Today the internet is completely associate with large source of data. Inappropriately, the huge majority of it isn’t out there in handily organized CSV files for download and analysis. If you want to capture data from several websites, you’ll have to be compelled to strive web scraping. It helps them to learn about operational activities, also the need of the market, and the data of competitors on the internet which helps them setup plan out future views.
- Real Astate agents use Web scrapping to get the data of new projects, resale properties, etc.
- Marketing companies can also use Web scrapping data to lead-related informations.
- Web scrapping technique can also be used by Price comparision portals, to get information about the products and price from e-commerce websites.
Using Web Scraping technique we can extract large amounts of data from websites whereby the data is extracted and saved to a local file in your computer or to a database in table (spreadsheet) format. The extracted data is stored in data pipeline and stored in a structure format.
How does Web Scrapping works?
To scrape the net, we tend to write code that sends asking to the server that’s hosting the page we tend to such. Generally, our code downloads that page’s ASCII text files, even as a browser would. However rather than displaying the page visually, it filters through the page trying to find HTML components we’ve such, and extracting no matter content we’ve schooled it to extract.
For example, if we tend to wished to include all of the titles within H2 tags from a web site, we tend to might write some code to try and do that. Our code would request the site’s content from its server and transfer it. Then it might undergo the page’s HTML trying to find the H2 tags. Whenever it found an H2 tag, it might copy no matter text is within the tag, and output it in no matter format we tend to such.
One factor that’s vital to note: from a server’s perspective, requesting a page via internet scraping is that the same as loading it during a browser once we use code to submit these requests, we might be “loading” pages more faster than a regular user, and thus quickly consumption up the website owner’s server resources.
Web Page Components
We can make GET request to a web server to retrieve files from the server. The server then sends back response files that request browser how to render the page. The files can be of different types:
HTML — Hyper Text Markup Language is a language that web pages are created in.
- CSS — stands for cascading Style Sheet add styling to make the page look nicer.
- JS — JavaScript is the Programming Language for the web and most popular programming language.
- Images — Images, such as JPG and PNG allow web pages to show pictures.
After our browser receives response of all the files, it renders and displayed the page. When we perform web scraping, we will be focusing on the main content of the web page, so we will look at the HTML.
Steps to Scrap Websites:
Below are the four steps to scrap
1) Using REQUEST library of python, you can send an HTTP GET request to the URL of the webpage that you want to scrape, which will respond with HTML content.
2) Using BeautifulSoap you can fetch and parse the data and store in data structure such as List or Dict.
3) Identify and Analyze your HTML tags attributes such as Class, ID and other HTML tag attributes.
4) Saving your extracted data in files such as csv, json or xls.
I will show you web scraping using Python3 and BeautifulSoap library with an example of extracting the name of weblinks available on the home page of https://www.red-gate.com/ website.
Scraping using BeautifulSoap
Step 1
We need two libraries: BeautifulSoup in bs4 and request in urllib to start with web scraping, Import both of these Python packages.
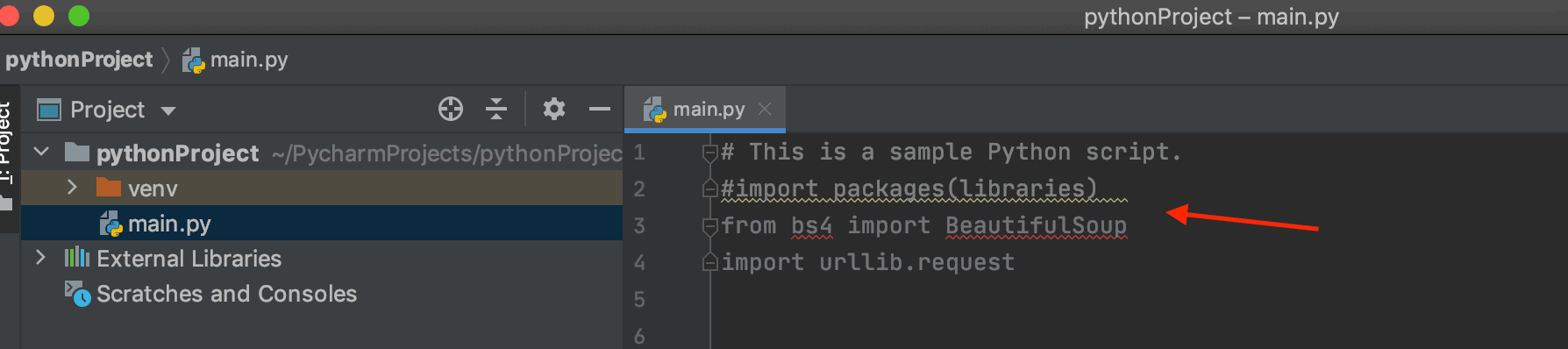
Step 2
To extract its HTML elements select the URL.

