Getting started with Azure's Hybrid and Embedded Text-to-Speech

Over the past few months, I've been experimenting with Azure's Text-to-Speech service. It is a super powerful API that enables fluid, natural-sounding text to speech that matches the tone and emotion of human voices.
Whether you are building an app or a game, Text-to-Speech can be very useful. For example, think of the different stages of game development - during concept and pre-production, text-to-speech can help build out the feel of the game and enhance your scripts before you record with real voice actors.
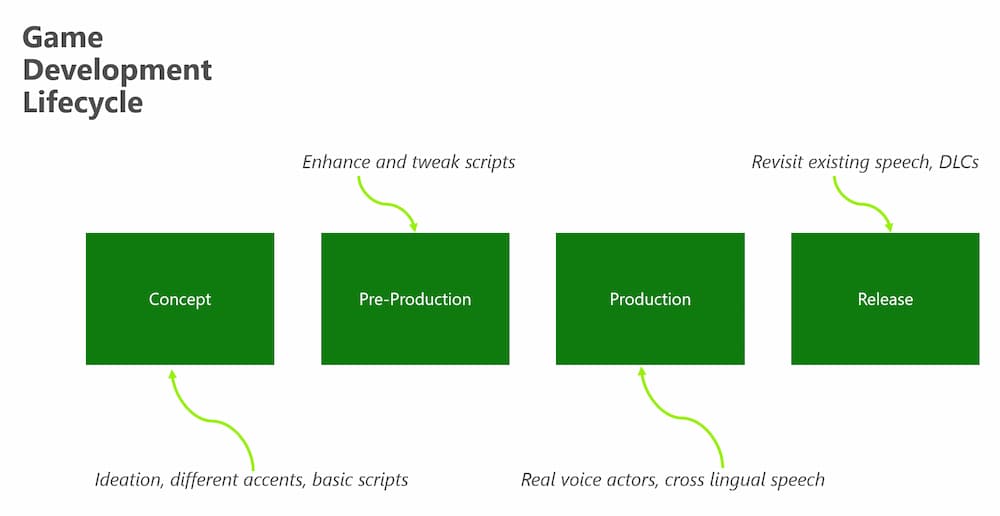
During release and production , it can be used to provide accessibility options to suit the needs of your users. At the time of writing this article, there are over 456 voices across 147 languages that you can choose from!
As you are reading through this, you might be thinking to yourself...hang on...This uses a Cloud service, how would this work for an offline game? Or when a user loses connection?
This is where Hybrid (and Embedded) speech comes into play, and in this article, we are going to explore an example that will work both online and offline scenarios.
How Hybrid Speech works
Hybrid speech uses the cloud speech service by default and embedded speech as a fallback in case cloud connectivity is limited or slow.
In fact, you could ship your entire app with just the embedded speech and not use the cloud service at all. Its worth mentioning that it is slightly limited in that while the quality is good, the cloud option returns the highest quality speech. To give you and idea of what this looks like, lets compare the two versions. The first is the embedded speech version:
And the the second is the cloud based version:
If you listen really closely, you can hear that there is a slight improvement in the tone and cadence of the cloud speech service. There is not much difference, and the embedded version sounds pretty good too!
In this article, I am going to take you through a basic example of hybrid and embedded speech using Azure's Text to Speech Service.
Let's get started
Before we get started, we need to download the voices that we will use with the embedded version of the code. That is, the voices that will actually "ship" with the code. In order to acquire the voices, you will need to apply for access - follow this link to request access to the voices.
Once you have the voices, we can then start building out our example. First off, let's start by creating a new project in Visual Studio Code. Next, add a new class called Keys that will contain the keys and settings that we need.
public class Keys
{
public static string EmbeddedSpeechSynthesisVoicePath = @"\voices\en-us";
public static string EmbeddedSpeechSynthesisVoiceKey = "your_key";
public static string EmbeddedSpeechSynthesisVoiceName = "en-US-JennyNeural";
public static string CloudSpeechSubscriptionKey = "subscription_key";
public static string CloudSpeechServiceRegion = "eastus";
public static string SpeechRecognitionLocale = "en-US";
public static string SpeechSynthesisLocale = "en-US";
}
Let's break down the code above. Firstly, the variable EmbeddedSpeechSynthesisVoicePath points to the file location where the voices are located and EmbeddedSpeechSynthesisVoiceKey is the key that you need to access the voices. You'll be given these when you apply for the access as mentioned above. I've also chosen the voice of "Jenny", but you could choose any from the Voice Gallery.
