Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Have you been able to replace your database implementation transparently because of the use of the repository pattern? While this is a controversial question and topic, I will explain why it doesn’t need to be. Sure, you’re creating an abstraction, but an abstraction around what?
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Repository Pattern
First, we need to agree on the definition of the Repository Pattern. I will use the definition in the Patterns of Enterprise Application Architecture.
Conceptually, a Repository encapsulates the set of objects persisted in a data store and the operations performed over them, providing a more object-oriented view of the persistence layer.
I think everyone can agree on that definition, but I think some of the confusion is around what a “set of objects” means. What type of objects are we talking about?
I’ve found two ways people think about objects in a repository. The first is thinking of them as a data model. It represents how you persist data in your data store and the mapping that goes along.
The second group of people comes at it from a Domain Driven Design perspective and thinks about a domain model of aggregates composed of entities and value objects.
There are generally, these two sides view a repository differently, hence why the use of a repository can become a hot topic.
Differences
On the surface, you might think of an aggregate or a data model with some hierarchy as being the same. But there’s a difference.
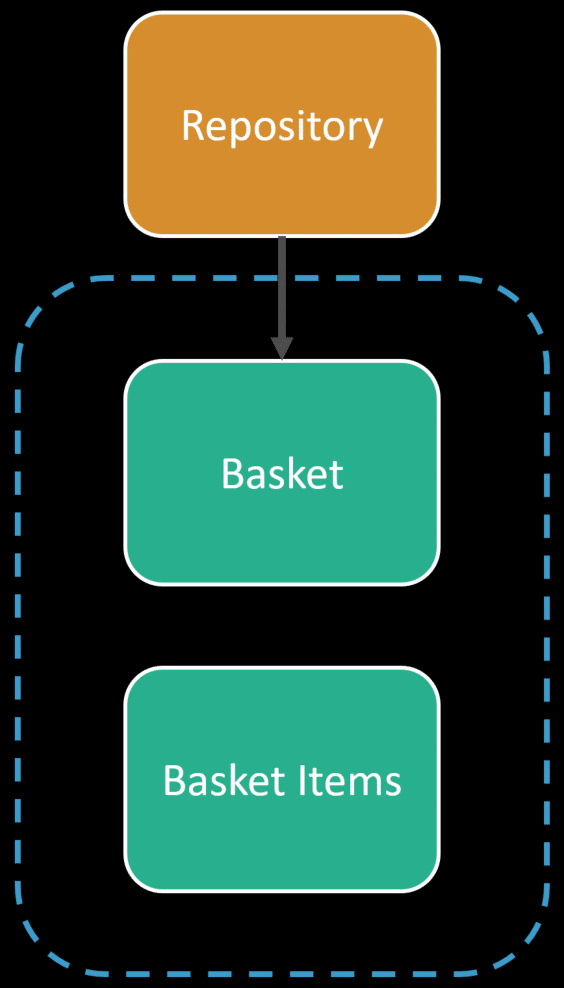
In the example above, I have a repository that fetches a basket and its collection of basket items. This object model hierarchy sure looks like an aggregate.
However, the difference between an aggregate and a data model is behaviors.
Behavior
With an aggregate, you’re exposing behaviors to make state changes. An aggregate represents a consistency boundary. The root entity is the entry point to invoke behaviors that will make changes to the state of the aggregate as a whole. Because of this, it’s also the place where business rules are enforced.
Here’s an example.
While this is a trivial example, AddItem ensures that only one item in our _items collection exists for a catalogItemId. Because items themselves don’t know about other items, this is why our Basket is the aggregate root.
If we worked with a data model, we could have this logic in a transaction script or somewhere higher up the call stack, but the point of our aggregate is to hold all the logic to where we make state changes.
Data
So, if you’re making state changes and need to encapsulate those behaviors within an aggregate, what situation would you want a data model?
Typically, you want to query data for UI purposes. In that case, we’ve established a difference between needing to make state changes and querying data. Guess where we’ve landed? You guessed it, CQRS.
