In this blog we shall demonstrate how to start with a pre-trained Yolo (You only look once) V4 end-to-end one-stage object detection model (trained on MS COCO dataset) and train it to detect a custom object (Raccoon).
Dataset Description / Exploration
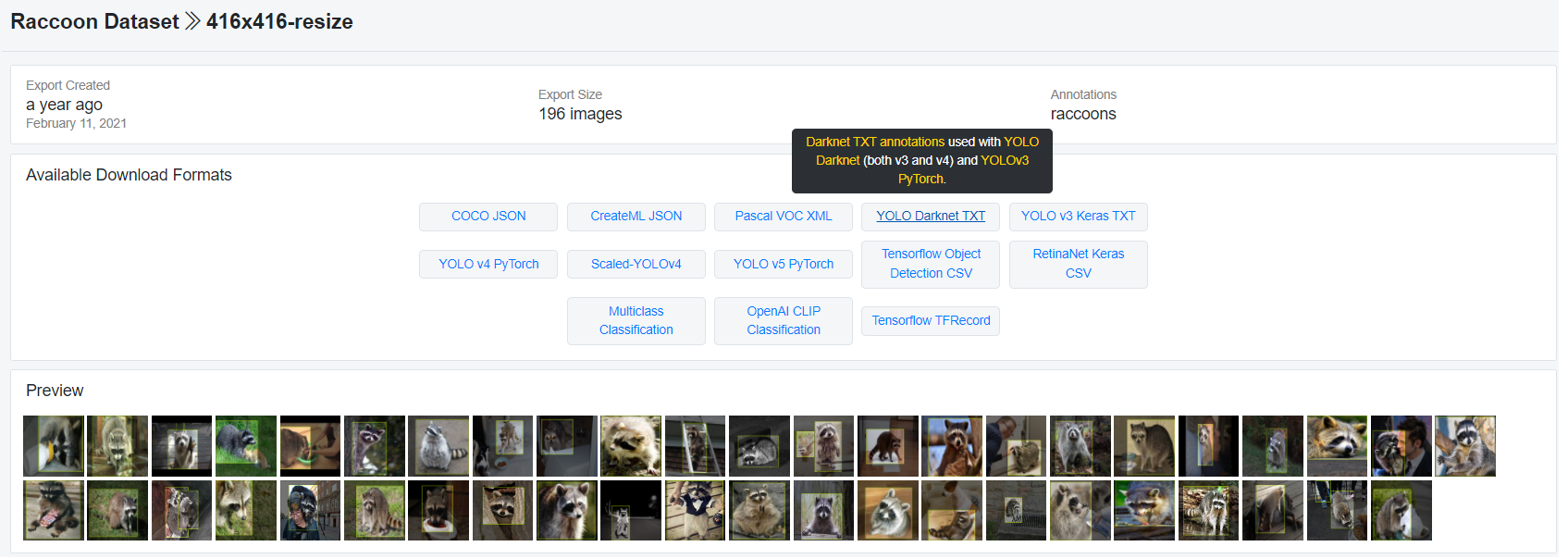
- We shall use the Raccoon Dataset: a Roboflow Public object Detection dataset, available
here: https://public.roboflow.com/objectdetection/raccoon - The dataset contains 196 raccoon images of size, as shown in the next figure:

- Roboflow allows to download the annotated images (with bounding boxes for the object Raccoon to be detected) in different formats, here we shall use darknet text format for the bounding box annotations, which can be used for both YOLO V3 and V4, as shown in the next figure.
- The following figure shows an image and the corresponding annotation text, denoting the position of the bounding box for the Raccoon object in the image. It will be used to firther train the YOLO-V4 model, to make it able to detect the custom object Raccoon.

- In the above annotation, the first two coordinates represent the center of the bounding box and the next two represent the width and height of the bounding box, respectively.
- From the above representation, the bounding box left, top and right bottom
coordinates can be computed as follows:
(x1, y1) = (416 × 0.3790 − 416×0.4904 / 2, 416 × 0.4796 − 416×0.7115 / 2) ≈ (56, 52)
(x2, y2) = (416 × 0.3790 + 416×0.4904 / 2, 416 × 0.4796 + 416×0.7115 / 2) ≈ (260, 348)
the corresponding bounding box can be drawn as shown in the next figure:

Objective & Outline
- The original YOLO-v4 deep learning model being trained on MS COCO dataset, it can detect objects
belonging to 80 different classes. Unfortunately, those 80 classes don’t include Raccoon, hence, without explicit training the pre-trained model will not be able to identify the Raccoons from the image dataset. - Also, we have only 196 images of Raccoon, which is a pretty small number, so it’s not feasible to train the YOLO-V4 model from scratch.
- However, this is an ideal scenario to apply transfer learning. Since the task is same, i.e., object
detection, we can always start with the pretrained weights on COCO dataset and then train the model on our images, starting from those initial weights. - Instead of training a model from scratch, let’s use pre-trained YOLOv4 weights which have been trained up to 137 convolutional layers. Since the original model was trained on COCO dataset with 80 classes and we are interested in detection of an object of a single class (namely Raccoon), we need to modify the corresponding layers (in the conig file).
Data cleaning / feature engineering
- Images are normalized to have value in between 0-1. Histogram equalization / contrast stretching can be used for image enhancement. Since this task involves object localization, data augmentation was not used, since it would then require the re-computation of the bounding box.
- No other feature engineering technique was used, since the deep neural net contains so many
convolution layers that automatically generates many different features, the earlier layers with simpler features and later layers more complicated features.
Training with transfer learning – Configuration and hyperparameter settings
- Google colab is to be used to train the model on GPU.
- To start with we need to first clone the darknet source from the following git repository using the following command:
!git clone https://github.com/AlexeyAB/darknet/
- We need to change the Makefile to enable GPU and opencv and run make to create the darknet
executable. - Next we need to download the pre-trained model yolov4.conv.137 and copy it to the right folder, using the following code.
!wget -P build/darknet/x64/ https://github.com/AlexeyAB/darknet/releases/download/darkn
et_yolo_v3_optimal/yolov4.conv.137
- We need to copy the input image / annotation files to the right folders and provide the information for training data to the model, e.g., create a file build/darknet/x64/data/obj.data, that looks like the following:
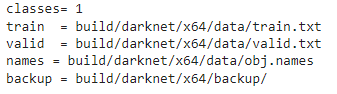
- Here the training and validation text files list the names of the training and validation set images, whereas backup represents the location for saving the model checkpoints while training.
- We need to create a configuration file (yolov4_train.cfg, e.g.,) for training the model on our images. A
relevant portion of the config file (with few of the hyperparameters) to be used for training the YOLO-V4 model is shown below:

