
Index advisor for N1QL Statement (ADVISE statement ) is officially released in Couchbase Server 6.6.
It is designed to make best efforts to provide global secondary index recommendation for each keyspace in the query which is better than all the current existing indexes and indexes in defer build.
Let’s see some more explanation of the highlighted parts of the functionality:
-
- Best Efforts:
- No completeness guaranteed: no index recommendations when no predicates nor derived filters.
- Correctness without false positive.
- Only recommend GSI indexes, no primary index recommendations.
- Index recommendation is for each keyspace involved in the query.
- Better: Query optimizer will prefer the recommended index to all the other existing indexes in the query execution. However, the recommended index is not guaranteed to be the optimal index for the query. For current release, the index advisor only advise for rule-based query optimizer. The support for cost-based query optimizer will be available in the next release.
- Best Efforts:
In order to improve the robustness of the functionality above and continuously bring enhancements to index advisor, some innovative features have been introduced in this release, this article will dive deep into the design details of several of them.
Virtual Index Verification Framework
For a covering index recommendation, to guarantee the correctness of the covering property is very difficult due to the complexity of the nested objects in the ARRAY indexes for both ARRAY predicates and UNNEST operation. To make sure the recommended covering index can build an actual covering scan in the query execution, a new feedback framework has been introduced for the purpose of verification.
As shown in the diagram below, index advisor creates virtual GSI indexes for the recommended covering index candidates and feedback to the query optimizer to verify if they would be selected by the optimizer among all the other existing indexes to generate an execution plan. Virtual Index is a in-memory data structure to mimic the metadata of a normal index and allows the optimizer to consider it the same as the other normal indexes when generating index scan operators. If the virtual index appears in a covering scan operator in the verification phase, we are confident to return it as it will behave in the same way after created by users.
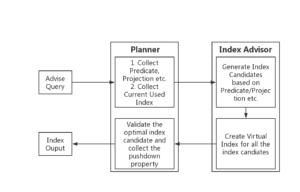
At the same time, the verification feedback loop also help to evaluate the pushdown properties of the recommended covering indexes. There is a new field in the output of covering indexes as “index_property” to provide the index pushdown properties as follows:
-
- LIMIT pushdown
- OFFSET pushdown
- ORDER pushdown
- GROUPBY & AGGREGATES pushdown
- FULL GROUPBY & AGGREGATES pushdown
With this function set up, we are ready to explore the new areas as discussed below.
Index Pushdowns in Covering Index Recommendations
Index Pushdowns are performance optimizations in which the query engine pushes more of the work down to the Indexer.
Index advisor makes best efforts to explore the possibility to recommend covering indexes with higher pushdown properties in order to further improve the query performance.
As shown in the diagram below, three kinds of pushdowns will be applied on top of the covering index: GROUP BY/aggregate, ORDER BY and limit/offset when applicable. Let’s go into the details of each of them.
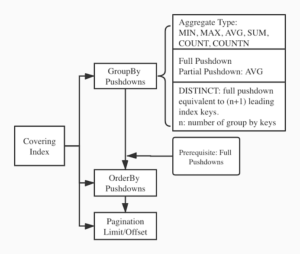
Index Grouping/Aggregates
Index Advisor follows the design of Index Grouping and Aggregation in the following aspects:
-
- Support six types of aggregations: MIN, MAX, AVG, SUM, COUNT and COUNTN.
- Best efforts to adjust the order of index keys to achieve full/partial aggregation for better performance.
- Full aggregation refers to the scenario in which indexer handles the full group aggregation, allowing the query engine to skip this entire operator.
- In partial aggregation, indexer sends partial group aggregation to query and replies on query to merge the intermediate results and create the final group and aggregation operator.
-
- Special handling for DISTINCT aggregation which is only possible when full pushdowns apply.
Prerequisites:
-
- All predicates exactly translated to range scans with a covering index, no JOIN or NEST in the query.
How it works for Aggregates w/o DISTINCT:
-
- Generate index keys based on predicates, following index recommendation rules.
- Adjust the positions of GROUP BY keys to be equivalent to/dependent on leading index keys by skipping the ones from equality predicates, while the order inside these GROUP BY keys doesn’t matter.
