This past August, I was looking at an online SQL tutorial. One of the sessions in it featured the
BETWEEN predicate, which brought back some memories. In the early days of SQL on the ANSI X3H2 Database Standards Committee, we created the BETWEEN predicate. We wanted the SQL language to sound a bit like English and have shorthand terms for common coding situations. Many of our keywords were stolen from other programming languages or deliberately chosen so that they were not likely to be confused with data elements. The original syntax for the between predicate looks like this:
|
1 2 3 |
BETWEEN::= <test_expression> [NOT] BETWEEN <begin_expression> AND <end_expression> |
The BETWEEN predicate specifies the inclusive range to test the expression values. The range is defined by boundary expressions with the AND keyword BETWEEN them. Naturally, all the expressions in BETWEEN predicate must be the same data type or cast to it, as in the case of any comparison predicate. This predicate Is defined as a shorthand for:
|
1 2 |
(<test_expression> >= <begin_expression> AND <test_expression> <= <end_expression>) |
And the negated version of the predicate
|
1 |
<test_expression> NOT BETWEEN <begin_expression> AND <end_expression> |
is equal to:
|
1 |
NOT (<test_expression> BETWEEN <begin_expression> AND <end_expression>) |
The grammar for SQL is deliberately picked to be LALR(1). If you don’t remember that from your compiler writing classes, don’t feel bad. It means that SQL can have a little more complicated grammar than many programming languages to sprinkle keywords In places a little more like natural English. It’s important to notice that the BETWEEN predicate uses a closed interval, which includes the endpoints of the range. However, the NOT BETWEEN excludes them.
|
1 |
<test_expression> NOT BETWEEN <begin_expression> AND <end_expression> |
is equivalent to
|
1 2 |
(<test_expression> < <begin_expression> OR <test_expression> > <end_expression>) |
At some point in these early days, one of the committee members proposed changing the syntax and creating what would now be called a “symmetric BETWEEN” as the default definition. This proposal passed because committees love proposals. Only Microsoft implemented this feature in their Access tabletop database. All the other vendors ignored it, and the proposal was rescinded at the next committee meeting.
But proposals with extended features seem to keep coming back to life. The current ANSI/ISO standard syntax is:
|
1 2 |
<test_expression> [NOT] BETWEEN [SYMMETRIC | ASYMMETRIC] <begin_expression> AND <end_expression> |
The keyword ASYMMETRIC has the original functionality, and it is optional. The BETWEEN SYMMETRIC syntax is like BETWEEN except that there is no requirement that the argument to the left of the AND be less than or equal to the argument on the right. Well, not entirely: officially, the <begin_expression> is the minimum, and the <end_expression> is the maximum. This transformation converts a SYMMETRIC BETWEEN into a regular old vanilla BETWEEN.
Intervals in the ISO data model
Several ISO standards deal with the concepts of intervals. From a mathematical viewpoint, the kinds of intervals you can have are (1) Closed, (2) Opened, (3) Half open high, and (4) Half open low. A closed interval includes both the endpoints, like the range in the BETWEEN predicate. An open interval excludes both the endpoints of the range, like the NOT BETWEEN predicate. The half open intervals are open on either the high-end or the low end of the interval range.
A half open interval on the high-end is how ISO models time. We talk about “24-hour time” Or “military time,” but the truth is a day is defined as an interval from 00:00:00 up to 23:59:59.999.. at whatever precision can be measured. If you try and put in “24:00:00 Hrs”, DB2 and other databases will automatically convert it to 00:00:00 Hrs of the next day. Think of it as being like converting a person’s height from 5’18” to 6’6” instead. These conventions get even stranger when you look at how different countries and cultures handle times greater than one day. If an event in Japan runs past midnight, they simply add more hours to the event. For example, an event that ran past midnight might be shown as “25:15:00 Hrs.”
The advantage of the half open interval is easy to see in the ISO 8601 standards, which define how temporal data is represented. You are always sure when an event starts, even if you’re not sure when it will end, so you can use a NULL to mark the end of an event that is in process. This NULL can be coalesced to a meaningful value. For example, sometimes it might make sense to use COALESCE(interval_final_timestamp, CURRENT_TIMESTAMP) To figure out the duration of the interval at exactly the moment the query is invoked. Other times, you might want to use COALESCE(interval_final_timestamp, legally_defined_stop_timestamp).
The BETWEEN predicate is not just used for timestamps. It works perfectly well for numeric ranges and text, too. Numeric ranges can be used to throw things into buckets, which looks reasonably obvious until the three parameter values are of different numeric types. Now you have to consider rounding and casting errors. Even worse, if the parameters are character data with different correlations. As a generalization, you really need to make sure that all three parameters are of the same type. In fact, ranges and text data can get so complicated, I’m just going to ignore them. Let’s just look at numeric ranges.
Report cards
A classic example of reducing values into ranges is converting grades from numeric totals or percentages to a letter grade. The usual convention is that a score in the 90s is an “A”, a score in the 80s is a “B”, a score in the 70s is a “C”, a score in the 60s is a “D” and anything below that is an “F”. I’m choosing to ignore plus or minus options on the letters.
The CASE expression in SQL is executed from left to right, and the first WHEN clause that tests TRUE returns the value in its THEN clause. This means that the order in which you write your tests will control how it executes; not all programming languages work this way. In effect, we have hard-coded half open intervals.
|
1 2 3 4 5 6 |
CASE WHEN score >= 90.000 THEN ‘A’ WHEN score >= 80.000 THEN ‘B’ WHEN score >= 70.000 THEN ‘C’ WHEN score >= 60.000 THEN ‘D’ ELSE ‘F’ END |
It is important to notice that this expression will handle somebody who has more than 100 points to qualify as an “A” student. In this example, that’s probably what was intended for extra credit, but this might indicate an error in the data in other schemes. Likewise, a score of zero might be a data error. Then, of course, because this is SQL, what would a NULL mean? Perhaps it indicates an incomplete? A general rule of thumb is to design for the extreme cases but tuning for the most expected cases.
