
How We Built a Multi-Task Canonical Ranker for Recommendations at Etsy

There are more than 100 million unique listings on Etsy, so we provide buyers recommendations to help them find that one special item that stands out to them. Recommendations are ubiquitous across Etsy, tailored for different stages of a user's shopping mission. We call each recommendation set a module, and there are hundreds of them both on the web and on mobile apps. These help users find trending items, pick up shopping from where they left off, or discover new content and interests based on their prior activity.
Modules in an enterprise-scale recommendation system usually work in two phases: candidate set selection and candidate set ranking. In the candidate set selection phase, the objective is to retrieve a small set of relevant items out of the entire inventory, as quickly as possible. The second phase then ranks the items in the candidate set using a more sophisticated machine learning model, typically with an emphasis on the user's current shopping mission, and decides on the best few items to offer as recommendations. We call these models rankers and that's the focus of this post.
Rankers score candidate items for relevance based on both contextual attributes, such as the user's recent purchases and most clicked categories, as well as item attributes, such as an item's title and taxonomy. (In machine learning we refer to such attributes as features.) Rankers are optimized against a specific user engagement metric–clickthrough rate, for example, or conversion rate–and trained on users' interactions with the recommendation module, which is known as implicit feedback.
Etsy has historically powered its recommendation modules on a one-to-one basis: one ranker for each module, trained exclusively on data collected from that module. This approach made it easy to recommend relevant items for different business purposes, but as we got into the hundreds of modules it became burdensome. On the engineering side, the cost of maintaining and iterating on so many rankers, running hundreds of daily pipelines in the process, is prohibitive. And as it becomes harder to iterate, we could lose opportunities to incorporate new features and best practices in our rankers. Without a solution, eventually the quality of our recommendations could degrade and actually do harm to the user experience.
To address this potential problem, we pivoted to what we call canonical rankers. As with single-purpose rankers, these are models optimized for a particular user-engagement metric, but the intention is to train them so that they can power multiple modules. We expect these rankers to perform at least on par with module-specific rankers, while at the same time being more efficient computationally, and less costly to train and maintain.
A Canonical Frequency Ranker
We want Etsy to be not just an occasional stop for our users but a go-to destination, and that means paying attention to what will inspire future shopping missions after a user is finished with their current one.
Our first canonical ranker was focused on visit frequency. We wanted to be able to identify latent user interests and surface recommendations that could expose a user to the breadth of inventory on Etsy at moments that might impact a decision to return to the site: for example, showing them complementary items right after their purchase, to suggest a new shopping journey ahead.
Data and goal of the model
Compared to metrics like conversion rate, revisit frequency is difficult to optimize for: there are no direct and immediate signals within a given visit session to indicate that a buyer is likely to return. There are, however, a multitude of ways for an Etsy user to interact with one of our items: they can click it, favorite it, add it to a collection or to a shopping cart, and of course they can purchase it. Of all of these, data analysis suggests that favoriting is most closely related to a user's intention to come back to the site, so we decided that our ranker would optimize on favorite rate as the best available surrogate for revisit frequency.
Favoriting doesn't always follow the same pattern as purchasing, though. And we needed to be wary of the possibility that favorites-based recommendations, not being closely enough related to what a user wanted to buy in their current session, might create a distraction and could actually jeopardize sales. It would be important for us to keep an eye on purchase rate as we developed our frequency ranker.
We also had to find appropriate modules to provide training data for the new ranker. There are a lot of them, on both mobile and web, and they appear in a lot of different user contexts. Most mobile app users are signed in, for example, while a large proportion of desktop users aren't. Interaction patterns are different for different modules: some users land on an item page via external search, or from a Google ad, and they tend to look for specific items, whereas habitual mobile app users are more exploratory. It was important for us that the few modules we trained the frequency ranker on should be as representative as possible of the data generated by these many different modules occurring on many different pages and platforms. We wanted to be confident that our ranker would really be canonical, and able to generalize from its training set to power a much wider range of modules.
Model structure
The requirement that our ranker should optimize for favorites, while at the same time not reducing purchase rate, naturally lent itself to a multi-task learning framework. For a given item we want to predict both the probability of the item being favorited and that of it being purchased. The two scores are then combined to produce the final ranking score. This sort of framework is not directly supported by the tree-based models that have been powering Etsy's recommendations in the past. However, neural models have many advantages over tree-based models and one of them is their ability to handle multi-task architectures. So it was a natural call to build our frequency ranker on a neural model.