- For those GROUP BY expressions not equivalent to/ dependent on index keys, append them to the index keys.
- For those GROUP BY expression equivalent to index condition, move the index condition to index keys.
- Append projections to generate covering index, with aggregate expressions be anywhere in the index keys or dependent on the index keys or meta().id.
How it works for Aggregates w DISTINCT :
-
- Only when full pushdown applies.
- The same rules above apply to the GROUP BY expressions.
- Distinct aggregate expressions must be equivalent to/dependent on (n+1) leading index keys by skipping the ones from equality predicates, in which n represents the number of the GROUP BY items.
Index Ordering
When ORDER BY keys are aligned with the index key order, query optimizer may skip generating the ORDER BY operator. Index Advisor makes best efforts to make adjustment accordingly.
-
- Relocate the ORDER BY index keys on top of GROUP BY/Aggregate pushdowns or normal covering indexes if GROUP BY doesn’t exist to generate indexes with ORDER BY pushdown properties.
- Only apply on top of FULL GROUP BY/Aggregate pushdowns.
- ORDER BY expressions follow the order of index keys by skipping the ones from equality predicates.
- When the ORDER BY term can be pushed down, add “DESC” to the term that has descending order.
- Unlike GROUP BY/Aggregate pushdowns, the order inside the ORDER BY terms matters. In the scenarios where both GROUP BY and ORDER BY exist in the query but index pushdowns can not be fulfilled together, Index advisor will process them separately and rely on the verification framework mentioned above to choose the better one.
Paginations
Index advisor doesn’t have specific processing for limit/offset pushdowns, indeed it will apply on top of the previous two pushdowns if any of them exists or apply directly to the original covering index.
Let’s go through several examples as shown below, in which the pushdown property will be verified by the virtual index feedback loop and be shown in the “pushdown_property” if applicable.
Example 1:
|
1 2 3 4 |
ADVISE SELECT sum(d) FROM shellTest WHERE a = 10 and b < 10 and c is not null GROUP BY c |
The output of the covering index is shown as below, in which the GROUP BY expression “c” has been adjusted to be right after index key “a” which comes from equality predicate.
|
1 2 3 4 5 6 7 |
"covering_indexes": [ { "index_property": "FULL GROUPBY & AGGREGATES pushdown, GROUPBY & AGGREGATES pushdown", "index_statement": "CREATE INDEX adv_a_c_b_d ON `shellTest`(`a`,`c`,`b`,`d`)", "keyspace_alias": "shellTest" } ] |
Example 2:
|
1 2 3 4 5 |
ADVISE SELECT c11 FROM shellTest WHERE test_id = \"advise\" ORDER BY c11 DESC LIMIT 2 |
In this output, “c11” can qualify for ORDER BY pushdown, so “DESC” is added to this index key.
|
1 2 3 4 5 6 7 |
"covering_indexes": [ { "index_property": "ORDER pushdown, LIMIT pushdown", "index_statement": "CREATE INDEX adv_test_id_c11DESC ON `shellTest`(`test_id`,`c11` DESC)", "keyspace_alias": "shellTest" } ] |
Example 3:
|
1 2 3 4 |
ADVISE SELECT avg(c), sum(DISTINCT d) FROM shellTest WHERE a = 10 and b < 10 GROUP BY b |
In this example, there is a DISTINCT aggregate on “d”.
DISTINCT aggregate only applies to full pushdown with DISTINCT aggregate expression in the (n+1) leading keys.
- “a” comes from equality predicate, skipped.
- “b” follows as a GROUP BY expression.
- The index keys from predicates and GROUP BY qualify for full pushdowns.
- “d” will come after the GROUP BY expression “b” and in front of “c” as it is from DISTINCT aggregate.
The output result:
|
1 2 3 4 5 6 7 |
"covering_indexes": [ { "index_property": "FULL GROUPBY & AGGREGATES pushdown, GROUPBY & AGGREGATES pushdown", "index_statement": "CREATE INDEX adv_a_b_d_c ON `shellTest`(`a`,`b`,`d`,`c`)", "keyspace_alias": "shellTest" } ] |
Summary
Index Advisor makes best efforts to optimize the recommended indexes for better query performance. The verification framework brings the enhancement of correctness and robustness, and the support for index pushdowns will improve the query performance further.