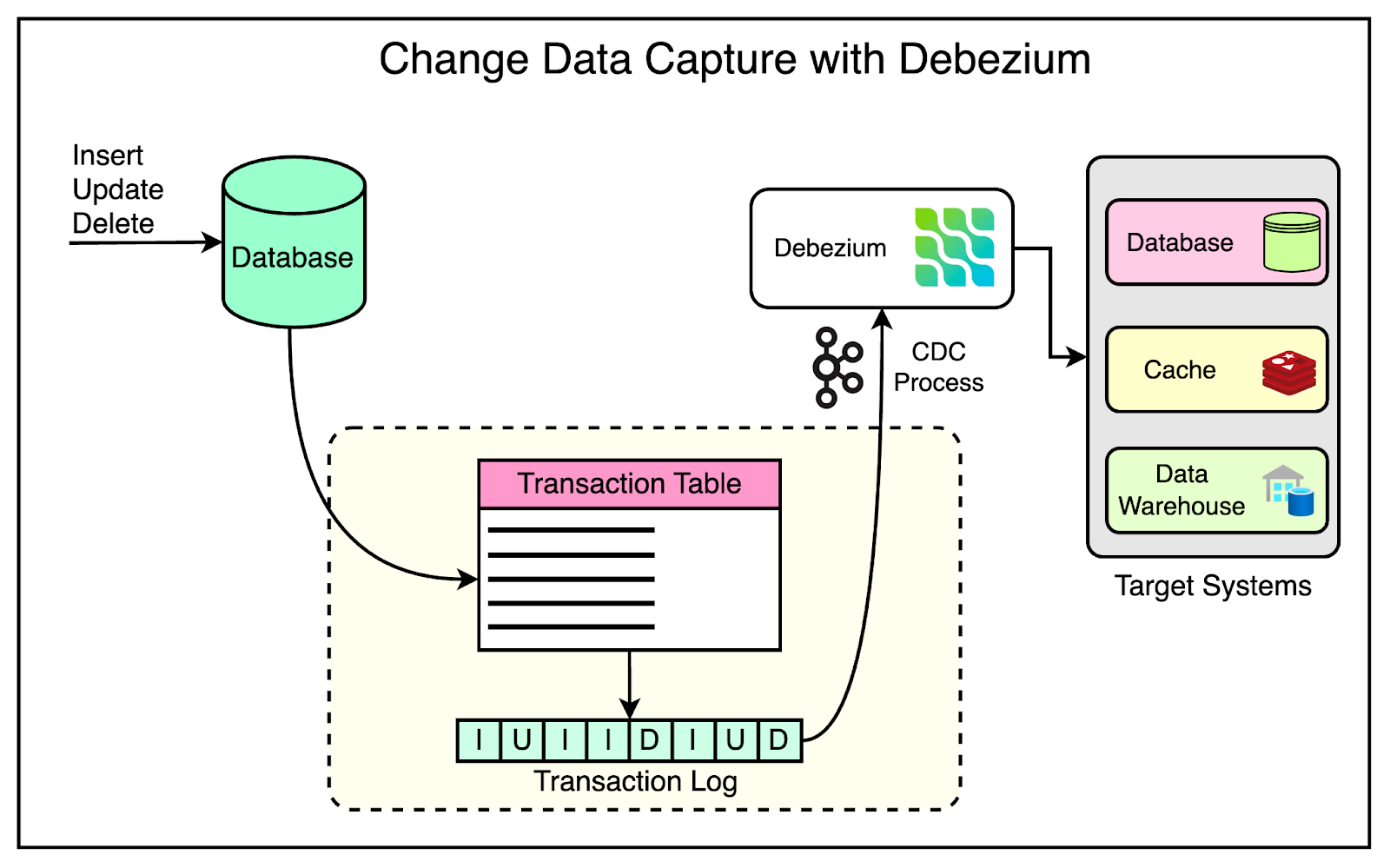
The Postgres connector relies on PostgreSQL’s replication protocol to access changes in real-time from the server’s transaction logs. It then transforms this information into a specific format, such as Protobuf or JSON, and sends it to an output destination. Each event gets structured as a key/value pair, where the key represents the primary key of the table, and the value includes details such as the before and after states of the change, along with additional metadata.
