NETFLIX HIGH-LEVEL SYSTEM DESIGN

STEP - 1
Functional Req
User Registration + login + profiles
Search
Recommendations
Activity tracking
Recommendation generation
Dashboard
Payment
Content Ingestion and Delivery
Rights + Licences
Categorization
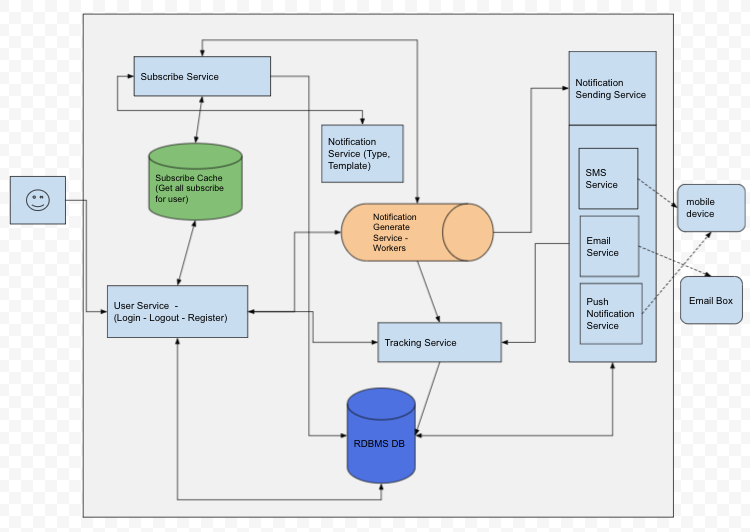
Notifications
Trend Movies
Watch History
Endorsement
Design Constraints
Number of users: 100 million
Daily active user: %10
Content Upload / sec: Minimal
Content Streamed / sec: Need scaling
How many videos let’s say 20000
Averaga per video 10 GB : 3gb HD + 1gb sd = 4 gb.
Avg per video 2,5 hours = 10 GB
Content Size: the average size of the video data
User activity tracking: High
Content streaming latency
STEP - 2
Define Microservices
We can bucketize functional requirements into Microservices.
The system is a huge system so should be a lot of teams to handle these requirements.
Multiple Microservices - Breadth Oriented System.
High Priority Microservices
Low Priority MS
STEP - 3
Logical Architecture whole services
User talks to Content Management and Activity MS
Content Owner uploads to Content Management MS some movie/s.
User is streaming content from Content Management MS.
Activity MS to Trending Movies through Pub-Sub/Batch service, because Trending Movies has much more workload. Probably user devices pushing like Roku system or smart tv pushing on.
Trending movies not offline ms. Current ms.
Recommendation MS more offline and pushes to Dashboard some recommends movies.
Users can query from the Dashboard.
The Dashboard has Rest Full API to stream from content management. To show some short videos to users from Dashboard MS.
We can expect our read: write ratio to be 200:1
STEP - 4A
We can talk to each microservices about the tier, data model, APIs and workflow. But we don’t have much time and we can pick the most important ms.
Tiers, DATA MODEL - APIs - Workflow/Algo
Content Ingestion and Delivery Microservices
App time, In-Memory(Cache for content metadata/compute for compression), Storage Tier
Data Structures
Metadata
K: content id, V: JSON object for the metadata: cast and crew, summary, thumbnail
Data:
K: content id, V: bitstream
How to store metadata:
Hashmap in memory
Row oriented in storage (There is no analytics data, easy to read-write)
How to store Data:
Video is not going to form a cache. The video comes from storage. Because of very huge data. There is storage throughput and network throughput because of decoding.
Roku devices can decode with the Ring buffer (FIFO), producer-consumer data structure.
Your producer should be faster than the consumer. The network is more bottleneck here, we don’t have to do it from memory. This is not a CPU workload, this is a storage workload.
Filesystem: They have offset and chunks mapping. Given any file, you can read from the offset. All file systems have to capability to allow you to read the file from anywhere within the file. The offset comes from the watcher’s device. Says “give me this movie by this offset”
APIs: create(K,V) for ingestion, read(K) from metadata, read (content_id, offset) from filesystem.
Video Uploads: Since videos could be huge, if while uploading the connection drops we should support resuming from the same point.
Video Encoding: Newly uploaded videos are stored on the server and a new task is added to the processing queue to encode the video into multiple formats. Once all the encoding will be completed the uploader will be notified and the video is made available for view/sharing.