As we are using a hybrid model, we'll need to provide some cloud details from an Azure speech instance. I created a new speech instance on the Azure portal and on the overview page, I selected the CloudSpeechSubscriptionKey and CloudSpeechServiceRegion from the portal (highlighted in yellow below).
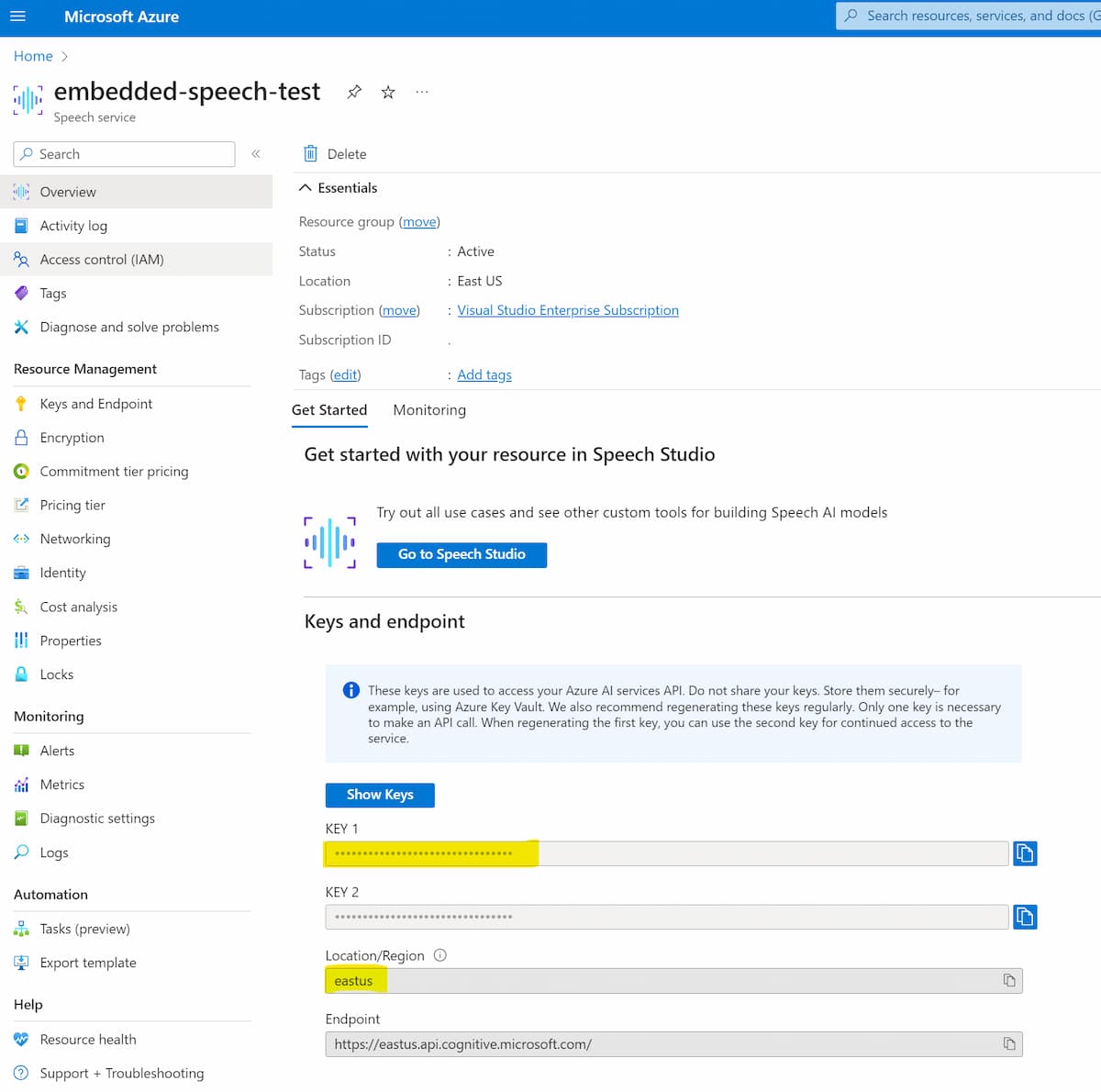
In the code above, we are also providing the instance region and the locale that we are going to be using in the variables SpeechRecognitionLocale and SpeechSynthesisLocale. In this case I'm using US English, but you could use any language and locale of your choice.
