Another nail for the coffin of past effort estimation research
Programs are built from lines of code written by programmers. Lines of code played a starring role in many early effort estimation techniques (section 5.3.1 of my book). Why would anybody think that it was even possible to accurately estimate the number of lines of code needed to implement a library/program, let alone use it for estimating effort?
Until recently, say up to the early 1990s, there were lots of different computer systems, some with multiple (incompatible’ish) operating systems, almost non-existent selection of non-vendor supplied libraries/packages, and programs providing more-or-less the same functionality were written more-or-less from scratch by different people/teams. People knew people who had done it before, or even done it before themselves, so information on lines of code was available.
The numeric values for the parameters appearing in models were obtained by fitting data on recorded effort and lines needed to implement various programs (63 sets of values, one for each of the 63 programs in the case of COCOMO).
How accurate is estimated lines of code likely to be (this estimate will be plugged into a model fitted using actual lines of code)?
I’m not asking about the accuracy of effort estimates calculated using techniques based on lines of code; studies repeatedly show very poor accuracy.
There is data showing that different people implement the same functionality with programs containing a wide range of number of lines of code, e.g., the 3n+1 problem.
I recently discovered, tucked away in a dataset I had previously analyzed, developer estimates of the number of lines of code they expected to add/modify/delete to implement some functionality, along with the actuals.
The following plot shows estimated added+modified lines of code against actual, for 2,692 tasks. The fitted regression line, in red, is:  (the standard error on the exponent is
(the standard error on the exponent is  ), the green line shows
), the green line shows  (code+data):
(code+data):
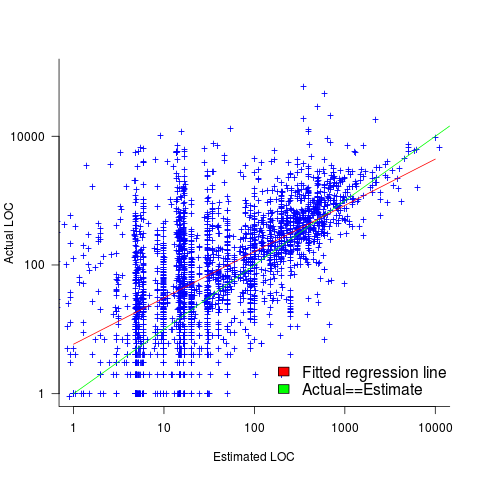
The fitted red line, for lines of code, shows the pattern commonly seen with effort estimation, i.e., underestimating small values and over estimating large values; but there is a much wider spread of actuals, and the cross-over point is much further up (if estimates below 50-lines are excluded, the exponent increases to 0.92, and the intercept decreases to 2, and the line shifts a bit.). The vertical river of actuals either side of the 10-LOC estimate looks very odd (estimating such small values happen when people estimate everything).
My article pointing out that software effort estimation is mostly fake research has been widely read (it appears in the first three results returned by a Google search on software fake research). The early researchers did some real research to build these models, but later researchers have been blindly following the early ‘prophets’ (i.e., later research is fake).
Lines of code probably does have an impact on effort, but estimating lines of code is a fool’s errand, and plugging estimates into models built from actuals is just crazy.
Recent Comments