

 Percona Operator for MySQL based on Percona XtraDB Cluster comes with two different proxies, HAProxy and ProxySQL. While the initial version was based on ProxySQL, in time, Percona opted to set HAProxy as the default Proxy for the operator, without removing ProxySQL.
Percona Operator for MySQL based on Percona XtraDB Cluster comes with two different proxies, HAProxy and ProxySQL. While the initial version was based on ProxySQL, in time, Percona opted to set HAProxy as the default Proxy for the operator, without removing ProxySQL.
While one of the main points was to guarantee users to have a 1:1 compatibility with vanilla MySQL in the way the operator allows connections, there are also other factors that are involved in the decision to have two proxies. In this article, I will scratch the surface of this why.
Operator Assumptions
When working with the Percona Operator, there are few things to keep in mind:
- Each deployment has to be seen as a single MySQL service as if a single MySQL instance
- The technology used to provide the service may change in time
- Pod resiliency is not guaranteed, service resiliency is
- Resources to be allocated are not automatically calculated and must be identified at the moment of the deployment
- In production, you cannot set more than 5 or less than 3 nodes when using PXC
There are two very important points in the list above.
The first one is that what you get IS NOT a Percona XtraDB Cluster (PXC), but a MySQL service. The fact that Percona at the moment uses PXC to cover the service is purely accidental and we may decide to change it anytime.
The other point is that the service is resilient while the pod is not. In short, you should expect to see pods stopping to work and being re-created. What should NOT happen is that service goes down. Trying to debug each minor issue per node/pod is not what is expected when you use Kubernetes.
Given the above, review your expectations… and let us go ahead.
The Plus in the Game (Read Scaling)
As said, what is offered with Percona Operator is a MySQL service. Percona has added a proxy on top of the nodes/pods that help the service to respect the resiliency service expectations. There are two possible deployments:
- HAProxy
- ProxySQL
Both allow optimizing one aspect of the Operator, which is read scaling. In fact what we were thinking was, given we must use a (virtually synchronous) cluster, why not take advantage of that and allow reads to scale on the other nodes when available?
This approach will help all the ones using POM to have the standard MySQL service but with a plus.
But, with it also comes with some possible issues like READ/WRITE splitting and stale reads. See this article about stale reads on how to deal with it.
For R/W splitting we instead have a totally different approach in respect to what kind of proxy we implement.
If using HAProxy, we offer a second entry point that can be used for READ operation. That entrypoint will balance the load on all the nodes available.
Please note that at the moment there is nothing preventing an application to use the cluster1-haproxy-replicas also for write, but that is dangerous and wrong because will generate a lot of certification conflicts and BF abort, given it will distribute writes all over the cluster impacting on performance as well (and not giving you any write scaling). It is your responsibility to guarantee that only READS will go through that entrypoint.
If instead ProxySQL is in use, it is possible to implement automatic R/W splitting.
Global Difference and Comparison
At this point, it is useful to have a better understanding of the functional difference between the two proxies and what is the performance difference if any.
As we know HAProxy acts as a level 4 proxy when operating in TCP mode, it also is a forward-proxy, which means each TCP connection is established with the client with the final target and there is no interpretation of the data-flow.
ProxySQL on the other hand is a level 7 proxy and is a reverse-proxy, this means the client establishes a connection to the proxy who presents itself as the final backend. Data can be altered on the fly when it is in transit.
To be honest, it is more complicated than that but allows me the simplification.
On top of that, there are additional functionalities that are present in one (ProxySQL) and not in the other. The point is if they are relevant for use in this context or not. For a shortlist see below (source is from ProxySQL blog but data was removed) :

As you may have noticed HAProxy is lacking some of that functionalities, like R/W split, firewalling, and caching, proper of the level 7 implemented in ProxySQL.
The Test Environment
To test the performance impact I had used a cluster deployed in GKE, with these characteristics:
- 3 Main nodes n2-standard-8 (8 vCPUs, 32 GB memory)
- 1 App node n2-standard-8 (8 vCPUs, 32 GB memory)
- PXC pods using:
- 25GB of the 32 available
- 6 CPU of the 8 available
- HAProxy:
- 600m CPU
- 1GB RAM
- PMM agent
- 500m CPU
- 500 MB Ram
- Tests using sysbench as for (https://github.com/Tusamarco/sysbench), see in GitHub for command details.
What I have done is to run several tests running two Sysbench instances. One only executing reads, while the other reads and writes.
In the case of ProxySQL, I had R/W splitting thanks to the Query rules, so both sysbench instances were pointing to the same address. While testing HAProxy I was using two entry points:
- Cluster1-haproxy – for read and write
- Cluster1-haproxy-replicas – for read only
Then I also compare what happens if all requests hit one node only. For that, I execute one Sysbench in R/W mode against one entry point, and NO R/W split for ProxySQL.
Finally, sysbench tests were executed with the –reconnect option to force the tests to establish new connections.
As usual, tests were executed multiple times, on different days of the week and moments of the day. Data reported is a consolidation of that, and images from Percona Monitoring and Management (PMM) are samples coming from the execution that was closest to the average values.
Comparing Performance When Scaling Reads
These tests imply that one node is mainly serving writes while the others are serving reads. To not affect performance, and given I was not interested in maintaining full read consistency, the parameter wsrep_sync_wait was kept as default (0).