Configuring the Embedded Speech
Now that we have the keys configured, we can create the config for the embedded speech model. I've created a new class file called Settings and added the following code.
public class Settings
{
public static EmbeddedSpeechConfig CreateEmbeddedSpeechConfig()
{
List<string> paths = new List<string>();
var synthesisVoicePath = Keys.EmbeddedSpeechSynthesisVoicePath;
if (!string.IsNullOrEmpty(synthesisVoicePath) && !synthesisVoicePath.Equals("YourEmbeddedSpeechSynthesisVoicePath"))
{
paths.Add(synthesisVoicePath);
}
// Make sure that there is a voice path defined above.
if (paths.Count == 0)
{
Console.Error.WriteLine("## ERROR: No model path(s) specified.");
return null;
}
var config = EmbeddedSpeechConfig.FromPaths(paths.ToArray());
if (!string.IsNullOrEmpty(Keys.EmbeddedSpeechSynthesisVoiceName))
{
// Mandatory configuration for embedded speech synthesis.
config.SetSpeechSynthesisVoice(Keys.EmbeddedSpeechSynthesisVoiceName, Keys.EmbeddedSpeechSynthesisVoiceKey);
if (Keys.EmbeddedSpeechSynthesisVoiceName.Contains("Neural"))
{
// Embedded neural voices only support 24kHz sample rate.
config.SetSpeechSynthesisOutputFormat(SpeechSynthesisOutputFormat.Riff24Khz16BitMonoPcm);
}
}
return config;
}
The code above uses the different file paths and keys that we set in the Keys class file. We'll be using this EmbeddedSpeechConfig object to create speech using the local voices on file.
Configuring the Hybrid Speech
In the same way that we set up the EmbeddedSpeechConfig object, we'll need to create a CreateHybridSpeechConfig object.
public static HybridSpeechConfig CreateHybridSpeechConfig()
{
var cloudSpeechConfig = SpeechConfig.FromSubscription(Keys.CloudSpeechSubscriptionKey, Keys.CloudSpeechServiceRegion);
cloudSpeechConfig.SpeechRecognitionLanguage = Keys.SpeechRecognitionLocale;
cloudSpeechConfig.SpeechSynthesisLanguage = Keys.SpeechSynthesisLocale;
var embeddedSpeechConfig = CreateEmbeddedSpeechConfig();
var config = HybridSpeechConfig.FromConfigs(cloudSpeechConfig, embeddedSpeechConfig);
return config;
}
You'll notice that the code above calls the CreateEmbeddedSpeechConfig() function that we created earlier. This is because we'll be using this code to use the cloud speech service by default and then fallback to the embedded speech in case cloud connectivity is limited or slow.
Try it out
With all this in place, we are now ready to start calling the API and synthesizing some speech.
/// <summary>
/// Synthesizes speech using the hybrid speech system and outputs it to the default speaker.
/// </summary>
private static async Task HybridSynthesisToSpeaker()
{
var textToSpeak = "Hello, this is a test of the hybrid speech system.";
var speechConfig = Settings.CreateHybridSpeechConfig();
using var audioConfig = AudioConfig.FromDefaultSpeakerOutput();
using var synthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
using var result = await synthesizer.SpeakTextAsync(textToSpeak);
}
When you call HybridSynthesisToSpeaker().Wait(), you should now hear something coming from your speaker!
In these code samples, I have created a simple string that we are passing through to the API. Depending on your use case, you could build more complex examples using Speech Synthesis Markup Language (SSML). Speech Synthesis Markup Language (SSML) is an XML-based markup language that you can use to fine-tune your text to speech output attributes such as pitch, pronunciation, speaking rate, volume, and more.
Using Embedded Speech only
If you preferred to use embedded speech only, you can call the CreateEmbeddedSpeechConfig() function that we created earlier.
/// <summary>
/// Synthesizes speech using the embedded speech system and outputs it to the default speaker.
/// </summary>
private static async Task EmbeddedSynthesisToSpeaker()
{
var textToSpeak = "Hello, this is a test of the embedded speech system.";
var speechConfig = Settings.CreateEmbeddedSpeechConfig();
using var audioConfig = AudioConfig.FromDefaultSpeakerOutput();
using var synthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
using var result = await synthesizer.SpeakTextAsync(textToSpeak);
}
When you call EmbeddedSynthesisToSpeaker().Wait(), you should now hear embedded speech coming from your speaker!
Summary
I've barely scratched the surface of the capabilities of text-to-speech; there is so much more to experiment with! If you'd like to learn more about Embedded/Hybrid Speech, I recommend reading the following article for more information.
In this article, we covered both embedded and hybrid speech options and its also worth mentioning that you can ship with only embedded speech if you prefer. In the code example that we ran through, we used C# but there are other language options available including C++, and Java SDKs.