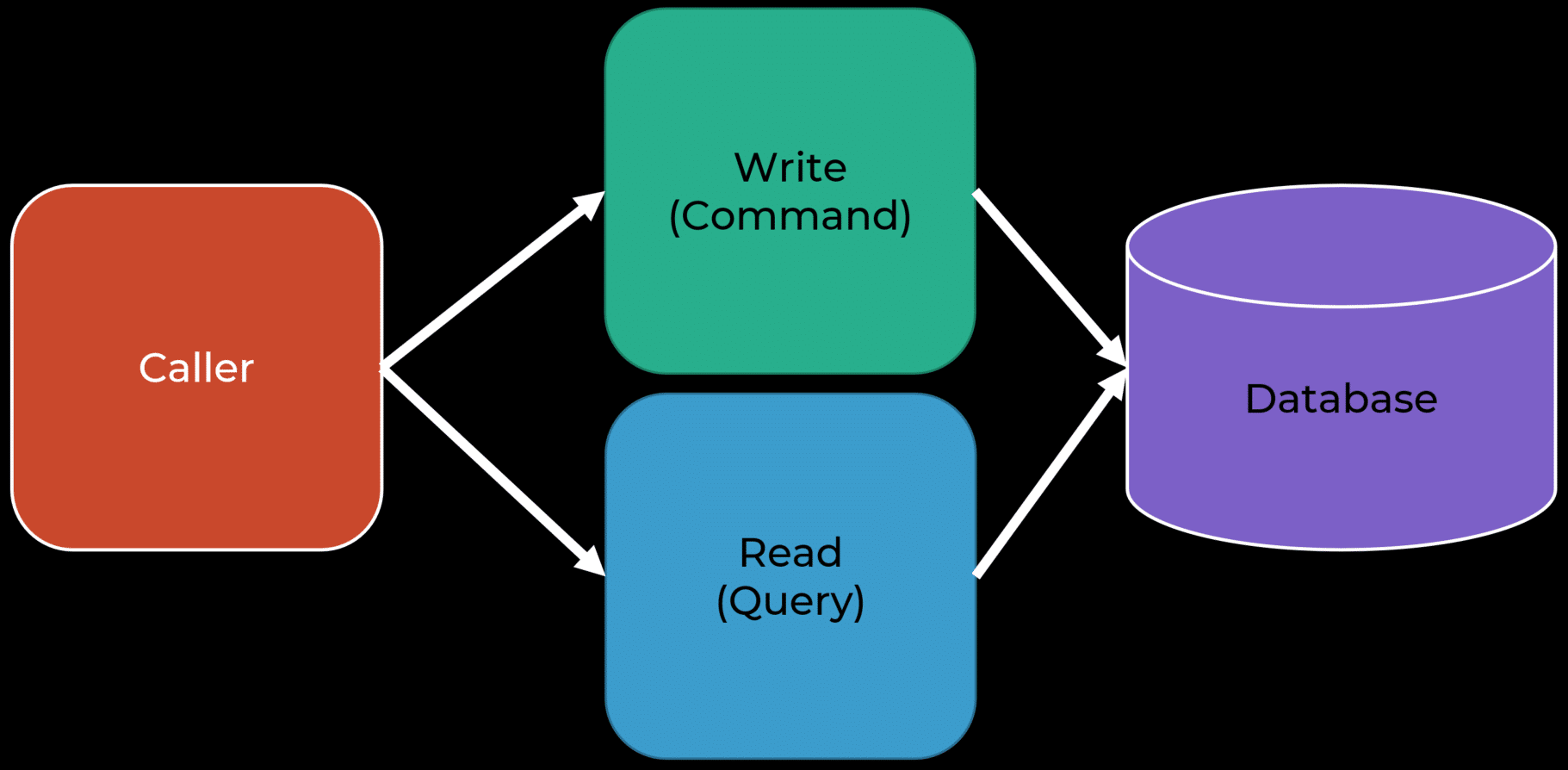
So, when you start thinking about the difference between the two, why would I want to use a repository that’s returning an aggregate when I don’t need to make state changes?
Sure, you can use an aggregate for queries if you expose the data within them, but do you need all that data? Your aggregate is backed by all the data used for state changes to ensure consistency. Queries are often specialized for their use case. They don’t always need all the data. Ultimately, you’d often be over-fetching data if you returned an aggregate for query purposes.