{
"schema": { ... },
"payload": {
"before": {
"id": 1,
"first_name": "Mary",
"last_name": "Samsonite",
}
"after": {
"id": 1,
"first_name": "Mary",
"last_name": "Swanson",
}
},
"source": {
"connector": "postgresql",
"name": "server1",
"ts_ms": 1559033904863,
"snapshot": true,
"db": "postgres",
"sequence": "[\\"24023119\\",\\"24023128\\"]",
"schema": "public",
"table": "customers",
"txId": 555,
"lsn": 24023128,
"xmin": null,
},
"op": "c",
"ts_ms": 1559033904863
}
Example Update event
Data distribution
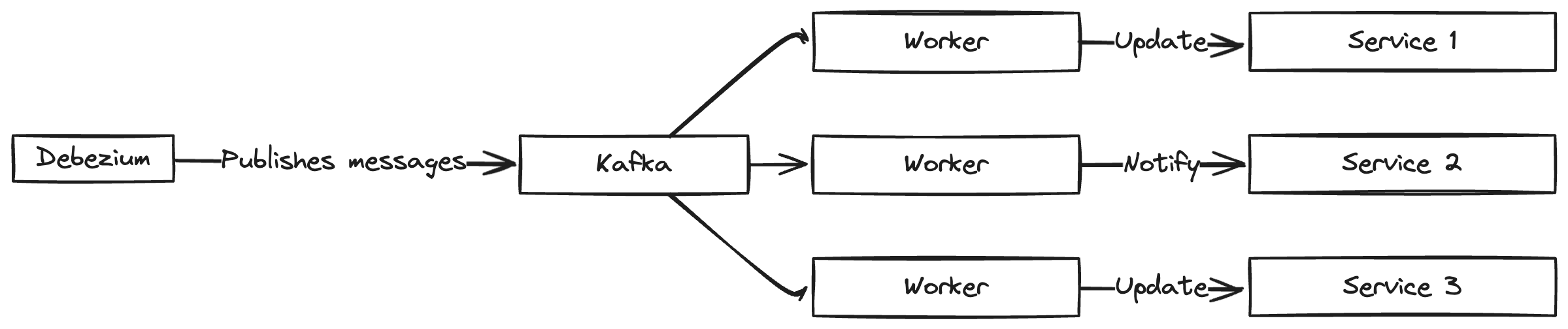
CDC systems typically incorporate a message broker component to propagate the Debezium events. Apache Kafka stands out for this purpose because of a few advantages: scalability to handle large volumes of data, persistence of messages, guaranteed ordering per partition, and compaction capability, where multiple changes on the same record can optionally be easily rolled into one. From the message queue, client applications can then read events that correspond to the database tables of interest, and react to every row-level event they receive.
Patterns
There are countless use cases where CDC systems are invaluable. You can use them to build notification systems instead of relying on callbacks, to invalidate caches, to update search indexes, to migrate data without downtime, to update vector embeddings, or to perform point-in-time data recovery, to name a few. I’ll highlight below some common CDC system patterns I've personally seen in production environments.