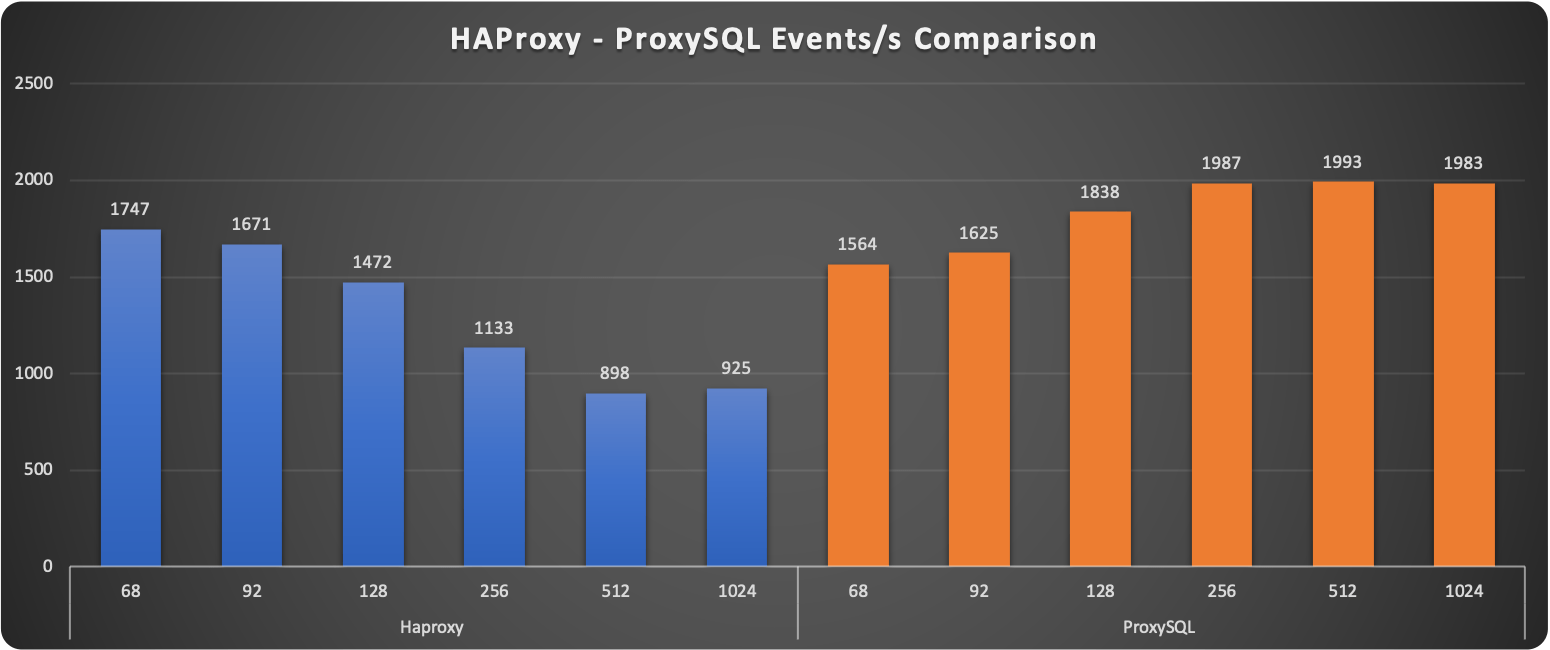
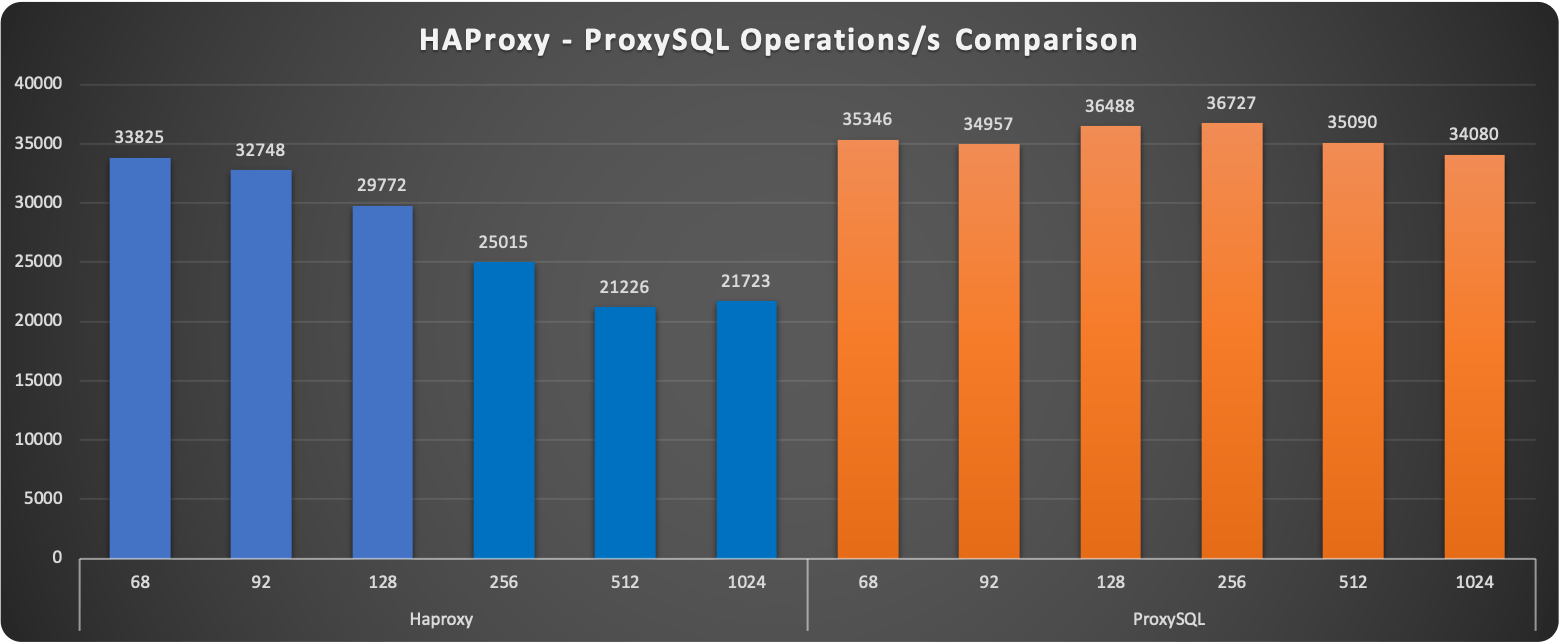
A first observation shows how ProxySQL seems to keep a more stable level of requests served. The increasing load penalizes HAProxy reducing if ⅓ the number of operations at 1024 threads.