Component Detail Design
STEP 4B - SCALING
Content Ingestion and Delivery Microservices
Need to scale for storage? Yes
Metadata : 20.000 movies * ~ 10 KB = 200 MB storage is trivial
Data : 20,000 movies * ~ 10 GB = 200 TB
Need to scale for throughput? Yes
Number of create(K, V) is negligible
read(K, offset)/s : 3mb/s * 10 million user : 30 TB/sec
Assumption (Fair) : A single server deliveries around 1-2 GB/s (SSD) and 300 Mb/s(spinning disk)
Metadata read is negligible
Need to scale for API parallelization? Not relevant
Apis themselves are constant latency, so no need to parallelize
Availability? Yes
Hotspot? Yes definitely
Geo-location based distribution? Yes
CDNs or content delivery network. Network latency. 30 TB/sec all over the world and we have to ensure that we have divide 30 TB/sec across the world based on access patterns. Let’s say 10 CDN all around the world. Each CDN also going to deliver 3 TB/s.
STEP 4C
Architectural layout
App Tier
LB: Using IP Anycast for DNS Load Balancing. They will typically share the same IP address. When one of the LB is failing and passive, the other LB becomes active. They make a health check between both all the time.
App Tier servers are stateless servers. So we don’t need to keep server information and session details. To handle transactions very fast. The implement is very easy on the internet.
Just a round-robin request. This method cycles through a list of servers and sends each new request to the next server. When it reaches the end of the list, it starts over at the beginning.
Req1 > Server A , Req2 > Server B end of the server start again A
Cluster manager: Heartbeat requests are being sent to a separate cluster manager and informing the load balancer. LB knows which server is currently healthy.
Cache - Storage Tier
Config store: Keeping track of how many servers are active and where are getting map does.
Which shards belongs to which server?
Like K: 4 → Server5, Server37, Server25.
This information pass to the LB. LB will go to Server5,or Server 37 or Server25
SHARDING - REPLICATION
Sharding:
Metadata: No need, if needed, horizontal
Data: Yes
Horizontal by content-id: Horizontally doesn’t help to reduce hotspot, lats say I divided the file system data by keeping the content of the file but keeping sum files, movie somewhere else, but the full movie within the same shard. What happens to them? If the movie very hot, a lot of people watching the same movie that particular servers became a hotspot. So we need to propose a Hybrid.
Hybrid: content id + chunk id [128 MB]: Hash (Content Id, chunk id) % N = shard id -> server
Why Hybrid? - If I looked at the data model. How many rows? - 20.000 rows. The size will be huge. This is more like it, short and fat content rather than long and thin content.
If we look at URL Shortener data, was it short and fat or thin and long? - Thin and long. If I have a thin data model then can I cut it vertically? - No. Short and fat, I can cut vertically - Yes.
Given the data model I can figure out whether I can do horizontally partitioning, vertically, or both. In this case, I will do both. I will partition by the movie as well as partition by chunks.
If we chuck will go to different shard, getting any throughput? - No, My read coming with reading (k, offset). Given an offset, I will go to one chunk and I will be able to distribute my work all the chunks. I am also removing the hotspot why?
You and I are watching the same movie are more probably, you and I are watching the same location as the movie, same chunk of the movie. I am able to reduce hotspots and able to load distribute as well as since my reads are coming with both the keys, it still not scatter-gather. I am able to go to a local shard and fetching.
First, offset > shard 1 - Second offset > shard2 depending on the offset Id it will map to the chunk id.
Watching the same movie versus watching the same portion of the movie probability of watching the same portion is a bit lesser.
Placement of shards in servers
Consistent Hashing
(Consistent hashing is a very useful strategy for distributed caching systems and DHTs. It allows us to distribute data across a cluster in such a way that will minimize reorganization when nodes are added or removed. Hence, the caching system will be easier to scale up or scale down.)
Replication - Yes
If even sharding you can not reduce hotspot versus the other way to remove hotspot. Sharding is not aligning hotspot. We can do replication. I can reduce hotspots.
We need available and we have a hotspot
AP
Does not need to be strictly nanosecond level consistent. Read heavy system. Write 1, read every time. Read-only AP system.
Best configuration: N = 3 or more, R = 1, W=1, high throughput, lowest latency.
I don’t have to conflict resolution between multiple replicas or the movie. I will just take the movie from 1 replica get out. Read-only system.
Latency: best, Throughput: best, Consistency: Bad
N = 3 , R= 1 , W = 1
Since W = 1 and N = 3, any one of the 3 replicas will take the write and return to the user before the update shows up in other replicas
Let’s say replica in server A takes the write and returns control to the user.
Subsequent read
○ Since R = 1 and N = 3, any one of the 3 replicas will take the read and return it to the user
○ If read happens in from server C, until C receives the update from A, C will return stale result

Comments
Post a Comment