The OVERLAPS() predicate
The OVERLAPS predicate is part of the SQL Standards but not part of SQL Server. This predicate is defined only for temporal data and is based on temporal intervals. Yes, there is a temporal interval type in Standard SQL. Before getting into it, we need to back up and discuss something known as Allen’s operators. They are named after J. F. Allen, who defined them in a 1983 research paper on temporal intervals. The basic model has two temporal intervals, expressed as ordered pairs of start and termination timestamps (S1, T1) and (S2, T2).
Here are the base relations between two intervals, as timelines.
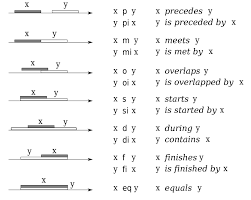
SQL did not add all 13 relationships, but we decided that an overlaps predicate would be the most useful.
The result of the <OVERLAPS predicate> is formally defined as the result of the following expression:
|
1 2 3 |
(S1 > S2 AND NOT (S1 >= T2 AND T1 >= T2)) OR (S2 > S1 AND NOT (S2 >= T1 AND T2 >= T1)) OR (S1 = S2 AND (T1 <> T2 OR T1 = T2)) |
where S1 and S2 are the starting times of the two time periods and T1 and T2 are their termination times. The rules for the OVERLAPS() predicate sound like they should be intuitive, but they are not. The principles that we wanted in the Standard were:
1. A time period includes its starting point but does not include its end point. We have already discussed this model and its closure properties.
2. If the time periods are not “instantaneous,” they overlap when they share a common time period.
3. If the first term of the predicate is an INTERVAL, and the second term is an instantaneous event (a <datetime> data type), they overlap when the second term is in the time period (but is not the end point of the time period). That follows the half-open model.
4. If the first and second terms are instantaneous events, they overlap only when they are equal.
5. If the starting time is NULL and the finishing time is a <datetime> value, the finishing time becomes the starting time, and we have an event. If the starting time is NULL and the finishing time is an INTERVAL value, then both the finishing and starting times are NULL.
Please consider how your intuition reacts to these results when the granularity is at the YEAR-MONTH-DAY level. Remember that the day begins at 00:00:00 Hrs.
|
1 2 3 4 |
(today, today) OVERLAPS (today, today) = TRUE (today, tomorrow) OVERLAPS (today, today) = TRUE (today, tomorrow) OVERLAPS (tomorrow, tomorrow) = FALSE (yesterday, today) OVERLAPS (today, tomorrow) = FALSE |
Contiguous temporal intervals with DDL
Alexander Kuznetsov wrote this idiom for History Tables in T-SQL, but it generalizes to any SQL. It builds a temporal chain from the current row to the previous row with a self-reference. This is easier to show with code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
CREATE TABLE Tasks (task_id INTEGER NOT NULL, -- makes sense in your data task_score CHAR(1) NOT NULL, -- whatever makes sense in your data previous_end_date DATE, -- null means first task current_start_date DATE DEFAULT CURRENT_TIMESTAMP NOT NULL, CONSTRAINT previous_end_date_and_current_start_in_sequence CHECK (prev_end_date <= current_start_date) DEFERRABLE INITIALLY IMMEDIATE, current_end_date DATE, -- null means unfinished current task CONSTRAINT current_start_and_end_dates_in_sequence CHECK (current_start_date <= current_end_date), CONSTRAINT end_dates_in_sequence CHECK (previous_end_date <> current_end_date), PRIMARY KEY (task_id, current_start_date), UNIQUE (task_id, previous_end_date), -- null first task UNIQUE (task_id, current_end_date), -- one null current task FOREIGN KEY (task_id, previous_end_date) -- self-reference REFERENCES Tasks (task_id, current_end_date)); |
Well, that looks complicated! Let’s look at it column by column. Task_id explains itself. The previous_end_date will not have a value for the first task in the chain, so it is NULL-able. The current_start_date and current_end_date are the same data elements, temporal sequence, and PRIMARY KEY constraints we had in the simple history table schema.
The two UNIQUE constraints will allow one NULL in their pairs of columns and prevent duplicates. Remember that UNIQUE is NULL-able, not like PRIMARY KEY, which implies UNIQUE NOT NULL.
Finally, the FOREIGN KEY is the real trick. Obviously, the previous task has to end when the current task started for them to abut, so there is another constraint. This constraint is a self-reference that makes sure this is true. Modifying data in this type of table is easy but requires some thought.
There is just one little problem with that FOREIGN KEY constraint. It will not let you put the first task into the table. There is nothing for the constraint to reference. In Standard SQL, we can declare constraints to be DEFERABLE with some other options. The idea is that you can turn a constraint ON or OFF during a session so the database can be in a state that would otherwise be illegal. But at the end of the session, all constraints have to be TRUE or UNKNOWN.
When a disabled constraint is re-enabled, the database does not check to ensure any existing data meets the constraints. You will want to hide this in a procedure body to get things started.
BETWEEN
Please notice that the OVERLAPS and BETWEEN predicates work with static intervals, but there are also dynamic predicates for data. The LEAD and LAG operators view the rows as representing points in time or in a sequence, but that is a topic for another article.
If you liked this article, you might also like A UNIQUE experience

Load comments