
The simplest form of parallel computing is what’s known as “embarrassingly” parallel processes. These processes involve fully independent runs of a model or script where little or no communication is needed across parallel processes. A common example is Monte Carlo evaluation, when we run a model over an ensemble of inputs. To parallelize an embarrassingly parallel application we simply need to send a set of commands to the cluster telling it to run each sample on a different core (or set of cores). For small applications, this can be done by submitting each run individually. For larger applications, SLURM Job Arrays (which are nicely detailed in Antonia’s post, here) can efficiently batch large number of function calls to independent computing cores. While this method is efficient and effective, I find it sometimes can be hard to keep track of, as you may be submitting tens or hundreds of jobs at a time. An alternative approach to submitting embarrassingly parallel tasks is to utilize MPI with Python to dispatch and organize jobs.
I like the MPI / Python combo because it consolidates all parallel applications into a single job, meaning you have one job to keep track of on a cluster at a time, and one output file generated by the batch set of model runs. I also find Python slightly easier to edit and debug than Bash scripts (which are used to create job arrays). Additionally, it’s very easy to assign each computing core a set of function evaluations to run (this can also be done with Job arrays, but again, I find Python easier to work with). Though Python is the language used to coordinate parallel tasks, we can use it to parallelize code in any language, as I’ll demonstrate below.
In this post I’ll first provide some background on MPI and its Python implementation, mpi4py. Next I’ll provide an example I’ve developed to demonstrate how to batch run a Matlab code on a cluster. The examples presented here are derived from some of Bernardo’s code in his post on Parallel programming in C/C++, which you can find here.
A very light introduction to MPI
MPI stands for “Message Passing Interface” and is the standard library for distributed memory parallelization (for background, see this post). To understand how MPI works, it’s helpful to define some of it’s basic components.
- Tasks: I’ll use the term task to define a processor (or group of processors) assigned to perform a specific set of instructions. These instructions may by a single evaluation of a function, or a set of function evaluations
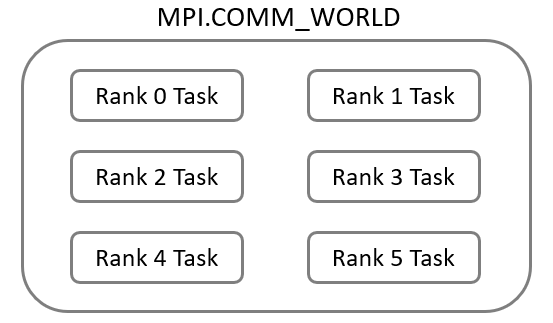
- Communicators: A communicator is a group of MPI task units that are permitted to communicate with each other. In advanced MPI applications you may have multiple communicators, but for embarrassingly parallel applications we’ll only use one. The default communicator is called “MPI_COMM_WORLD” (I don’t know why, if anyone does please feel free to share in the comments), and that’s what I’ll work with here.
- Ranks: Each MPI task is assigned a unique identifier within the communicator called a rank. The processors running each task can access their own rank number, which will play an important role in how we use MPI for embarrassingly parallel applications.
A example schematic of the MPI_COMM_WORLD communicator with six tasks and their associated ranks is shown below.
mpi4py
MPI is implemented in Python with the mpi4py library. When we run an MPI code on a cluster, MPI creates the communicator and assigns each task a rank, then each task unit independently load the script. The processor/s associated with a task can then access their own unique rank.
The following snip of code loads this library, accesses the communicator and stores the rank of the given process:
# load the mpi4py library
from mpi4py import MPI
# access the MPI COMM WORLD communicator and assign it to a variable
comm = MPI.COMM_WORLD
# get the rank of the current process (different for each process on the cluster)
rank = comm.Get_rank()
Example of using mpi4py to batch parallel jobs
Here, I’ll parallelize the submission of a Matlab script called demoScript.m. This script reads an input file from a specific file location and prints out the contents of that file. For example purposes I’ve created 20 input files, each in their own folders. The folders are called “input_sample_0”, “input_sample_1” etc.. Each input_sample folder contains a file called “sample_data.txt”, which contains one line of text reading: “This is data for run <sample_number>”.
All code for this example can be found on Github, here: https://github.com/davidfgold/mpi4py_blog.git
Batching runs of demoScript.m process involves three components:
- Write demoScript.m so that it reads the sample number from the input.