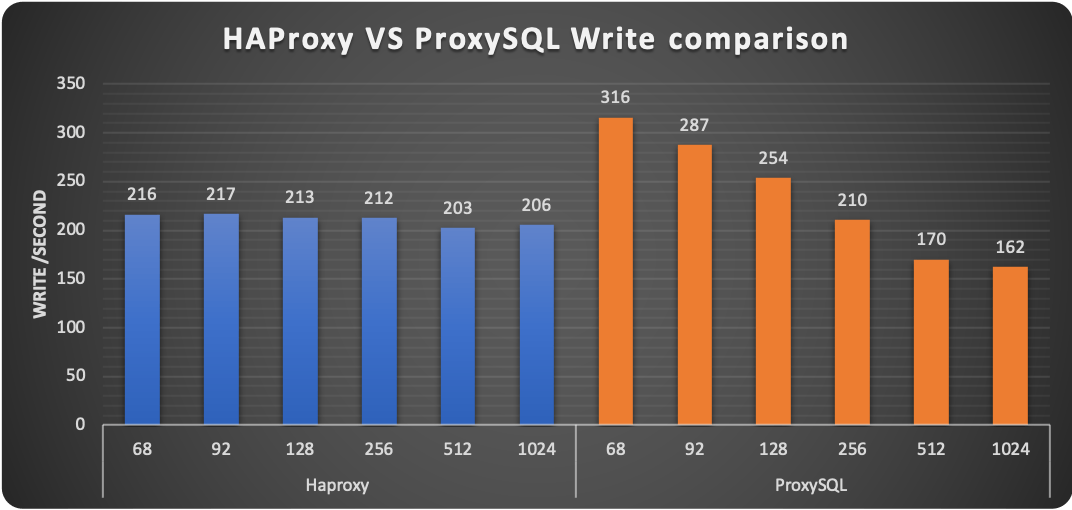

Digging a bit more we can see that HAProxy is performing much better than ProxySQL for the WRITE operation. The number of writes remains almost steady with minimal fluctuations. ProxySQL on the other hand is performing great when the load in write is low, then performance drops by 50%.
For reads, we have the opposite. ProxySQL is able to scale in a very efficient way, distributing the load across the nodes and able to maintain the level of service despite the load increase.
If we start to take a look at the latency distribution statistics (sysbench histogram information), we can see that:
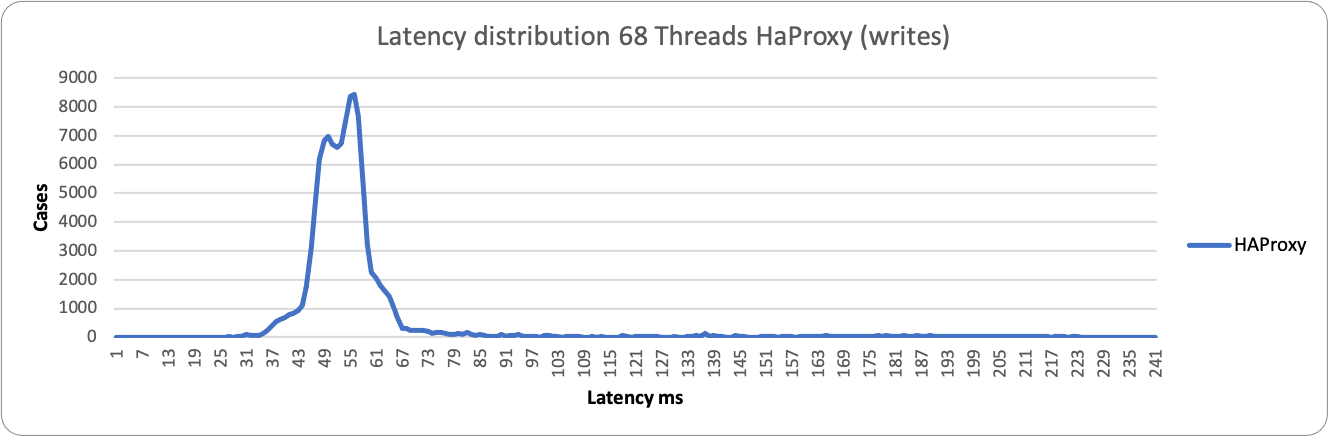
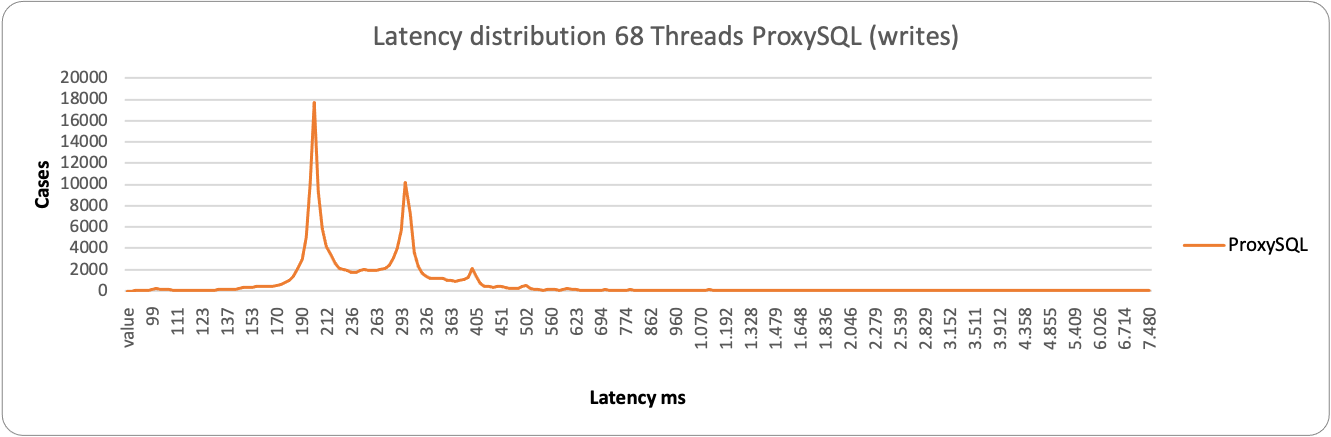
In the case of low load and writes, both proxies stay on the left side of the graph with a low value in ms. HAProxy is a bit more consistent and grouped around 55ms value, while ProxySQL is a bit more sparse and spans between 190-293ms.
