 Google Local Services API
Google Local Services API
 Baidu Search API
Baidu Search API
 Bing Search API
Bing Search API
 DuckDuckGo Search API
DuckDuckGo Search API
 Ebay Search API
Ebay Search API
 Walmart Search API
Walmart Search API
 The Home Depot Search API
The Home Depot Search API
 Naver Search API
Naver Search API
 TypeScript
TypeScript
 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 C++
C++

Imagine you're looking for a shiny new monitor to perfect your setup. You've found the perfect model on a popular shopping site, but there's a catch – it's just a bit outside your budget. You know prices fluctuate, often dropping during sales or special promotions, but checking the website daily is a tedious task that wastes your valuable time.
Instead of manually monitoring the site, we can build a simple yet effective program that checks the price for you. This is where web scraping comes into play, and Beautiful Soup is your ally!

What is Beautiful Soup?
Beautiful Soup is a Python library designed to help you easily extract information from web pages by parsing HTML and XML documents.
Link: Beautiful soup
Beautiful Soup is a versatile tool that can be used to extract all kinds of data from web pages, not just price information. Whether you're interested in headlines from a news website, comments from a forum, product details from an e-commerce site, or any other information, Beautiful Soup can help you automate the extraction process efficiently.
You might also interested in reading this post:
 Hilman Ramadhan
Hilman Ramadhan
Step-by-step tutorial on how to use Beautiful Soup for web scraping
Prerequisites:
- Basic understanding of Python.
- Python is installed on your machine.
- PIP for installing Python packages.
Here's a basic tutorial on web scraping with Python. We will use two popular libraries: requests for making HTTP requests and Beautiful Soup for parsing HTML.
Step 1: Install Necessary Libraries
First, you need to install the requests and BeautifulSoup libraries. You can do this using pip:
pip install requests beautifulsoup4
Step 2: Import Libraries
In your Python script or Jupyter Notebook, import the necessary modules:
import requests
from bs4 import BeautifulSoup
Step 3: Make an HTTP Request
Choose a website you want to scrape and send a GET request to it. For this example, let's scrape Google's homepage.
url = 'https://google.com'
response = requests.get(url)
Step 4: Parse the HTML Content
Once you have the HTML content, you can use Beautiful Soup to parse it:
soup = BeautifulSoup(response.text, 'html.parser')
Step 5: Extract Data