Step 3
By using urlopen() function in the request, we could access the content on this webpage and save the HTML in “myUrl”.
Step 4

Step 4
Create an object of BeautifulSoup library to parse this document,
and extract the webpage element data, using its various inbuilt functions.
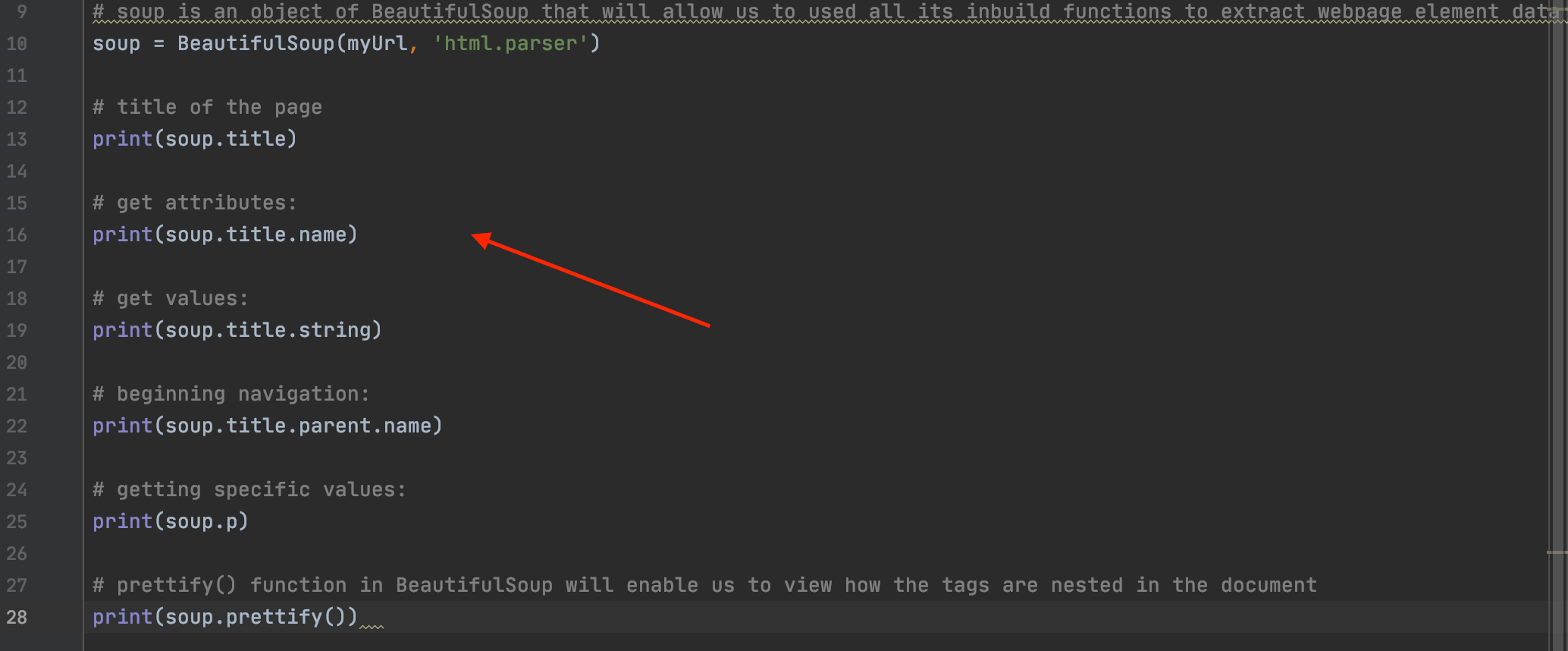
Step 5
Locate and scrape the services. Using the soup.find_all() function, to find all instances of a tag on a page. Remember find_all will return the lists so we’ll have to loop through, or use list indexing, it to extract text.