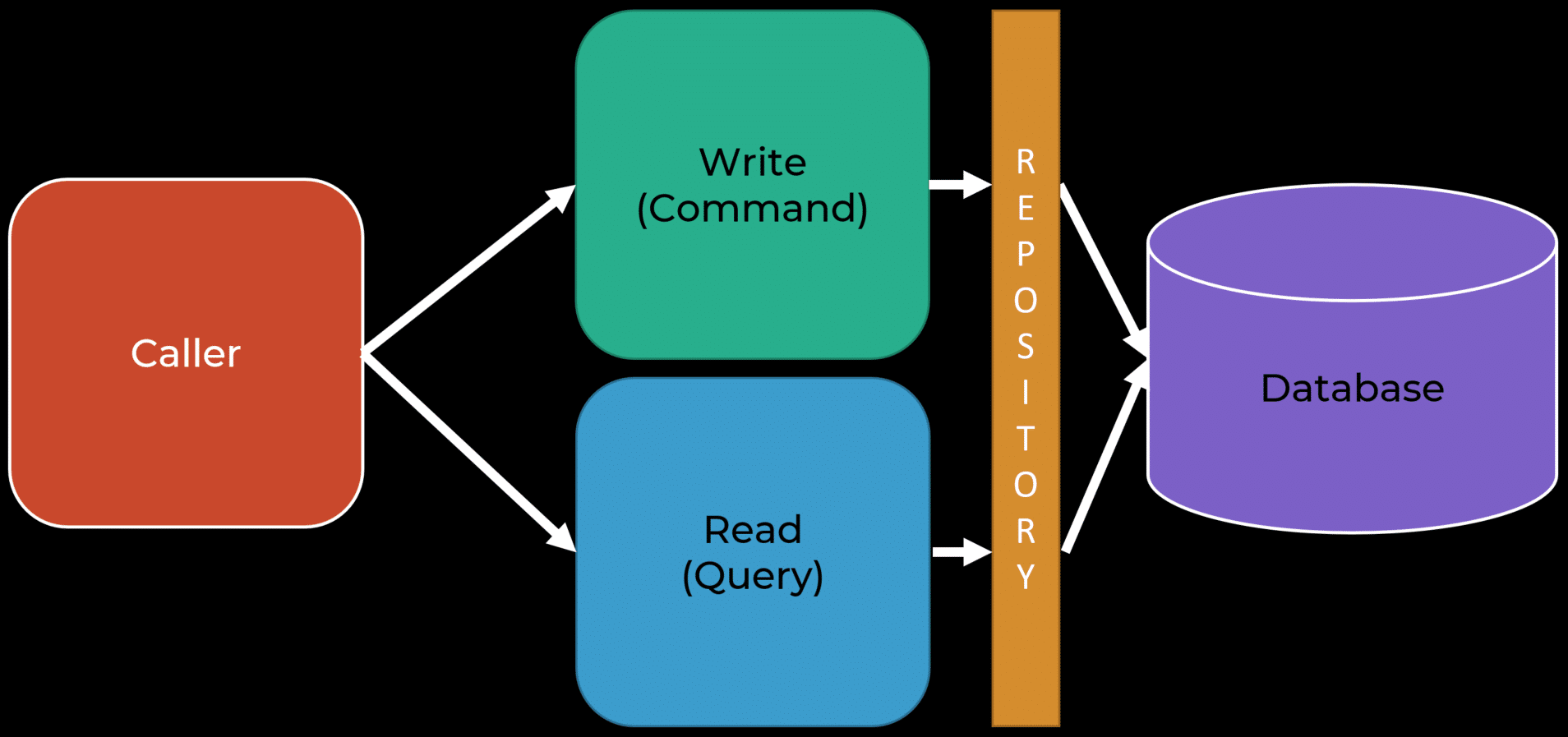
You’ll likely conclude that then you only need a repository for commands. If a repository returns an aggregate, and an aggregate is used for state changes, that only happens when executing a command.
Queries are a use-case. As mentioned, it is often very specialized for a specific need to fetch specific data. Using a repository to over-fetch data and then having to transform it into you use case can add a lot of indirection and complexity.
