
Barista: Enabling Greater Flexibility in Machine Learning Model Deployment

Machine learning (ML) model deployment is one of the most common topics of discussion in the industry. That’s because deployment represents a meeting of two related but dramatically different domains, ML practice and software development. ML work is experimental: practitioners iterate on model features and parameters, and tune various aspects of their models to achieve a desired performance. The work demands flexibility and a readiness to change. But when they’re deployed, models become software: they become subject to the rigorous engineering constraints that govern the workings of production systems.
The process can frequently be slow and awkward, and the interfaces through which we turn models into deployed software are something we devote a lot of attention to, looking for ways to save time and reduce risk. At Etsy, we’ve been developing ML deployment tools since 2017. Barista, the ML Model Serving team’s flagship product, manages lifecycles for all types of models - from Recommendations and Vision to Ads and Search. The Barista interface has evolved dramatically alongside the significant evolution in the scope and range of our ML practice. In this post we’ll walk you through the story of where we started with this interface, where we ended up, and where we intend to keep going.
Arc 1: Managing Deployed Model Configs as Code
Like many companies deploying ML models to production, Etsy’s ML platform team uses Kubernetes to help scale and orchestrate our services. At its core, Barista itself is a Python+Flask-based application that utilizes the Kubernetes Python API to create all the Kubernetes objects necessary for a scalable ML deployment (Deployment, Service, Ingress, Horizontal Pod Autoscaler, etc.). Barista takes a model deployment configuration specified by users and performs CRUD operations on model deployments in our Kubernetes cluster.
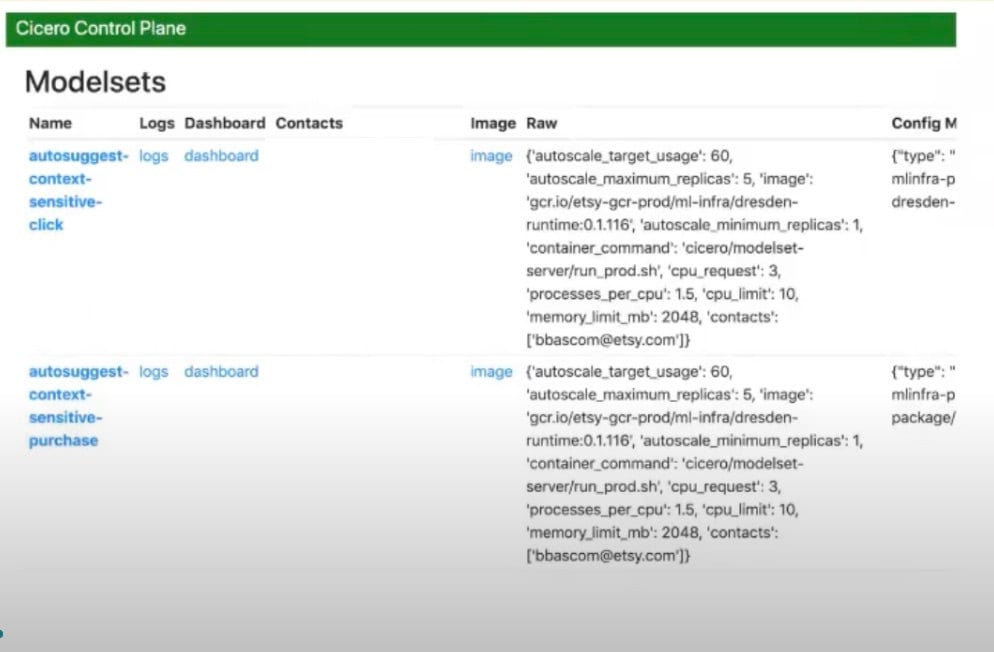
In the initial version of Barista, the configurations for these deployments were managed as code, via a simple, table-based, read-only UI. Tight coupling of configuration with code is typically frowned upon, but on the scale of our 2017-era ML practice it made a lot of sense. Submitting config changes to the Barista codebase as PRs, which required review and approval, made it easy for us to oversee and audit those changes. It was no real inconvenience for us to require our relatively small corps of ML practitioners to be capable of adding valid configurations to the codebase, especially if it meant we always knew the who, what, and when of any action that affected production.