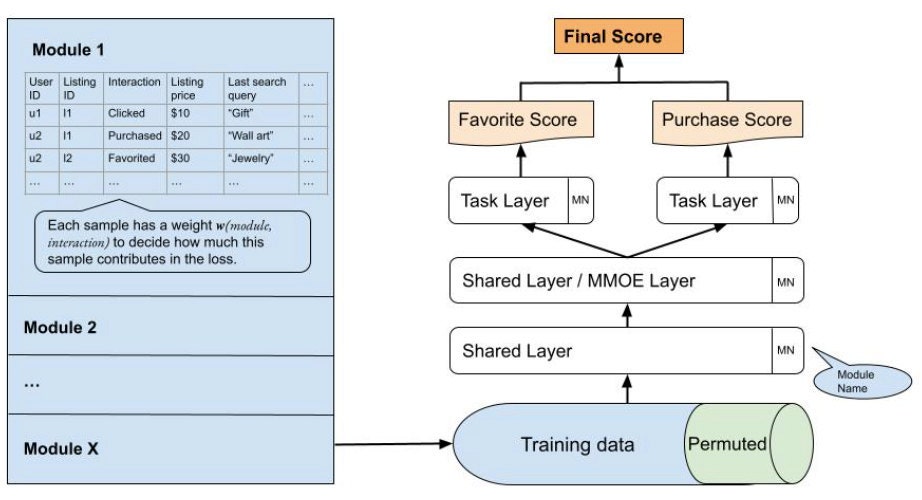
Favoriting and purchasing are obviously not completely unrelated tasks, so it is reasonable to assume that they share some common factors. This assumption suggests a shared-bottom structure, as illustrated on the right in the figure below: what the tasks have in common is expressed in shared layers at the bottom of the network, and they diverge into separate layers towards the top. A challenge that arises is to balance the two tasks. Both favorites and purchases are positive events, so sample weights can be assigned in both the loss function computation and the final score step. We devoted a lot of manual effort to finding the optimal weights for each task, and this structure became our first milestone.
The simple shared-bottom structure proved to be an efficient benchmark model. To improve the model's performance, we moved forward with adding an expert layer following the Multi-gate Mixture Model of Experts (MMOE) framework proposed by Zhao et al. In this framework, favorites and purchases have more flexibility to learn different representations from the embeddings, which leads to more relevant recommendations with little extra computation cost.
Building a canonical ranker
In addition to using data from multiple modules, we also took training data and model structure into account when developing the canonical ranker. We did offline tests of how a naive multi-task model performed on eight different modules, where the training data was extracted from only a subset of them. Performance varied a lot, and on several modules we could not achieve parity against the existing production ranker. As expected, modules that were not included in the training data had the worst performance. We also observed that adding features or implementing an architectural change often led to opposite results on different modules. We took several steps to address these problems:
- We added a feature, module_name, representing which module each sample comes from. Given how much patterns can vary across different modules, we believe this is a critical feature, and we manually stack it in each layer of the neural net.
- It’s possible that the module_name passed to the ranker during inference is not one that it saw during training. (Remember that we only train the model on data from a subset of modules.) We account for this by randomly sampling 10% of the training data and replacing the module_name feature with a dummy name, which we can use in inference to cover that training gap when it occurs.
- User segments distribution and user behaviors vary a lot across modules, so it’s important to keep a balance of training data across different user segments. We account for this during training data sampling.
- We assign different weights to different interaction types, (e.g., impressions, clicks, favorites, and purchases), and the weights may vary depending on module. The intuition is that the correlation between interactions may be different across modules. For example, click may show the same pattern as favorite on module X, but a different pattern on module Y. To help ensure that the canonical ranker can perform well on all modules, we carefully tune the weights to achieve a balance.
Launching experiments
After several iterations, including pruning features to meet latency requirements and standardizing the front-end code that powers recommendation modules, in Q2 of 2022 we launched the first milestone ranker on an item page module and a homepage module. We observed as much as a 12.5% improvement on module-based favorite NDCG and significant improvements on the Etsy-wide favorite rate. And though our main concern was simply to not negatively impact purchases, we were pleased to observe significant improvements on purchase metrics as well as other engagement metrics.
We also launched experiments to test our ranker on a few other modules, whose data are not used during training, and have observed that our ranker outperformed the module-specific rankers in production. These observations suggest that the model is in fact a successful canonical ranker. In Q3, we launched our second milestone model, which proved to be better than the first one and improved engagement even further. As of now, the ranker is powering multiple modules on both web and app, and we anticipate that it will be applied in more places.
For machine learning at Etsy, the frequency ranker marks a paradigm shift in how we build recommendations. From the buyer's perspective, not only does the ranker provide more personalized recommendations, but employing the same ranker across multiple modules and platforms also helps guarantee a more consistent user experience.
Moving forward, we’ll continue iterating on this ranker to improve our target metrics, making the ranker more contextual and testing other novel model architectures.
Acknowledgements
Thanks Davis Kim and Litao Xu for engineering support of the work and Murium Iqbal for internal review of this post. Special thanks to folks in recs-platform, feature-system, ml-platform and search-ranking.