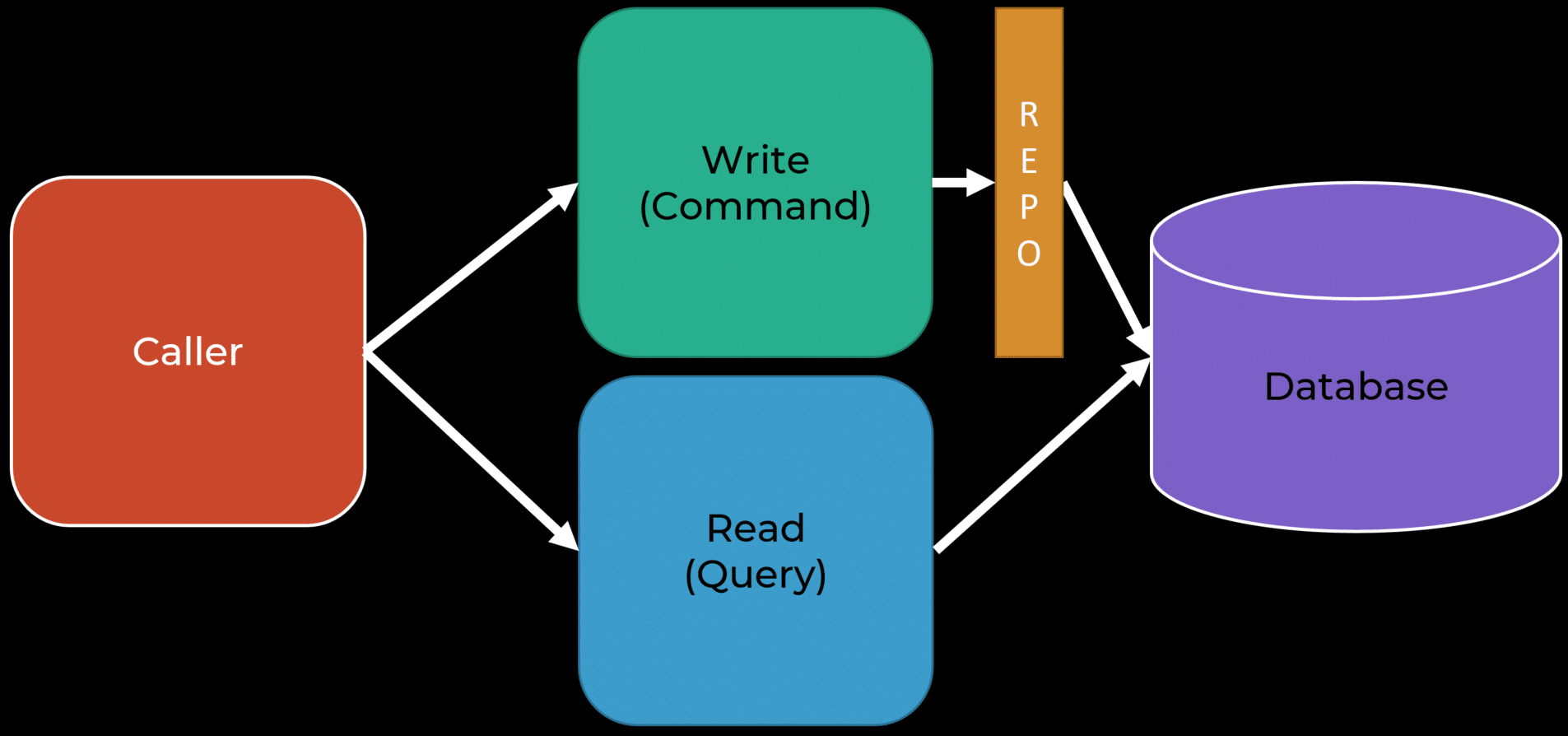
Let your queries define how they retrieve data. Does this mean not abstracting your data access? It can. Or it might not. You make that decision. Now, you’re talking about coupling between queries and your database. Do you need an abstraction if you have ten queries coupled to your database? Do you need an abstraction if you have 1000 queries coupled to your database? Your answers may differ.
Repository Pattern
Thanks to David Fowler for tweeting this, as it inspired this video/blog. The answers to this question are going to be all over the place. Some don’t abstract or use the repository pattern because they think or have never replaced an underlying database. Another group of people always abstract and use the repository pattern because they have replaced their underlying database.
I think the key thing to be thinking about, however, is your use case. If you’re using a repository for commands and returning aggregates, that repository/abstraction will look very different than an abstraction that’s for querying data in a very specific way and/or doing transformations while querying the database and not in memory once data is returned.
A repository for an aggregate might have only a few methods. GetById, Save. There may be a few more, but you know exactly the aggregate you need to call. You’re not querying and filtering by other data elements, it’s generally by the key.
Join!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.