
zheap has been designed as a new storage engine to handle UPDATE in PostgreSQL more efficiently. A lot has happened since my last report on this important topic, and I thought it would make sense to give readers a bit of a status update – to see how things are going, and what the current status is.
zheap: What has been done since last time
Let’s take a look at the most important things we’ve achieved since our last status report:
- logical decoding
- work on UNDO
- patch reviews for UNDO
- merging codes
- countless fixes and improvements
zheap: Logical decoding
The first thing on the list is definitely important. Most people might be familiar with PostgreSQL’s capability to do logical decoding. What that means is that the transaction log (= WAL) is transformed back to SQL so that it can be applied on some other machine, leading to identical results on the second server. The capability to do logical decoding is not just a given. Code has to be written which can decode zheap records and turn them into readable output. So far this implementation looks good. We are not aware of bugs in this area at the moment.
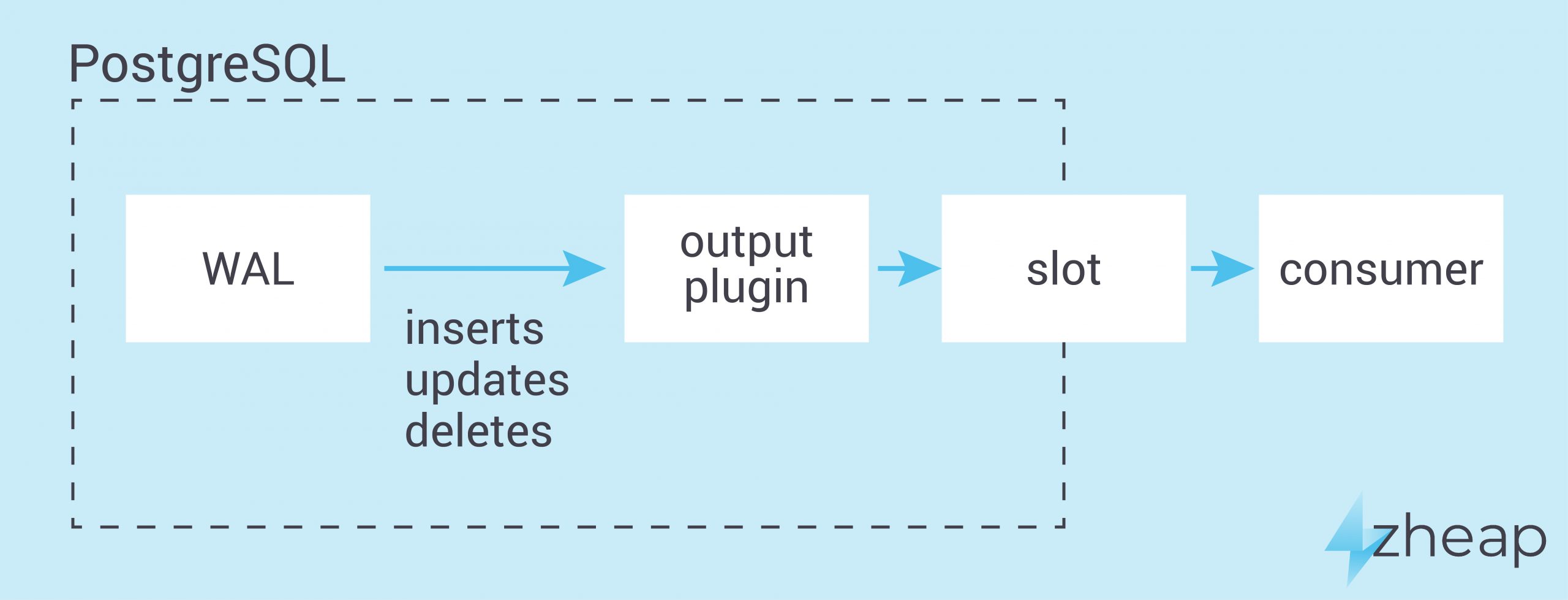
Work on UNDO
zheap is just one part of the equation when it comes to new storage engines. As you might know, a standard heap table in PostgreSQL will hold all necessary versions of a row inside the same physical files. In zheap this is not the case. It is heavily based on a feature called “UNDO” which works similar to what Oracle and some other database engines do. The idea is to move old versions of a row out of the table and then, in case of a ROLLBACK, put them back in .
What has been achieved is that the zheap code is now compatible with the new UNDO infrastructure suggested by the community (which we hope to see in core by version 15). The general idea here is that UNDO should not only be focused on zheap, but provide a generic infrastructure other storage engines will be able to use in the future as well. That’s why preparing the zheap code for a future UNDO feature of PostgreSQL is essential to success. If you want to follow the discussion on the mailing list, here is where you can find some more detailed information about zheap and UNDO.