Updating configurations in this tightly coupled system required rebuilding and deploying the entire Barista codebase. That process took 20-30 minutes to complete, and it could be further blocked by unrelated code errors or by issues in the build pipeline itself. As ML efforts at Etsy began to ramp up and our team grew, we found ourselves working with an increasing number of model configurations, hundreds of them ultimately, defined in a single large Python file thousands of lines long. With more ML practitioners making more frequent changes, a build process that had been merely time-consuming was becoming a bottleneck. And that meant we were starting to lose the advantage in visibility that had justified the configuration-as-code model for us in the first place.
Arc 2: Decoupling Configs with a Database
By 2021, we knew we had to make changes. Working with Kubernetes was becoming particularly worrisome. We had no safe way to quickly change Kubernetes settings on models in production. Small changes like raising the minimum replicas or CPU requests of a single deployment required users to push Barista code, seek PR approval, then merge and push that code to production. Even though in an emergency ML platform team members could use tools like kubectl or the Google Cloud Console to directly edit deployment manifests, that didn't make for a scalable or secure practice. And in general, supporting our change process was costing us significant developer hours.
So we decoupled. We designed a simple CRUD workflow backed by a CloudSQL database that would allow users to make instantaneous changes through a Barista-provided CLI.
The new system gave us a huge boost in productivity. ML practitioners no longer had to change configs in code, or develop in our codebases at all. They could perform simple CRUD operations against our API that were DB-backed and reflected by the deployments in our cluster. By appropriately storing both the live configuration of models and an audit log of operations performed against production model settings, we maintained the auditability we had in the PR review process and unblocked our ML practitioners to deploy and manage models faster.
We designed the CLI to be simple to use, but it still required a certain degree of developer setup and acumen that was inconvenient for many of our ML practitioners. Even simple CLIs have their quirks, and they can be intimidating to people who don't routinely work on the command line. Increasingly the platform team was being called on to help with understanding and running CLI commands and fixing bash issues. It began to look as if we'd traded one support burden for another, and might see our productivity gains start to erode
Arc 3: A UI Built Mostly by Non-UI People
We’d always had an API, and now we had a database backing that API. And we had the command line: but what we needed, if we wanted wide adoption of our platform across an increasing user base, was a product. A purpose-built, user-friendly Web interface atop our API would let ML practitioners manage their model deployments directly from the browser, making CLI support unnecessary, and could compound the hours we'd saved moving to the CRUD workflow. So, in the summer of 2021 we started building it.
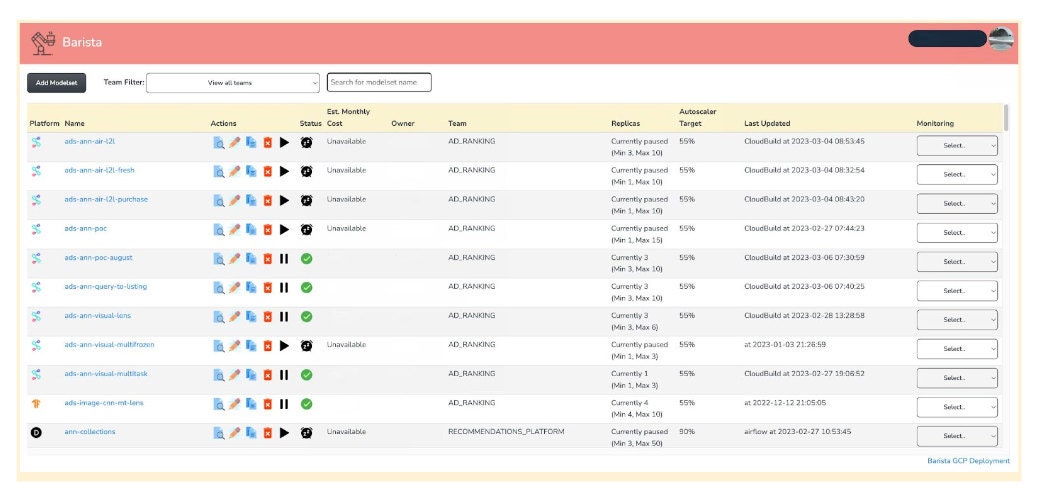
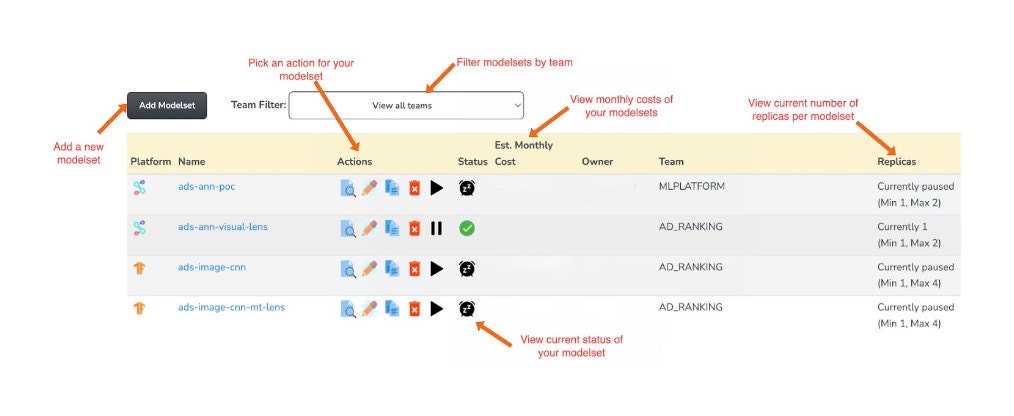
Now this is certainly not the most aesthetic web app ever built – none of us on the ML platform team are front-end developers. What it is, though, is a fairly robust and complete tool for managing ML deployments on Kubernetes. We've given our users the ability to update anything to do with their models, from application settings to model artifacts to Kubernetes settings like CPU resources or replicas. The UI provides useful integrations to the Google Kubernetes Engine (GKE) console to render information about Pods in a deployment, and even integrates with the API of our cost tool so practitioners can understand the cost of serving their models live in production.
