
Turn Your DB Into A ChatGPT Plugin With Census And Fly
We’ve added support for ChatGPT’s Retrieval Plugin
If you managed to keep up with the absolute deluge of LLM news last week, you saw OpenAI announce ChatGPT plugins. If you were paying very close attention, you might have also spotted their open-source ChatGPT Retrieval Plugin example. If you missed it, it's worth a look; amongst many things, it happens to be one of the nicest example code projects we've seen in a long while. It's also a very simple service, so we quickly built a new connector.
As of today, you can now use Census and Fly to load any of your data into a Retrieval Plugin instance, and query it from ChatGPT. We’ll show you the steps to quickly spin this up yourself with entirely free plans.
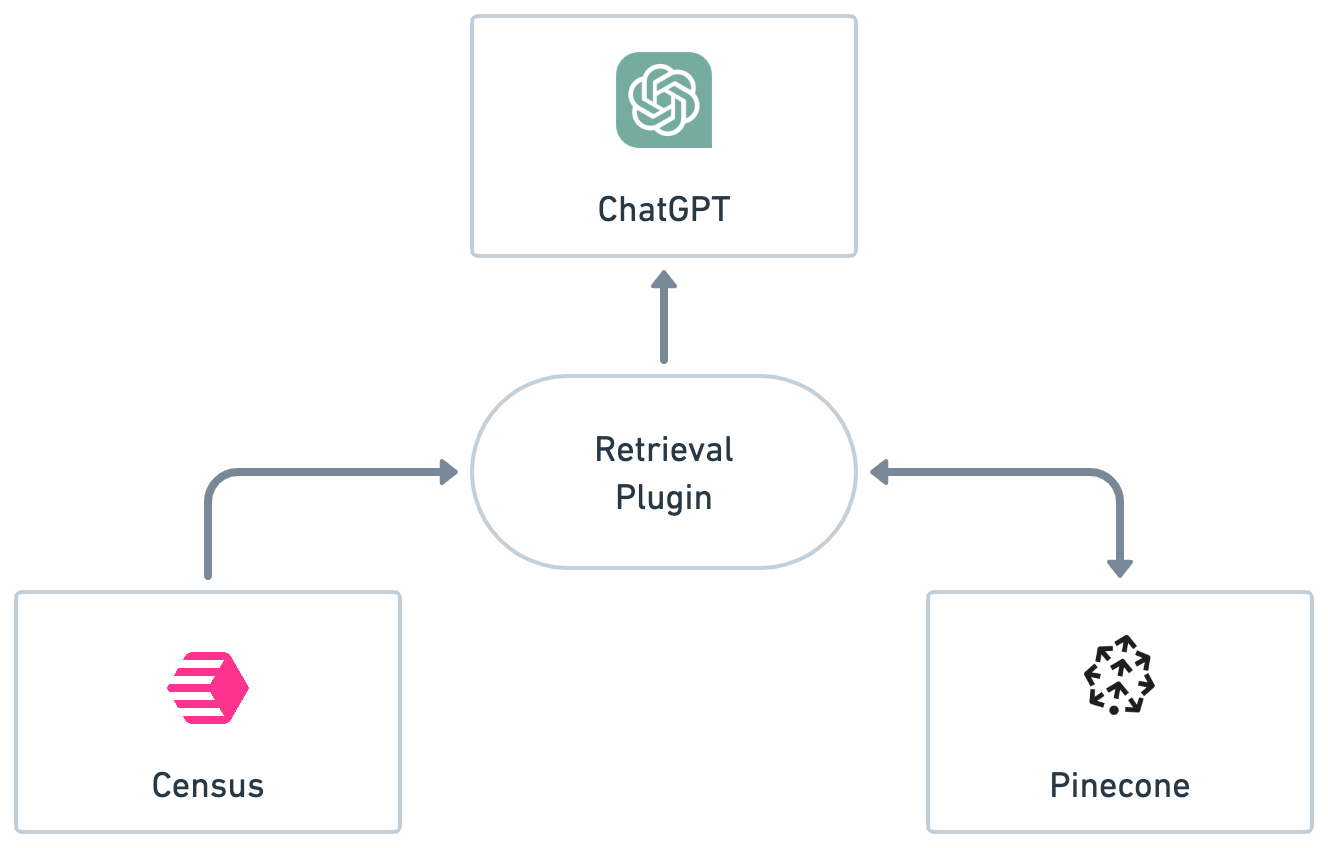
First, let’s take a look at what the Retrieval Plugin is and how it works.
How the Retrieval Plugin works
The Retrieval Plugin example code is a lightweight server that actually performs two separate functions:
Acts as a document loader into the chosen vector database
Acts as a natural language query API “bridge” from the vector store to Chat GPT
First, the document loader is truly an ETL pipeline. Census helps with the Extract in this case, passing it to the Retrieval Plugin’s /upsert endpoint. From there, the plugin transforms the document into an embedding encoding using OpenAI’s API and then loads it into a vector database. Embeddings are a fascinating topic in their own right and using them this way essentially allows for fast “semantic search”, or looking up data that has similar semantic meaning to the query.