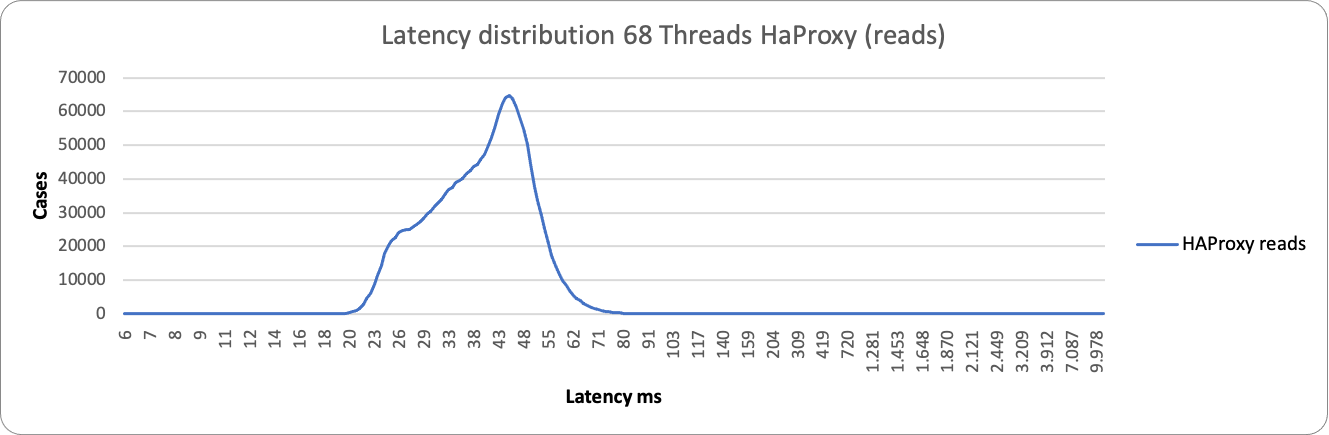
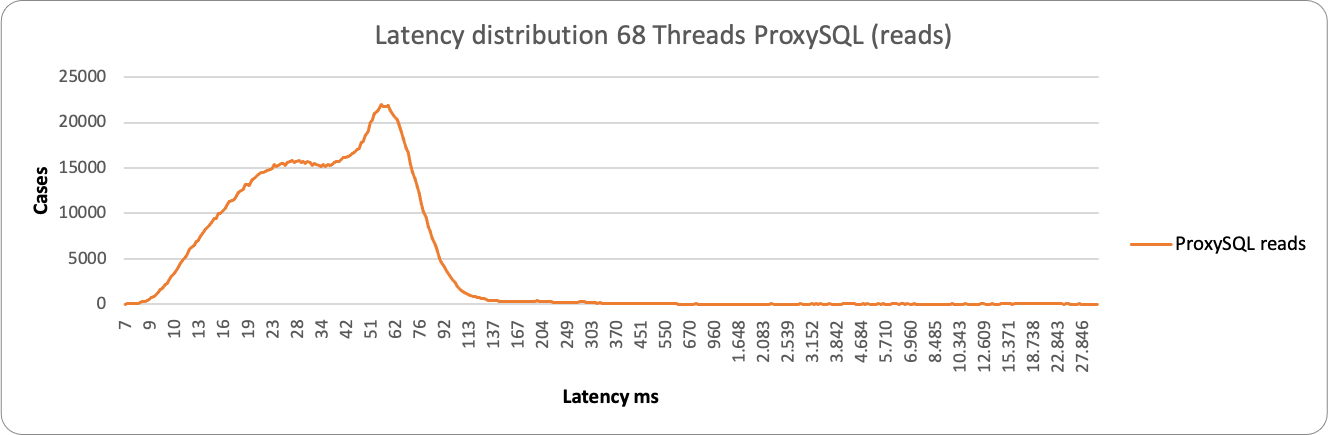
About reads we have similar behavior, both for the large majority between 28-70ms. We have a different picture when the load increases:
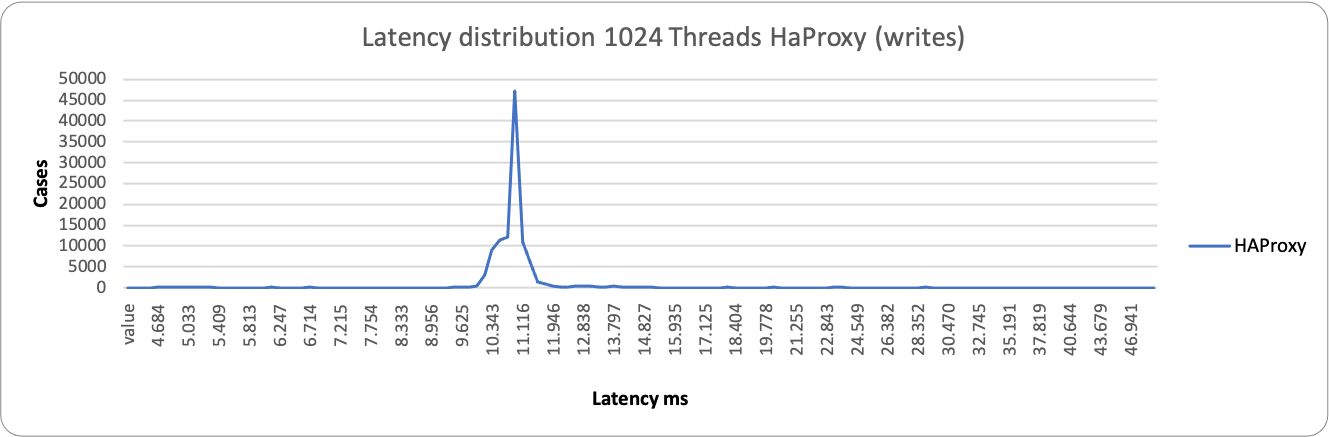
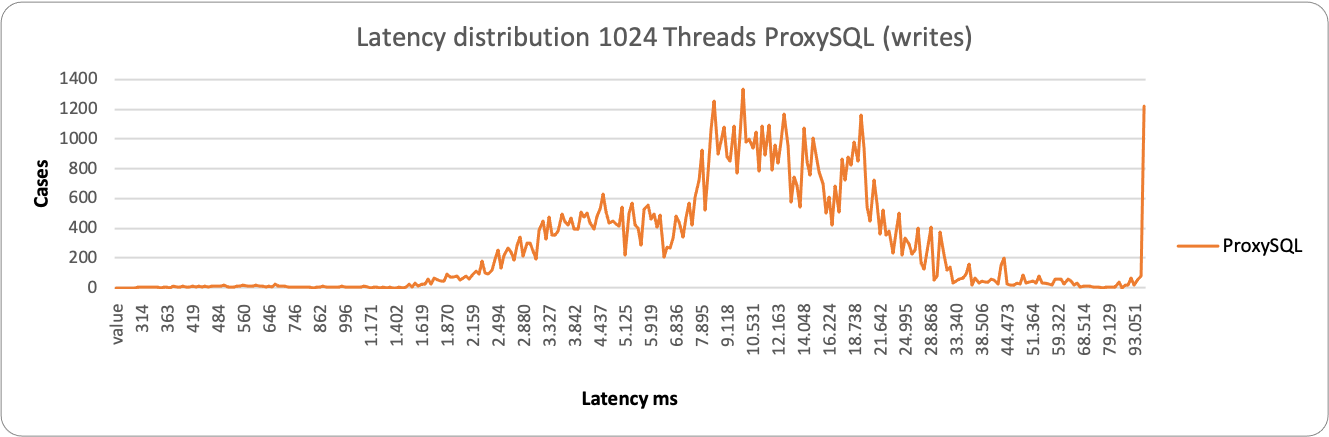
ProxySQL is having some occurrences where it performs better, but it spans in a very large range, from ~2k ms to ~29k ms. While HAProxy is substantially grouped around 10-11K ms. As a result, in this context, HAProxy is able to better serve writes under heavy load than ProxySQL.