We use find_all methods to search for items by class or by id. For each element in the web page, they always have a unique HTML “ID” or “class”, we would need to INSPECT element on the webpage to check their ID or class. Once you find the HTML services on this web page, extract and store them.

Step 6
On inspecting the web page for extracting all the services names on the www.c-sharpcorner.com website, we located the ul tag with the class value as ‘site-nav’ as the parent node.
To extract all the child node which is our target to extract all the weblink names on the www.red-gate.com website, we located the li tag as the target node.
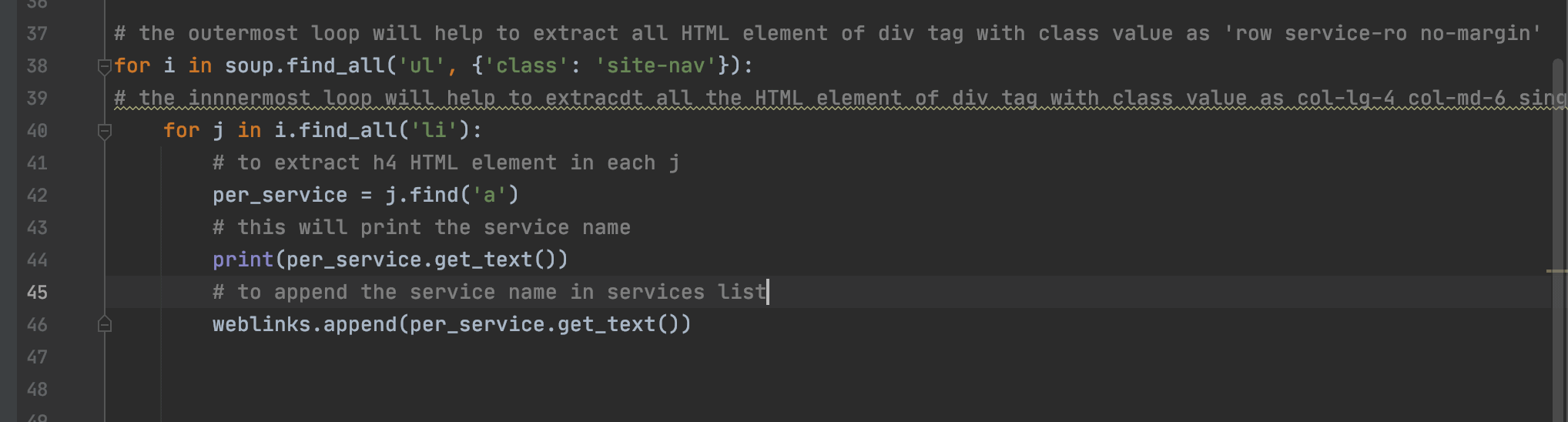
Output of the above code:
Home
SQL
.NET
Cloud
Sysadmin
Opinion
Books
Blogs
Web Scrapping Challenges:
The web has grown organically out the many sources. It combines plenty of various technologies, styles, and personalities, and it continues to grow to the current day. In alternative words, the web is quite as mess ! This may result in some challenges you’ll see after you strive web scrapping.
One challenge is selection. Each website is totally different, whereas you’ll encounter general stuctures that tend to repeat themselves, every web site is exclusive and can would like its own personal treatment if you would like to extract the knowledge that’s relevant to you.
Another challenges is sturdiness. Website perpetually amendment. Say you’ve engineered a shiny new web scraper too that mechanically cherry-picks exactly what you would like from your resource of interest the primary time you run your script, it works cleanly. However after you run a similar script solely a brief whereas later, you run into a discouraging and long stack of tracebacks!
This is a practical state of affairs, as several websites area until in active development. Once the site’s structure has modified, your scrap tool won’t be ready to navigate the sitemap properly or realize the unit tiny and progressive, thus you’ll doubtless be ready to update your scrape tool with solely borderline changes.
However, detain mind that as a result of the web is dynamic, the scrapers you’ll build can in all probability need constant maintenance. You’ll got wind of continuous integration to run scrapping tests sporadically to confirm that your main script doesn’t break .