Now, you can extract data from the HTML. Let's say you want to extract all the headings:
headings = soup.find_all('div')
for heading in headings:
print(heading.text.strip())
Step 6: Handle Errors
Always make sure to handle errors like bad requests or connection problems:
if response.status_code == 200:
# Proceed with scraping
# ...
else:
print("Failed to retrieve the web page")
Notes
We need two primary tools to perform web scraping in Python: HTTP Client and HTML Parser.
- An HTTP API Client to fetch web pages.
e.g. requests, urllib, pycurl or httpx - An HTML parser to extract data from the fetched pages.
e.g. Beautiful Soup, lxml, or pyquery
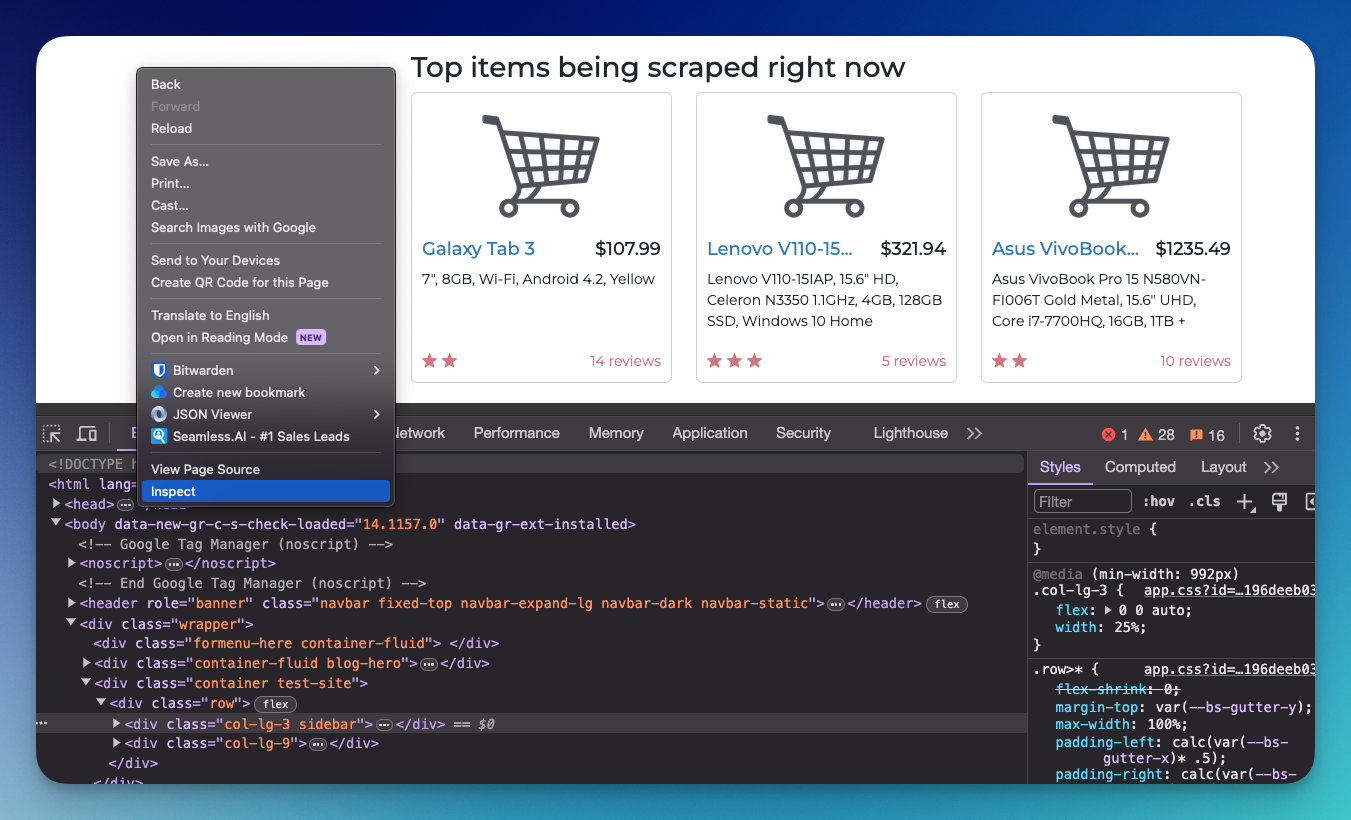
Inspect the page first!
If we want to scrape specific data from a website, we need to know where this data is located.
Websites are built using HTML, which organizes content in a nested structure of elements like headings, paragraphs, and divs. Each element can have attributes like class and id, which are useful for identifying specific page parts.
To effectively use Beautiful Soup to extract data, you need to inspect the website and identify the elements that contain the data you're interested in. This process involves using a web browser's developer tools to look at the HTML structure of the page.
By understanding how the content is organized, you can write more precise and efficient Beautiful Soup code to target exactly what you need, avoiding unnecessary processing and ensuring you get accurate data.
Real-world example using Beautiful Soup
Let's practice! For this example, we're going to scrape the price of the item in this website: https://webscraper.io/test-sites/e-commerce/allinone/computers
Step 1: Inspect the page
Remember always to inspect the page first. We can do this by right-clicking on the page and clicking inspect. You can see the HTML structure in the elements tab.
I can see the price is wrapped in the card element, and specifically on the price CSS class.
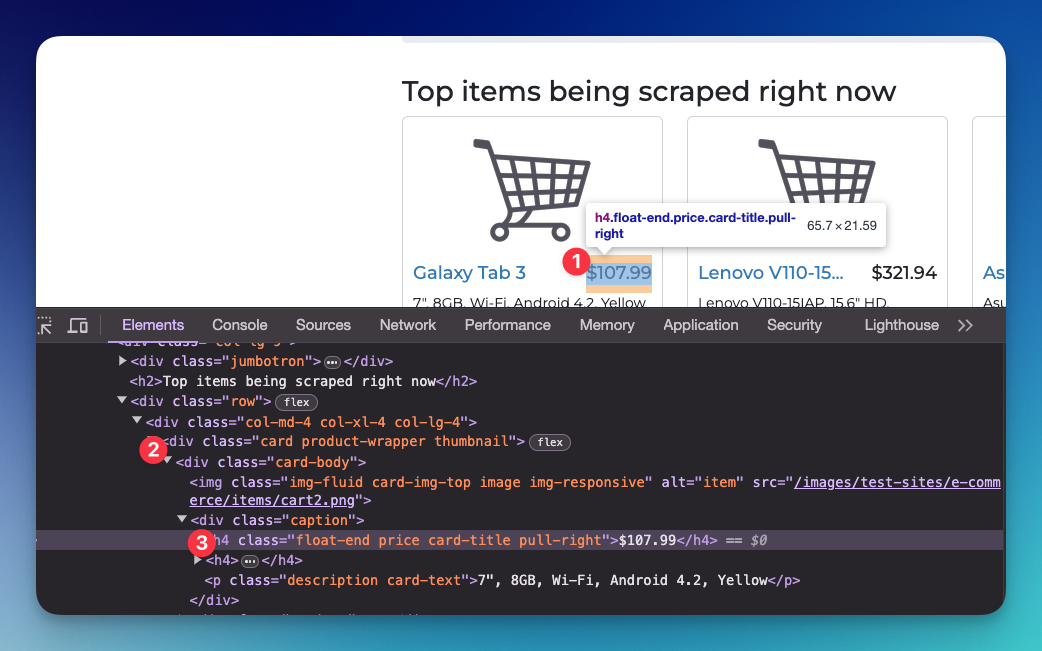
Step 2: Make an HTTP request
In your Python script, import the necessary modules (Make sure to install BeautifulSoup first!):
import requests
from bs4 import BeautifulSoup
Choose a website you want to scrape and send a GET request.
url = 'https://webscraper.io/test-sites/e-commerce/allinone/computers'
response = requests.get(url)
Step 3: Parse the HTML Content
Once you have the HTML content, you can use Beautiful Soup to parse the price information:
soup = BeautifulSoup(response.text, 'html.parser')
Now we're going to scrape all data from the items, not just price.