Again, a different picture in case of reads.
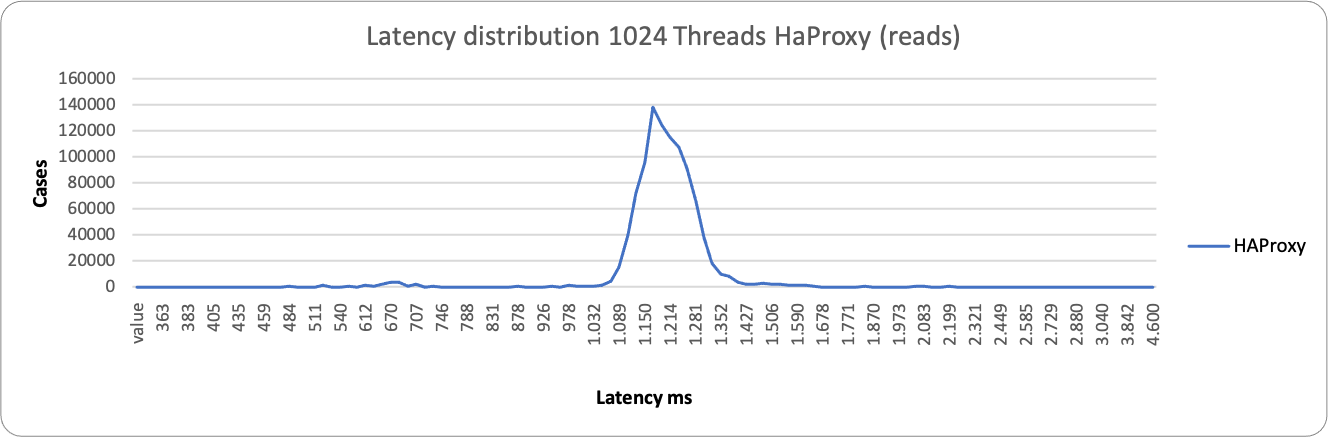
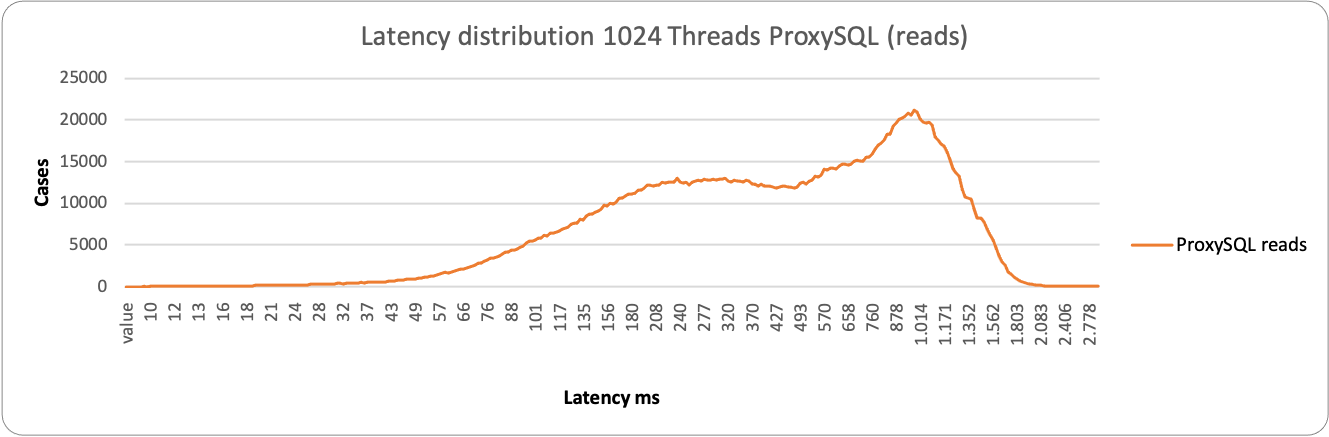
Here ProxySQL is still spanning on a wide range ~76ms – 1500ms, while HAProxy is more consistent but less efficient, grouping around 1200ms the majority of the service. This is consistent with the performance loss we have seen in READ when using high load and HAProxy.
Comparing When Using Only One Node