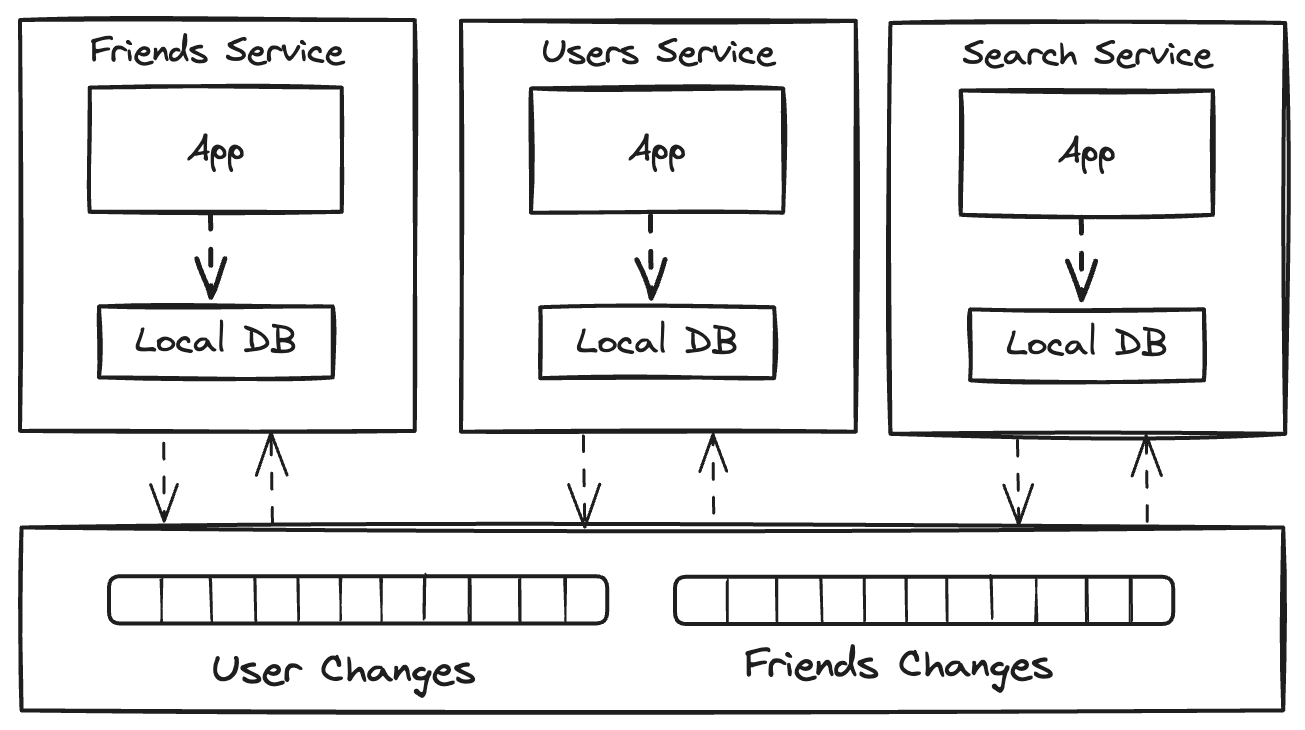
Microservice synchronization
In a microservice based architecture, each service often maintains its own standalone database. For instance, a user service might handle user data, while a friends service manages friend-related information. You might want to combine the data into a materialized view or replicate it to Elasticsearch to power queries such as “give me a user named Mary who has 2 friends”. CDC facilitates the decoupling of systems by enabling real-time data sharing across different components without direct message passing, thus supporting the scalability and flexibility required by these architectures.
Audit Trails
CDC offers the most reliable and performant approach for building robust audit trails. The low-level data change events can be stitched with additional metadata to better record who made the change and why it was made. I'm one of the contributors to Bemi, an open-source tool that provides automatic audit trails, and we did this by creating libraries that inserted additional custom application-specific context (userID, API endpoint, etc.) in the database transaction logs using a similar technique to Google's Sqlcommenter. We stitch this information together in a CDC system and then store the enriched data in a queryable database.

Conclusion
As demand for CDC grows, understanding it is becoming increasingly essential for today's developers. And as developer tooling in this space continues to improve, the countless use cases powered by CDC will continue to get more accessible.
I've intentionally glossed over a lot of CDC details in this blog to keep it short. But I'd recommend checking out the Bemi source code to see how CDC systems that have handled billions of data changes actually work under the hood!