Alternative to Web Scraping: API’s
Some web site suppliers supply Application Programming Interface(API’s) that enables you to access their information in a very predefined manner. With API’s you’ll be able to avoid parsing markup language and instead access the info directly victimization formats like JSON and XML. Markup language is primarily how to visually gift content to users.
When you use associate degree API, the method is usually additional stable than gathering the info through internet scraping. That’s as a result of genius API’s area unit created to be consumed by programs, instead of by human eyes. If the look of an internet site changes, then it doesn’t mean that the structure of the API has modified.
However, genius API’s will amendment additionally. Each the challenges of selection and sturdiness apply to genus API’s even as they are doing to websites to boot, it’s lot of more durable to examine the structure of associate degree API by yourself if the provided documentation is lacking in quality.
The approach and tools you would like to assemble info victimization genus API’s area unit outside the scope of this tutorial to be told additional regarding it, examples API Integration in Python.
Best Practices for Web Scraping:
Never scrape more often than you need to:
Some websites are not tested against high load, when we try to hit at constant interval then it creates huge traffic on a server side and it may crash or fail to serve other requests. This creates a high influence on user experience as they are more essential than the bots. So, we should make use a standard delay of 10 seconds or the requests according to the specified interval in robots.txt. Robots.txt file generally contains the instructions for crawlers. So this will not to get blocked by the target website.
Make use of functions like time.sleep() to keep from overwhelming servers with too many requests in too short a timespan.
Take responsibility to use scrape data:
We should always take responsibility of using scrap data. We should not scarp data and republish it somewhere else. It can be considered as legal issues so,we need to check “Terms of Service’ page before scrapping. We can review TOS and respect the terms and condition and privacy policy.
Never follow same scrapping pattern:
Now, as you recognize several websites use anti-scraping technologies, therefore it’s simple for them to sight your spider if it’s creeping within the same pattern. Normally, we, as a human, wouldn’t follow a pattern on a selected web site. So, to own your spiders run swimmingly, we will introduce actions like mouse movements, clicking a random link, etc, which provides the impression of your spider as a personality’s.
Scrape throughout off peak hours:
Off-peak hours are appropriate for bots/crawlers because the traffic on the web site is significantly less. These hours are often known by the geo location from wherever the site’s traffic originates. This additionally helps to boost the creeping rate and avoid the additional load from spider requests. Thus, it’s better to schedule the crawlers to run within the off-season hours. We can schedule crawling tasks to run during off-peaks hours.
Mask your requests by rotating IP’s and Proxy Services:
We’ve mentioned this within the challenges higher than. It’s continuously higher to use rotating IPs and proxy service in order that your spider won’t get blocked. Rotating IP’s address is an easy job if you are using scrapy.
User Agent Rotation and Spoofing:
Every request consists of a User-Agent string within the header. This string helps to spot the browser you are using, its version, and the platform. If we tend to use the identical User-Agent in every request then it’s simple for the target website to invision that request is coming from a crawler. So, to create certain we do not face this, try to rotate the User and the Agent between the requests. You can easily identify the information of browser and operating You can try examples of genuine User-Agent strings which is easily available on the Internet. You can set USER_AGENT property in settings.py, if you are scrapping. While scraping its always better to provide your accurate details in the Header of request.
Example of USER_AGENT
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36
Be transparent:
Don’t misrepresent your purpose or use deceptive ways to achieve access. If you have not login and a password that identifies ways to achieve access to a source, use it. Don’t hide who you are. If possible, share your credentials. Give your correct details in Header of the request.
Conclusion:
In this article we’ve seen the fundamentals of scraping the website and fetch all the useful data., frameworks, a way to crawl, and the best practices of scraping using Red-Gate page using BeautifulSoap.
For further practice here are the good examples of scrapping data from website
Weather Forecasts, Stock prices, Articles
To conclude:
- Follow target URLs rules whereas scraping. Don’t create them block your spider.
- Maintenance of knowledge and spiders at scale is troublesome. Use Docker/ Kubernetes and public cloud suppliers, like AWS to simply scale your web-scraping backend.
- Always respect the principles of the websites you propose to crawl. If APIs are available, always use them first.
Load comments