But let us now discover what happens when using only one node. So using the service as it should be, without the possible Plus of read scaling.
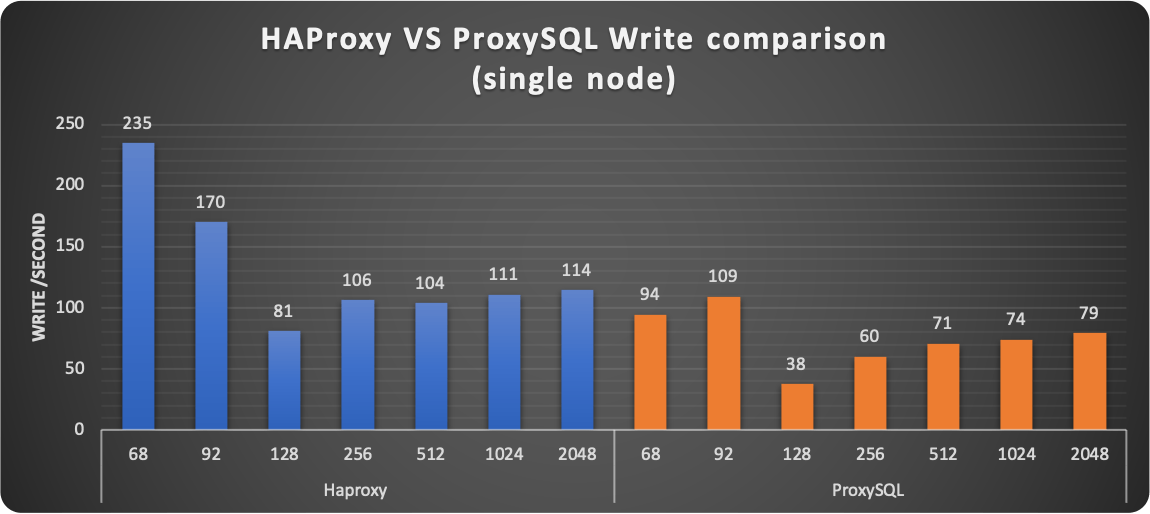
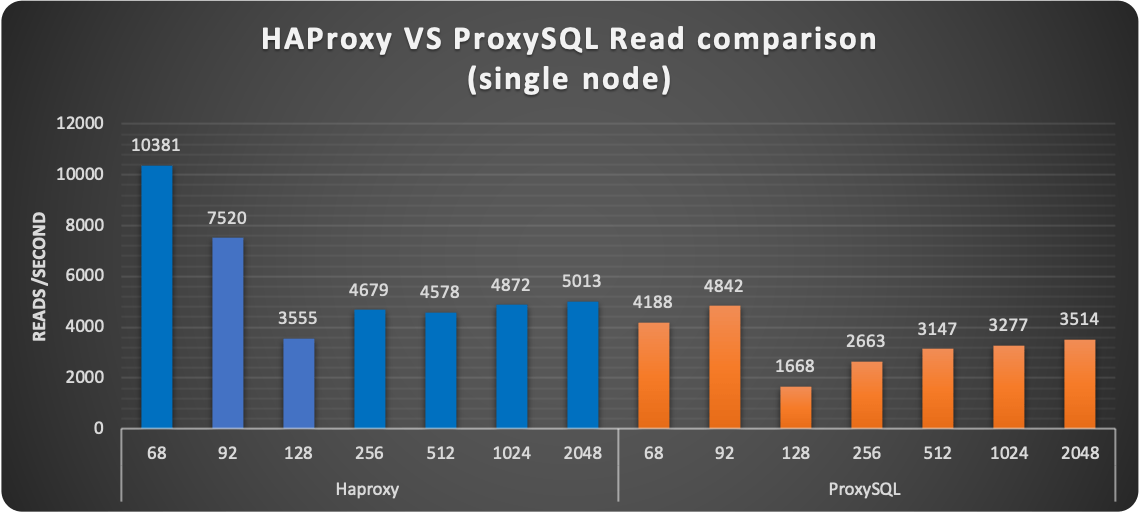
The first thing I want to mention is strange behavior that was consistently happening (no matter what proxy used) at 128 threads. I am investigating it but I do not have a good answer yet on why the Operator was having that significant drop in performance ONLY with 128 threads.
