
Global HR — 8 min

Share
Companies are catching on to the advantages of Kubernetes for development of their Platform-as-a-Service (PaaS) solutions. At Remote, we have just completed a successful transition to Kubernetes and would like to share our story to help others make the switch.
Different businesses have different needs, methodologies, and cultures, and not everyone grows in the same direction. As we grew, we knew we needed internal tools that would not only complement our processes but would fit within our philosophy of work. We use Kubernetes as a building block in our internal PaaS solution to abstract away infrastructure and provide our developers with smaller surfaces with which to deploy and manage their applications.
Kubernetes is only six years old, however, and many people who would benefit from its implementation aren't sure how to deploy, manage, and secure it correctly. This is why we decided to write these blog posts and best practices to help others make the switch quickly and safely.
At Remote, we believe everything we do should be documented and, if possible, automated. Code is automation and can act as documentation when simple and written well. So, we strongly believe in infrastructure-as-code and are heavy users of Terraform.
Remote is also a customer of Amazon Web Services (AWS), so examples in this and following posts will be infrastructure provisioned on AWS via Terraform.
When we jumped into this redesign, we had a few requirements:
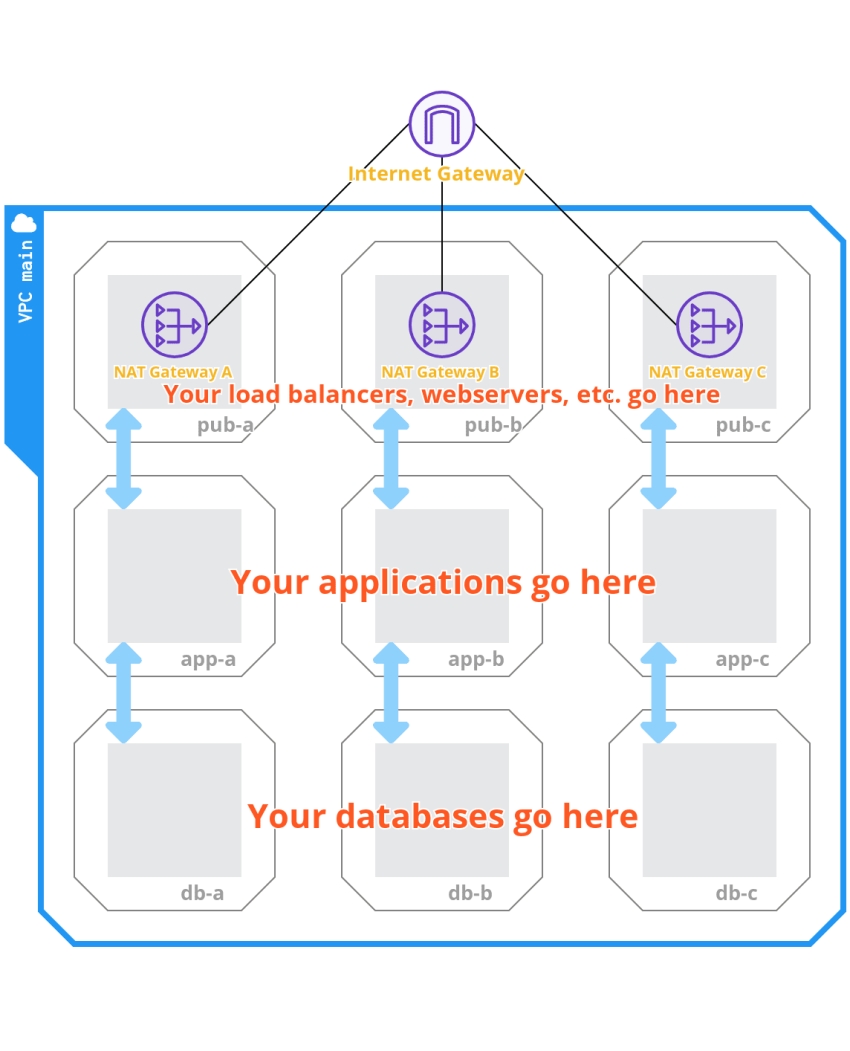
Subnet resource segregation: publicly accessible resources such as load balancers, webservers, etc; privately accessible resources hidden behind load balancers and webservers, such as frontend or backend applications; privately accessible resources for use by applications such as databases, caches, search indices, etc.
IP Addressing - Maintain enough IPv4 addressing capacity for future scale. Each Kubernetes node, pod, and service will have its own IP address, and we should keep in mind that the number of services will increase.
Redundancy - Split logical subnets in groups of three, for use by three availability zones, for redundancy.
EKS Compatibility - Keep compatibility with EKS clusters in mind, which is the Kubernetes managed solution we wanted to use.
If you want to reproduce the implementation in this article, you will need a couple of tools:
Terraform 0.12
An AWS account with access to AWS VPC
Kubernetes clusters prefer to be laid on a flat network, with the same IP address space shared between Kubernetes nodes, masters, and pods running on them. This greatly simplifies networking from an operations standpoint, but it makes it difficult to properly segregate these networks from a security standpoint. That's why we strongly recommended an internal private network for all of these, with specific public endpoints exposed via ingress load balancers. Exposing services like this keeps public only the ones that should be public and private the ones that should not be publicly accessible.
The next level of segregation is to separate your applications from their databases, including SQL and NoSQL database systems, key value stores, caches, indexing systems, etc. These databases should live in a separate network of their own and should only be allowed to talk to applications.
Applications can then connect to databases and be contacted from inside the Kubernetes cluster, which has a single entry point in the form of a service (an Ingress Controller) that forwards external traffic to the internal Kubernetes services specified by the respective Kubernetes ingresses.
This creates three subnets:
Public: Where our NAT gateways and load balancers live
Application: Where our Kubernetes cluster machines and pods are
Database: Where all of our databases stay
For reliability, we should also make our clusters multi-datacenter. On AWS, an Availability Zone (AZ) maps to a datacenter. We decided to go with three AZs. That effectively makes for three subnets per logical subnet, as you need to specify to which AZ a given subnet will correspond. That brings it to:
pub-a, pub-b, pub-c
app-a, app-b, app-c
db-a, db-b, db-c
We created a Virtual Private Cloud (VPC) to hold all of these subnets. We picked 10.0.0.0/16 as the VPC IP range to maximize the number of IP addresses in our internal networks. Splitting this network into ranges for the subnets is left as an exercise to the reader. We can't divulge all of our network topology!
As previously mentioned, we at Remote are heavy users of Terraform as a tool to implement Infrastructure-as-Code (IaC). IaC allows you to define the end state that your infrastructure (i.e. cloud resources) should achieve as code and provides you with several good properties.
The value of attributes of resources (e.g. the CIDR block of a subnet) can be exported and re-used when defining other resources (e.g in an EC2 instance's Security Group), defining explicit dependencies between them. These dependencies can be represented as a dependency graph and acted upon the tool to allow for repeatable provisioning of resources.
Terraform Remote State allows us to export output values of Terraform runs and use them in other repositories, effectively abstracting away implementation details and exposing infrastructure as an API developers can use, without worrying about how resources are deployed. In a Terraform multi-repository architecture, such as the one we use at Remote, these remote states can help with passing data between runs of different repositories.
Terraform does a lot of type safety and format safety checks before running, allowing you to avoid errors when deploying your infrastructure. This helps you be more precise when automating.
Terraform code, when written well and structured, can act as documentation of the infrastructure itself.
But, this article is not a sales pitch for Terraform, we'll leave that for our friends at Hashicorp.
So, let's actually implement this thing.
The following code provisions our main VPC and the subnets we listed in the Network Design section. Put this in a vpc.tf file and change out the ... with CIDR blocks that make sense for your use case.
The following code provisions an Internet Gateway so that resources in our subnets can access the internet. We also deploy our NAT Gateways here, which mediate access to and from the internet to our internal resources and, thus, are placed only in public subnets. We're also provisioning one elastic IP address per NAT Gateway so they are externally accessible on fixed IP addresses. Put this in a nat.tf file.
Now we have our different subnets, available in three different Availability Zones. How do we make them talk to each other?
We need resources in the app and db subnets to have access to the internet to fetch updates. To make this possible, we create and associate route tables. This tells the AWS network fabric what traffic to route and to where. In our case, we are defining two types of route tables: public and private. We have defined a public one, which will route external traffic directly to the internet while remaining capable of routing internal traffic to subnets in the VPC, and three private route tables, which will route external traffic to the NAT Gateway placed in the public subnet of their corresponding Availability Zone. Put this in a routes.tf file.
We know we will add databases, caches, and others to the db subnets. These subnet groups allow referencing to these subnets when we provision those databases. You may add other kinds of subnet groups that you use here. Put these in a subnet_groups.tf file.
We hope this article helps you begin to architect your Kubernetes network correctly. We believe this setup provides the best network scalability and segregation capabilities for the future of Remote, and it may work for your company, too.
See you in the next blog post, where we'll talk about spinning up the actual Kubernetes cluster using Elastic Kubernetes Service. If you have questions, feel free to reach out on Twitter!
Subscribe to receive the latest
Remote blog posts and updates in your inbox.
Global HR — 8 min

Visas and Work Permits — 8 min

Global HR — 12 min

Global HR — 15 min