# Empty list to hold the data
products = []
# Find all product wrapper divs
for card in soup.find_all('div', class_='product-wrapper'):
# Extract title, description, price, rating, and number of reviews
title = card.find('a', class_='title').text.strip()
description = card.find('p', class_='description').text.strip()
price = card.find('h4', class_='price').text.strip()
rating = len(card.find('div', class_='ratings').find_all('span', class_='ws-icon-star'))
reviews = card.find('p', class_='review-count').text.strip().split(' ')[0] # Assuming "X reviews"
# Append the data to the products list
products.append({
'title': title,
'description': description,
'price': price,
'rating': rating,
'reviews': reviews
})
# Display the extracted data
for product in products:
print(product)You should be able to see this data:
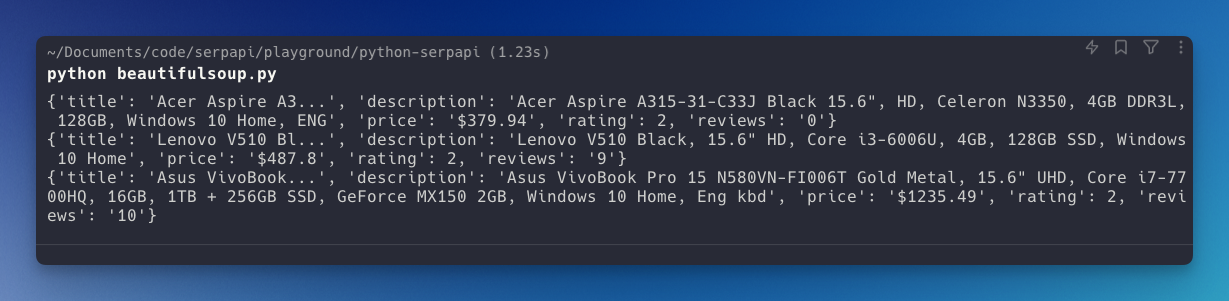
Now, you can expand your code to save this data on your database or CSV files and compare it later after running the script every day (Pro tip: You can use CRON to automate this process).
Parsing data when there is no ID or class provided
If the HTML structure you're working with lacks specific class or id attributes to easily identify elements, you can still use Beautiful Soup to navigate and extract data based on the hierarchical structure of the HTML.
For this example, I'll simplify the previous HTML structure, removing specific class names and id attributes and then demonstrate how to extract the same information.
Here's a simplified version of the HTML structure:
<div>
<div>
<div>
<img src="/path/to/image1.png">
<div>
<h4>$107.99</h4>
<h4>Galaxy Tab 3</h4>
<p>7", 8GB, Wi-Fi, Android 4.2, Yellow</p>
</div>
<div>
<p>14 reviews</p>
<p>Rating: ★★★☆☆</p>
</div>
</div>
</div>
<!-- Repeat for other products -->
</div>
In this scenario, you can still extract data by carefully navigating the structure. Let's write Python code using Beautiful Soup to do this:
from bs4 import BeautifulSoup
html_content = """
<div>
<div>
<div>
<img src="/path/to/image1.png">
<div>
<h4>$107.99</h4>
<h4>Galaxy Tab 3</h4>
<p>7", 8GB, Wi-Fi, Android 4.2, Yellow</p>
</div>
<div>
<p>14 reviews</p>
<p>Rating: ★★★☆☆</p>
</div>
</div>
</div>
<div>
<div>
<img src="/path/to/image2.png">
<div>
<h4>$50.01</h4>
<h4>Second I phone</h4>
<p>Blue night</p>
</div>
<div>
<p>10 reviews</p>
<p>Rating: ★★☆☆☆</p>
</div>
</div>
</div>
</div>
"""
# Parse the HTML content
soup = BeautifulSoup(html_content, 'html.parser')
# Empty list to hold the data
products = []
# Assuming each product is within the third-level div
for div in soup.div.find_all('div', recursive=False):
# Extract the image, price, title, description, reviews, and rating
img_src = div.div.img['src']
price = div.div.find_next('h4').text
title = div.div.find_next('h4').find_next_sibling('h4').text
description = div.div.find('p').text
reviews = div.div.find_all('p')[1].text.split(' ')[0]
rating = div.div.find_all('p')[2].text.count('★')
# Append the product data to the products list
products.append({
'img_src': img_src,
'price': price,
'title': title,
'description': description,
'reviews': reviews,
'rating': rating
})
# Display the extracted data
for product in products:
print(product)
It demonstrates how you can still extract data without specific class names or ids, by carefully navigating the HTML tree and using the relationships between elements.