In 2017, Barista was an HTML table and Python config file. Now, in 2023, it’s fully functioning web interface that integrates with multiple internal and third-party APIs to render useful information about models, and gives users complete and immediate control over their model deployments. Small changes that might have taken hours can happen in seconds now, unblocking users and reducing the toll of unnecessary workflows.
Arc 4: Security and Cost
The Barista UI made it so much easier to serve models at Etsy that it helped drive up the rate of experimentation and the number of live models. Suddenly, over the course of a few months, Barista was seeing hundreds of models both in production and on dev servers. And while we were thrilled about the product’s success, it also raised some concerns: specifically, that the simplicity and user-friendliness of the process might lead to spikes in cloud cost and an increase in misconfigurations.
Serving a model on Barista accrues cost from Google Cloud, Etsy’s cloud computing service partner. This cost can range anywhere from a few hundred to thousands of dollars per month, depending on the model. While the costs were justified in production, in the development system we were seeing high daily CPU costs with relatively low usage of the environment, which was something that needed a remedy.
Unfortunately, by default the Kubernetes Horizontal Pod Autoscaler, which we were using to manage our replicas, doesn't let you scale down below 1. With the increased flow of models through Barista, it became harder for ML practitioners to remember to remove resources when they were no longer needed–and unless a deployment was completely deleted and recreated, we were going to keep incurring costs for it. To mitigate the issue we added the Kube Downscaler to our development cluster. This allowed us to scale deployment replicas to zero both off-hours and on the weekends, saving us about $4k per week.
We still had deployments sitting around unused on weekdays, though, so we decided to build Kube Downscaler functionality directly into Barista. This is a safety feature that pauses model deployments: by automatically scaling models in development to zero replicas after three hours, or on user demand. We're now seeing savings of up to 82% in dev cost during periods of inactivity. And we've avoided the runaway cost scenario (where models are not scaled down after test), which could have resulted in annualized costs in excess of $500k.
From a certain angle, this has mostly been an article about how it took us three years to write a pretty standard web app. The app isn’t the point, though. The story is really about paying attention to the needs of our ML users and to the scale of their work within Etsy, and above all about resisting premature optimization. Over the years we’ve moved from meeting the basic technical requirements of an ML platform to building a complete product for it. But we never aimed at a product, not till it became necessary, and so we were able to avoid getting ahead of ourselves.
The goals of the ML platform team have broadened now that Barista is where it is. We continue to try to enable faster experimentation and easier deployment. The consensus of our ML practitioners is that they have the tools they need, but that our greatest area of opportunity is to improve in the cohesiveness of our suite of services - most importantly, automation. And that’s where we’re investing now: in tooling to provide optimal infrastructure settings for model deployments, for instance, so we can reduce tuning time in serving them and further minimize our cloud costs. Our ML practice continues to grow, both in number of models and team size, and our platform is going to have to continue to grow to keep up with them.