Aside from that, the results were consistently showing HAProxy performing better in serving read/writes. Keep in mind that HAProxy just establishes the connection point-to-point and is not doing anything else. While ProxySQL is designed to eventually act on the incoming stream of data.
This becomes even more evident when reviewing the latency distribution. In this case, no matter what load we have, HAProxy performs better:
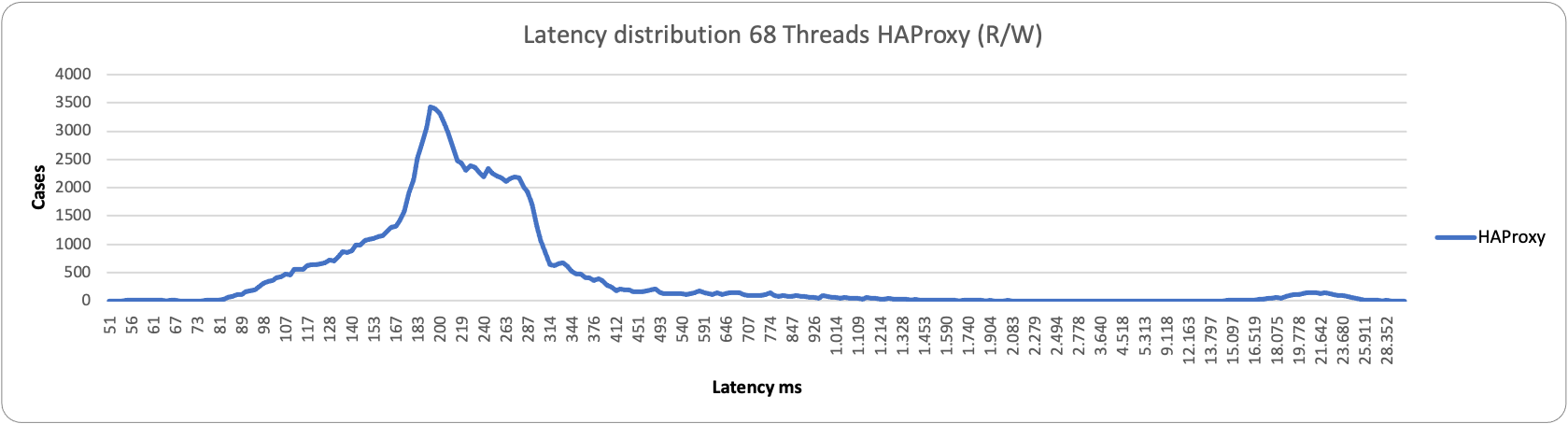
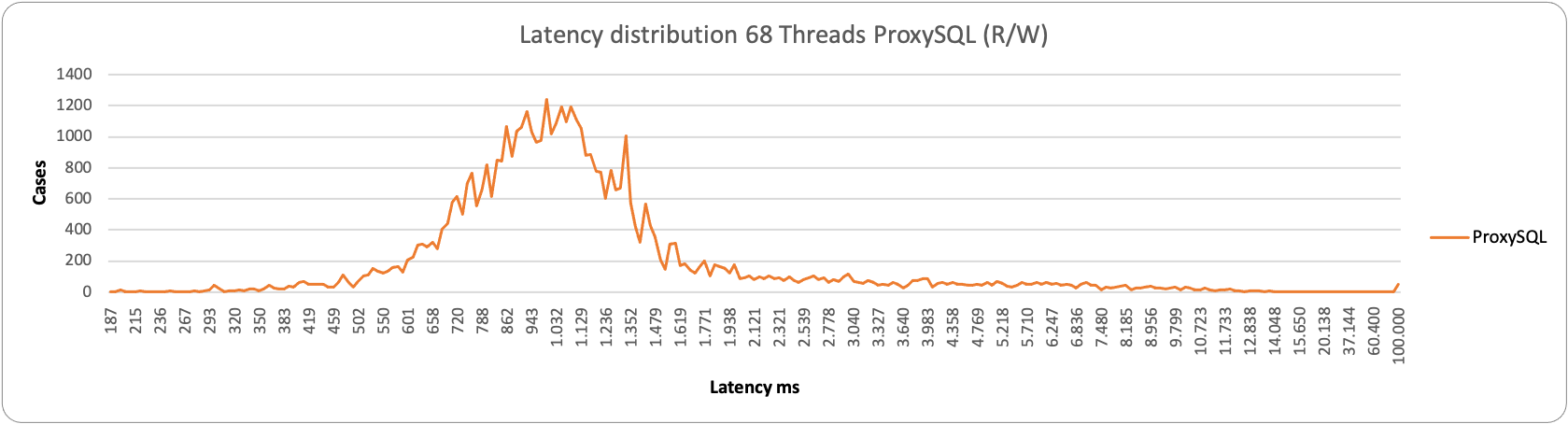
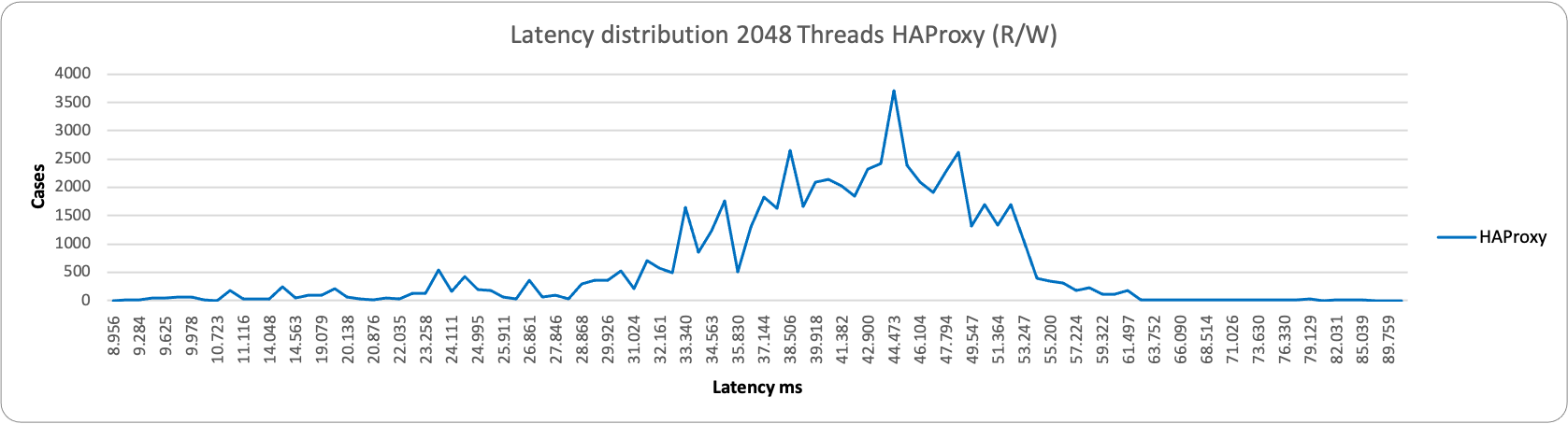
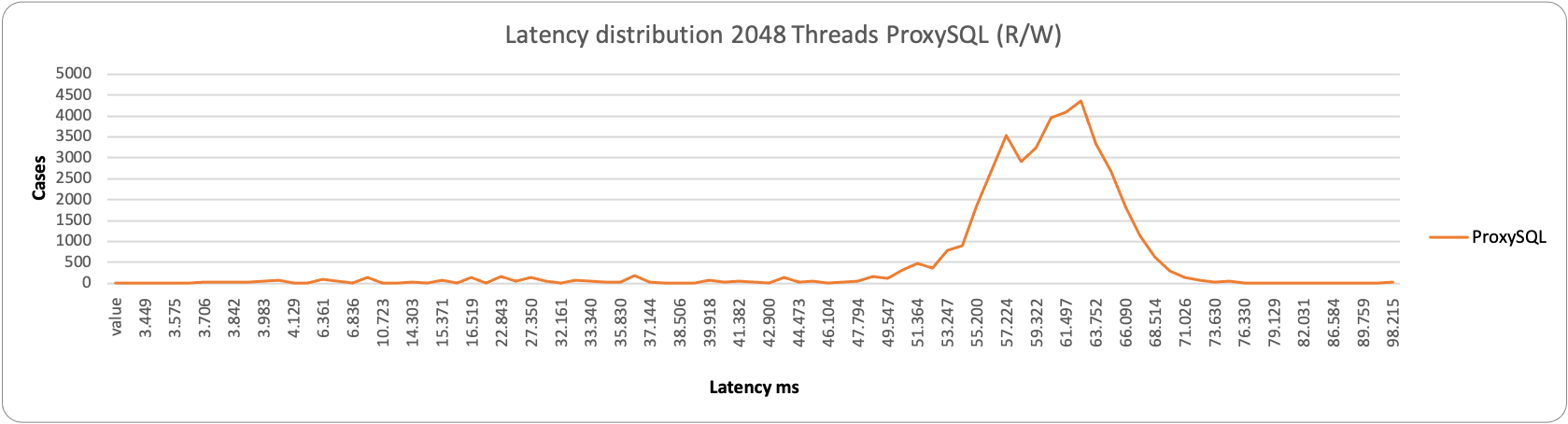
As you can notice, HAProxy is less grouped than when we have two entry points, but it is still able to serve more efficiently than ProxySQL.
Conclusions
As usual, my advice is to use the right tool for the job, and do not force yourself into something stupid. And as clearly stated at the beginning, Percona Operator for MySQL based on Percona XtraDB Cluster is designed to provide a MySQL SERVICE, not a PXC cluster, and all the configuration and utilization should converge on that.
And as clearly stated at the beginning, Percona Operator for MySQL based on Percona XtraDB Cluster is designed to provide a MySQL SERVICE, not a PXC cluster, and all the configuration and utilization should converge on that.
ProxySQL can help you IF you want to scale a bit more on READS using the possible plus. But this is not guaranteed to work as it works when using standard PXC. Not only do you need to have a very good understanding of Kubernetes and ProxySQL if you want to avoid issues, but with HAProxy you can scale reads as well, but you need to be sure you have R/W separation at the application level.
In any case, utilizing HAProxy for the service is the easier way to go. This is one of the reasons why Percona decided to shift to HAProxy. It is the solution that offers the proxy service more in line with the aim of the Kubernetes service concept. It is also the solution that remains closer to how a simple MySQL service should behave.
You need to set your expectations correctly to avoid being in trouble later.
References
Percona Operator for MySQL based on Percona XtraDB Cluster
Blog: Wondering How to Run Percona XtraDB Cluster on Kubernetes? Try Our Operator!
Blog: The Criticality of a Kubernetes Operator for Databases




Why don’t just use a k8s service? Usually haproxy can help for north-south traffic, but for east-west there should be any reason rather than load balancing, I guess.