Fixing bugs and merging
As you can imagine, a major project such as zheap will also cause some serious work on the quality management front. Let’s look at the size of the code:
[hs@node1 zheap_postgres]$ cd src/backend/access/zheap/ [hs@node1 zheap]$ ls -l *c -rw-rw-r--. 1 hs hs 14864 May 27 04:25 prunetpd.c -rw-rw-r--. 1 hs hs 27935 May 27 04:25 prunezheap.c -rw-rw-r--. 1 hs hs 11394 May 27 04:25 rewritezheap.c -rw-rw-r--. 1 hs hs 96748 May 27 04:25 tpd.c -rw-rw-r--. 1 hs hs 13997 May 27 04:25 tpdxlog.c -rw-rw-r--. 1 hs hs 285703 May 27 04:25 zheapam.c -rw-rw-r--. 1 hs hs 59175 May 27 04:25 zheapam_handler.c -rw-rw-r--. 1 hs hs 62970 May 27 04:25 zheapam_visibility.c -rw-rw-r--. 1 hs hs 61636 May 27 04:25 zheapamxlog.c -rw-rw-r--. 1 hs hs 16608 May 27 04:25 zheaptoast.c -rw-rw-r--. 1 hs hs 16218 May 27 04:25 zhio.c -rw-rw-r--. 1 hs hs 21039 May 27 04:25 zmultilocker.c -rw-rw-r--. 1 hs hs 16480 May 27 04:25 zpage.c -rw-rw-r--. 1 hs hs 43128 May 27 04:25 zscan.c -rw-rw-r--. 1 hs hs 27760 May 27 04:25 ztuple.c -rw-rw-r--. 1 hs hs 55849 May 27 04:25 zundo.c -rw-rw-r--. 1 hs hs 51613 May 27 04:25 zvacuumlazy.c [hs@node1 zheap]$ cat *c | wc -l 29696
For those of you out there who are anxiously awaiting a productive version of zheap, I have to point out that this is really a major undertaking which is not trivial to do. You can already try out and test zheap. However, keep in mind that we are not quite there yet. It will take more time, and especially feedback from the community to make this engine production-ready, capable of handling any workload reliably and bug-free.
I won’t go into the details of what has been fixed, but we had a couple of issues including bugs, compiler warnings, and so on.
What has also been done was to merge the zheap code with current versions of PostgreSQL, to make sure that we’re up to date with all the current developments.
Next steps to improve zheap
As far as the next steps are concerned, there are a couple of things on the list. One of the first things will be to work on the discard worker. Now what is that? Consider the following listing:
test=# BEGIN BEGIN test=*# CREATE TABLE sample (x int) USING zheap; CREATE TABLE test=*# INSERT INTO sample SELECT * FROM generate_series(1, 1000000) AS x; INSERT 0 1000000 test=*# SELECT * FROM pg_stat_undo_chunks; logno | start | prev | size | discarded | type | type_header --------+------------------+------+----------+-----------+------+----------------------------------- 000001 | 000001000021AC3D | | 57 | f | xact | (xid=745, dboid=16384, applied=f) 000001 | 000001000021AC76 | | 44134732 | f | xact | (xid=748, dboid=16384, applied=f) (2 rows) test=*# COMMIT; COMMIT test=# SELECT * FROM pg_stat_undo_chunks; logno | start | prev | size | discarded | type | type_header --------+------------------+------+----------+-----------+------+----------------------------------- 000001 | 000001000021AC3D | | 57 | f | xact | (xid=745, dboid=16384, applied=f) 000001 | 000001000021AC76 | | 44134732 | f | xact | (xid=748, dboid=16384, applied=f) (2 rows)
What we see here is that the UNDO chunks do not go away. They keep piling up. At the moment, it is possible to purge them manually:
test=# SELECT pg_advance_oldest_xid_having_undo(); pg_advance_oldest_xid_having_undo ----------------------------------- 750 (1 row) test=# SELECT * FROM pg_stat_undo_chunks; logno | start | prev | size | discarded | type | type_header -------+------------------+------+----------+-----------+------+----------------------------------- 000001 | 000001000021AC3D | | 57 | t | xact | (xid=745, dboid=16384, applied=f) 000001 | 000001000021AC76 | | 44134732 | t | xact | (xid=748, dboid=16384, applied=f) (2 rows) test=# SELECT pg_discard_undo_record_set_chunks(); pg_discard_undo_record_set_chunks ----------------------------------- (1 row) test=# SELECT * FROM pg_stat_undo_chunks; logno | start | prev | size | discarded | type | type_header ------+-------+------+------+-----------+------+------------- (0 rows)
As you can see, the UNDO has gone away. The goal here is that the cleanup should happen automatically – using a “discard worker”. Implementing this process is one of the next things on the list.
Community feedback is currently one of the bottlenecks. We invite everybody with an interest in zheap to join forces and help to push this forward. Everything from load testing to feedback on the design is welcome – and highly appreciated! zheap is important for UPDATE-heavy workloads, and it’s important to move this one forward.
Trying it all out
If you want to get involved, or just try out zheap, we have created a tarball for you which can be downloaded from our website. It contains our latest zheap code (as of May 27th, 2021).
Simply compile PostgreSQL normally:
./configure --prefix=/your_path/pg --enable-debug --with-cassert make install cd contrib make install
Then you can create a database instance, start the server normally and start playing. Make sure that you add “USING zheap” when creating a new table, because otherwise PostgreSQL will create standard “heap” tables (so not zheap ones).
Finally …
We want to say thank you to Heroic Labs for providing us with all the support we have to make zheap work. They are an excellent partner and we recommend checking out their services. Their commitment has allowed us to allocate so many resources to this project, which ultimately benefits the entire community. A big thanks goes out to those guys.
If you want to know more about zheap, we suggest checking out some of our other posts on this topic. Here is more about zheap and storage consumption.