- Write a Python script that will use mpi4py to distribute calls of demoScript.m. Here I’ll call this script “callDemoScript.py”
- Write a Bash script that sets up your MPI run and calls the Python function. Here I’ll call this script “submitDemoScript.sh”
1. demoScript.m
The demo Matlab script is found below. It reads in two arguments that are called from the command line. The first argument is the rank, which will vary for each task, and the second is the sample number, which will specify which input folder to read from.
%%%%%%%%%%%%%%%%%%%%
% demoScript.m
%
% reads an input file from a given sample number (specified via command line)
% prints output from the sample file associated with the sample number
% also prints the rank for demonstration purposes
%%%%%%%%%%%%%%%%%%%%
% read in command line input
arg_list = argv();
rank = arg_list{1,1}; % rank is the first argument
sample = arg_list{2, 1}; % sample number is the second argument
% Create a string that contains the location of the proper sample directory
sample_out = fileread(strcat("input_sample_", sample, "/sample_data.txt"));
% create a string to print the rank number
rank_call = strcat("This is rank_", rank, ", recieving the following input: \n");
% format the output and print
output = strcat(rank_call, sample_out);
fprintf(output)
2. callDemoScript.py
The second component is a Python script that uses mpi4py to call demoScript.m many times across different tasks. Each task will run a number of samples equal to a variable called “N_SAMPLES_PER_TASK” which will be fed to this script when it is called.
'''
callDemoScript.py
Called to batch demoScript.m across multiple MPI tasks
Reads in the total tasks and number of samples per task from command line.
'''
# load necessary libraries
from mpi4py import MPI
import numpy as np
import sys
import os
import time
# locate the COMM WORLD communicator
comm = MPI.COMM_WORLD
# get the number of the current rank
rank = comm.Get_rank()
# read in arguments from the submission script
TOTAL_TASKS = int(sys.argv[1]) # number of MPI processes
N_SAMPLES_PER_TASK = int(sys.argv[2]) # number of runs per/task
# loop through samples assigned to current rank
for i in range(N_SAMPLES_PER_TASK):
sample= rank + TOTAL_TASKS * i
# write the command that will be sent to the terminal (here RUN will replace the {})
terminal_command = "octave-cli ./demoScript.m {} {} ".format(rank, sample)
# write the terminal command to the process
os.system(terminal_command)
# sleep before submitting the next command
time.sleep(1) # optional, for memory intensive submissions
comm.Barrier()
submitDemoscript.sh
The final component is a Bash script that will send this MPI job to the cluster. Here I’ll use SLURM to create 4 MPI tasks across 2 Nodes (each node will have 2 associated task). This will create a total of 4 MPI tasks, and each task will be assigned 5 samples to run.
I wrote this for a local cluster at Cornell, note that I had to load two modules to run Python and a third to run Octave (which is used to call Matlab scripts on Linux). I’ll call the Python script with mpirun, and then specify the total number of MPI tasks before making the function call. The output of the script is printed to a text file called demoOutput.txt
# Set up your parallel runs
SAMPLES_PER_TASK=5 # number of runs for each MPI task
N_NODES=2 # number of nodes
TASKS_PER_NODE=2 # number of tasks per node
TOTAL_TASKS=$(($N_NODES*$TASKS_PER_NODE)) # total number of tasks
# Submit the parallel job
#!/bin/bash
#SBATCH -n $(TOTAL_TASKS) -N $(N_NODES)
#SBATCH --time=0:01:00
#SBATCH --job-name=demoMPI4py
#SBATCH --output=output/demo.out
#SBATCH --error=output/demo.err
#SBATCH --exclusive
module load py3-mpi4py
module load py3-numpy
module load octave/6.3.0
mpirun -np $TOTAL_TASKS python3 callDemoScript.py $TOTAL_TASKS $SAMPLES_PER_TASK > demoOutput.txt
Additional resources
Putting some thought into how you design a set of parallel runs can save you a lot of time and headache. The example above has worked well for me when submitting sets of embarrassingly parallel tasks, but each application will be different, so take the time to find the procedure that works best for you. Our blog and the internet are full of resources that can help you parallelize your code, below are some suggestions:
Performing Experiments on HPC Systems
Scaling experiments: how to measure the performance of parallel code on HPC systems
Parallel processing with R on Windows
How to automate scripts on a cluster
Parallelization of C/C++ and Python on Clusters
Developing parallelised code with MPI for dummies, in C (Part 1/2)
Cornell CAC glossery on HPC terms: https://cvw.cac.cornell.edu/main/glossary
A great MPI tutorial I found online: https://mpitutorial.com/tutorials/
