
This post was originally published on the Stax website.
Building a web console for a product as complex as Stax presented a number of challenges. Our API-first, serverless platform offers a diverse range of features for enterprises who want to manage and optimize their AWS ecosystem.
With such a developer-focused foundation, we needed to provide customers with a performant, reactive web app, with an intuitive user-experience that didn’t hide the power and functionality of our API. Data access through our console also needed to be built to the same high standard of security and compliance as the rest of our product.
This post will cover what we set out to achieve when building the Stax Console, our experience building a serverless GraphQL API to power it, and the lessons we learned along the way.
Serverless by Design
We wanted to produce a solution that was serverless from the start, to match the architecture we use for the rest of the product. One of the biggest benefits we’ve seen from going all in on serverless architectures at Stax is uptime and reliability. Avoiding relying on a server that can become a single point of failure allows us to meet our Service-Level Agreement, and ensure customers can access the platform during peak load times. Using AWS Lambda means queries from our front-end scale out horizontally and there’s always enough compute resources to process requests.
Using serverless products also improves security during development, as services like AWS Lambda provide baked-in compliance and service levels out of the box. Allowing Amazon to handle upgrades and patching of the infrastructure that our code runs on allows us to focus on building software instead of managing hardware.
The minimal infrastructure overhead when going serverless has allowed our team to fully own the deployment and monitoring of our GraphQL API. For example, developers can add new Networks functionality using separate Lambda functions to those used to fetch account data, minimizing the blast radius from pushing a new change to production.
Early Days
The first iteration of our Console had a fairly traditional web architecture. A React single-page application (SPA) called the Stax REST API directly, which is a serverless solution using AWS API Gateway and AWS Lambda in front of a relational database. AWS Cognito handles user authentication and sign-on for both the Console and REST API.
We ran into a few technical issues with this approach:
- Tooling. Modern front-end frameworks evolve quickly. Consuming data from REST APIs with React was complex and it was difficult to manage state.
- Stability. The tight coupling of our front-end SPA to back-end REST API was efficient, but the contract between systems was constantly changing as features developed which risked breaking our user interface.
- Real-Time Updates. We would need to build our own WebSocket implementation to push data to our front-end SPA to provide real-time updates. This would have been complex to implement in both the front end and back end.
It also became apparent that as Stax grew as a product, the Console needed to integrate with other back-end services than our REST API, such as Cost and Compliance data for accounts and our Customer Support Case service. Interfacing with multiple APIs and protocols, all with differing authentication mechanisms, led us to consider a Back End for Front End pattern with a single GraphQL API.
Our Console Architecture Now
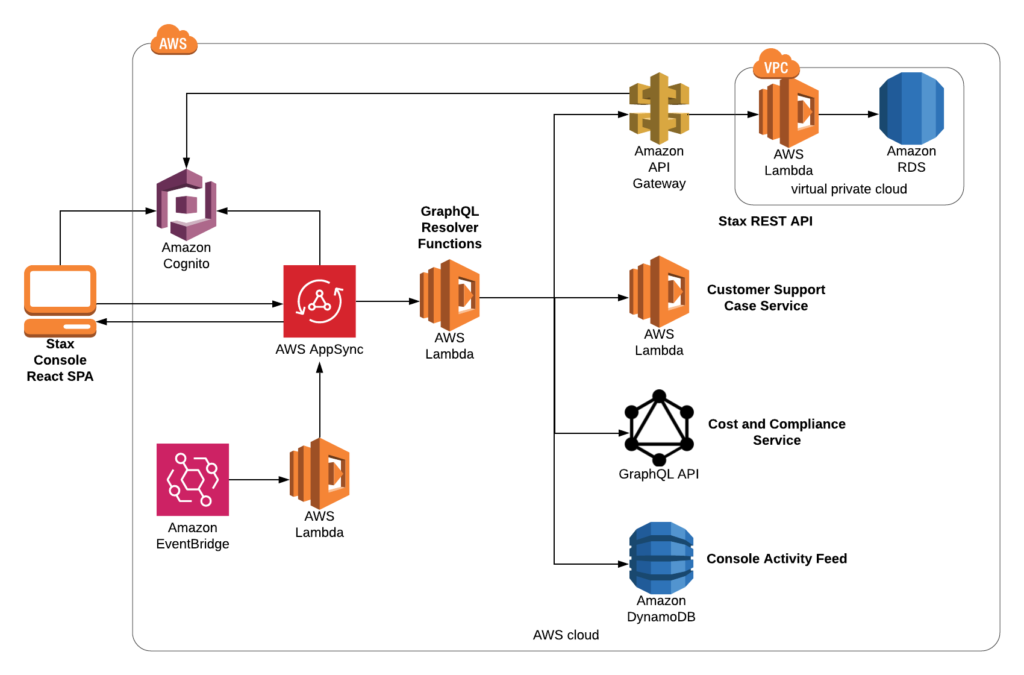
The architecture centers on a GraphQL API layer that acts as a proxy between our front-end and back-end services. GraphQL is a query language for APIs; it allows developers to define the types of data in a system (the schema), and wire up functions to fetch data from different sources (resolvers). Relationships between data can be expanded in a single GraphQL query. For example, a single request can resolve a Stax Workload and the user that deployed it in one go.