Which brings us to the second part of the plugin, the /query endpoint. ChatGPT uses two publicly accessible files to understand how and when to query a given Retrieval Plugin.
ai-plugin.json - which defines the type of data this Retrieval Plugin stores as well as things like the authentication method.
openapi.yaml - which defines the structure of the API (in particular the document metadata) itself.
Don’t let the documentation fool you. This isn’t like other API integrations you’ve written. ChatGPT evidently just reads and understands the natural language description, will similarly send a natural language request, and then “read” the response and determine how/when to use it to answer the original user question. Though the plugin speaks json, nearly everything going on here is just textual understanding.
And as a result, it’s incredibly easy to run your own so let’s stand one up.
Running your own Retrieval Plugin
You’ll need four services
Open AI w/ a paid API key - The Retrieval Plugin uses this to generate the embeddings to send to Pinecone
Pinecone - Easy Vector DB to back your plugin - Free plan is fine to start
Fly.io - Absolute easiest way to run a docker image - Free plan is fine to start
Census - Connects your SQL data to your new Retrieval Plugin - Free works here too
1. Get API details from OpenAI and Pinecone
For OpenAI, you’ll just get an API key and make sure that you have billing enabled.
For Pinecone, you’ll need an API key and the name of the environment. You’ll also need to name your index (whatever you like as long as it’s alphanumeric or dashes) but the plugin will take care of creating it for you so don’t need to set it up in Pinecone.
2. Fly.io
We’ll use Fly to run the Docker-based image because it’s dead simple to get started. Here you can follow OpenAI’s excellent instructions. A couple things to keep in mind
Generate a Bearer Token, the default auth option of the Retrieval Plugin. This will be the token Census uses to communicate with your instance, as well as ChatGPT so it should be a secret you only share with those you want to give access to.
When running
flyctl launch, you don’t need any default Fly databases and don’t deploy immediately because you’ll want to do two things first:Set up the following environment variables
Take the returned hostname add it to
ai-plugin.json
Use
flyctl secretsor Fly’s admin UI to set the following variables
DATASTORE=pinecone
BEARER_TOKEN=<INSERT_YOUR_GENERATED_TOKEN
OPENAI_API_KEY=<INSERT_YOUR_OPENAI_KEY_HERE>
PINECONE_API_KEY=<INSERT_YOUR_PINECONE_KEY_HERE>
PINECONE_ENVIRONMENT=<INSERT_YOUR_PINECONE_ENVIRONMENT_HERE>
PINECONE_INDEX=<INDEX_NAME_OF_YOUR_CHOICE>Now you should be ready to run
flyctl deploy
Once you’ve deployed, you should be able to visit https://<your-app>.fly.dev/openapi.json
3. Census
Now open up Census and add a new ChatGPT Retrieval Plugin destination.
As part of setup, you’ll need to provide Census with your hostname and the bearer token so it can upload on your behalf.
Next, you’ll want to create a SQL query that extracts fields ChatGPT expects from your data. Retrieval Plugin’s default object model looks like the following:
{
"id": "...unique document id...",
"text": "Any raw text to be searched over",
"metadata": {
"source": "email",
"source_id": "...",
"url": "...",
"created_at": "...",
"author": "..."
}
}text is a catch all field for anything you’d like to be searchable and so you may actually want to concatenate a number of your record fields together to make a variety of things searchable by ChatGPT. The only two fields that are required are id and text but you can optionally include any of the metadata fields.
With your model ready, create a sync to your plugin destination and run it. Pinecone + OpenAI are very fast and your data should be ready immediately. If you’d like to test that your data arrived, you can use the /query endpoint to find records
curl -X "POST" "https://<your-hostname>.fly.dev/query" \\
-H 'Authorization: Bearer <your-bearer-token>' \\
-H 'Content-Type: application/json; charset=utf-8' \\
-d $'{
"queries": [
{
"query": "A natural language query that would make sense for your data",
"top_k": 3
}
]
}'4. ChatGPT
Of course, the real test is within ChatGPT. Unfortunately, they’re still early in the Plugins rollout so you may not have access yet. But rest assured, as soon as you do, all you’ll need to do is add your new Retrieval Plugin with the Bearer token. ChatGPT should be able to fly from there!
What’s next
We’re all waiting on the edge of our seats for Plugins, but so much is happening in the wider LLM space. Expect to see even more powerful ways to explore and analyze data without having to know the underlying data structure. It’s obvious we’re only in the earliest days on how LLMs will help individuals and businesses make sense of their data, so the only thing that’s clear is that we’ll continue to see even more compelling use come as people start to adopt it.
Looking forward to building the future with you all!
P.S. Help us make these tools. We’re hiring. Come work with us!