- Total number of images we have is 196, out of which 153 of them are used for training and the remaining are used for validation.
- Since the number of training images is small, we keep the batch size hyperparamater (used 3 different values, namely, 16, 8 and 4) for training small too.
- Notice that we need to chaneg the number of classes to (since we are interested to detect a single
object here), as opposed to 80 in the original config file and the number of features as (1+5) x 3 = 18, as shown in the next figure, a part of the config file, again.

- Number of batches for which the model is trained is 2000 (since it is recommended to be at least
200 x num_classes), the model checkpoints stored at batches 500, 1000 and 2000 respectively.
Now we can start training the model on our images, initializing it with the pretrained weights, using the following line of code.
!./darknet detector train build/darknet/x64/data/obj.data cfg/yolov4_train.cfg build/darknet/x64/
yolov4.conv.137 -dont_show
- A few iterations of training are shown in the below figure:
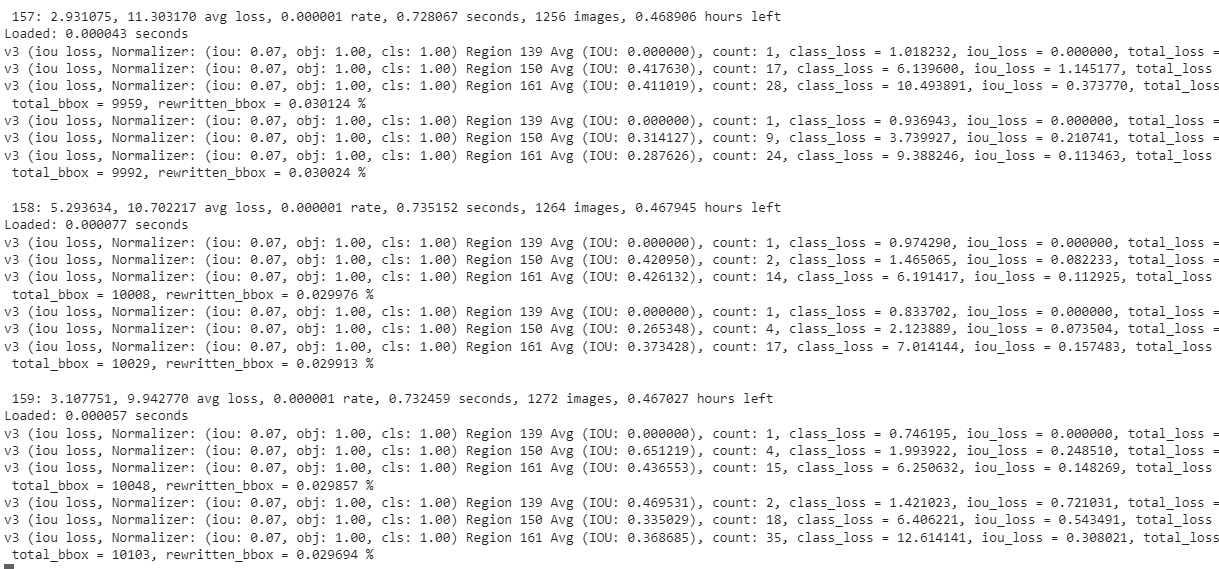
- It takes around ~2 hrs to finish 2000 batches and the final model weights are stored in a file
(yolov4_train_final.weights) on the backup folder provide.
Model Selection and Testing / Prediction
- Since the batch size 8 and subdivision size 2 resulted in higher accuracy (in terms of IOU), the
corresponding model is selected as the best fit model. - The final model checkpoint saved can be used for prediction (with an unseen image test.jpg) with the following line of code:
! ./darknet detector test build/darknet/x64/data/obj.data cfg/yolov4_train.cfg build/darknet/x64/backup/
yolov4_train_latest.weights -dont_show test.jpg
- Around ~500 test images with raccoons were used for custom object detection with the model trained. The following figures show the custom objects (Raccoons) detected with the model on a few unseen images.



The next animation shows how the racoons are detected with the model:

Summary
- With a relatively few number of iterations and a small number of training images we could do a descent job for detecting custom objects using transfer learning.
- The YOLO model’s advantage being its speed (since a one-stage object detection model), starting with weights pretrained on MS-COCO for object detection followed by transfer learning one can detect custom objects with a few hours of training.
Next steps
We obtained a few false positives and false negatives with the model trained. To improve the performance of the model,
- We can train the model for more batches (~10k)
- Increase the input images with data augmentation + re-annotation
- Tune many of the hyperparameters (momentum, decay etc.) of the model