A key reason GraphQL suited our needs is that data can be fetched from any source by a resolver and be presented to a front end as a single interface. This means that as Stax grows, we can refactor and optimize back-end services with minimal impact to our front-end developers and customers. Authentication is also massively simplified. The front-end authenticates to our GraphQL API in one place, which handles connections to various REST and GraphQL APIs and event sources behind the scenes.
At Stax, we’re closely partnered with AWS, and try to use native AWS solutions where possible as part of our development philosophy. We opted to use AWS AppSync, a fully managed serverless GraphQL implementation as the core of our service.
AWS AppSync implements the main GraphQL directives, including GraphQL Subscriptions that manage WebSocket connections between clients and your GraphQL API. AWS Lambda fetches and transforms data in GraphQL resolver functions, AWS DynamoDB is used for serverless data stores, and AWS EventBridge triggers Lambda functions in response to system events.
Built with Stax
Stax is an API-first product, so we leveraged the publicly available Stax REST API to build the majority of the customer console. Consuming (dogfooding, really) our own REST API means we can road-test functionality and improve our documentation before the functionality is released to customers, acting as our own quality control. Having a GraphQL API that proxies our back end also lets us introduce new features into the Console before they are made public to customers in the Stax REST API. We can simply connect it to AppSync and add it into the Console as “Beta” functionality.
Our GraphQL API communicates with the Stax back end by sharing authentication information from AWS Cognito between services. This ensures user data remains strictly segregated by a customer’s organization at each step of the process, and maintains an audit trail tied to the specific user that initiated an action. Having a single GraphQL API for our front end also lets us enforce role-based access control, which means we can enforce restrictions for user actions based on their role at a query level.
The AppSync API is also connected to the Stax Event Bus to listen to system events generated by back-end services, like the status of individual account setup steps) completing. We use GraphQL Subscriptions to enhance the functionality provided by the Stax Event Bus and push updates to the Console without customers needing to refresh their page.
Embracing the Limitations
Authentication often poses a challenge with serverless architectures, as user authentication information needs to be shared with each service or API involved in fulfilling a request. A single GraphQL query might result in multiple downstream services being called — for example, to show a Network, the account in which it’s deployed, and the user that created it.
AWS AppSync makes it easy to abstract authentication by using AppSync Pipeline Resolvers, but it’s still important to ensure calls to services with strict rate limits like AWS Cognito are minimized. We approached this by abstracting interactions with Cognito into a dedicated service, but there’s room for this to be improved with caching.
As a relatively new product offering, AWS AppSync had a few limitations in its GraphQL implementation that we had to overcome. AppSync imposes a strict, 30-second timeout for all queries, meaning large paginated lists of data with nested relationships need to be handled carefully. AppSync also allows batching Lambda functions when dealing with one-to-many relationships, but currently has a batch limit of 5, which is too low to be useful in practice. Deploying our own GraphQL implementation would have let us avoid these issues, but the benefits of using a fully managed serverless solution outweighed the pain points.
Next Steps
The future of our GraphQL API will focus on performance improvements through data caching, and on extending real-time updates to all Stax components. Caching data will allow customers to manage their Stax environments and view data even when downstream services are unavailable.
As the Stax platform continues to evolve, we’ll continue adding new features to our console, to make it as easy as possible for your organization to manage all aspects of their AWS ecosystem from a single place. But since we’re leveraging a serverless approach, we don’t need to allocate effort to maintaining servers. Instead, we can focus on building out more amazing experiences for our customers while at the same time remaining secure and compliant, even as the platform grows more sophisticated.
If you’re interested in learning more about Stax, and how it might fit into your organization’s AWS ecosystem, get in touch and we’ll arrange a demo.
 Adam Quigley
Adam QuigleyI’m an AWS Certified Software Engineer based in Melbourne with interests in Serverless computing and full-stack web development. I create APIs and Microservices with AWS for Stax, a platform that helps customers accelerate their transition to AWS using industry best practices.









