
This post is also available in 简体中文.
Cloudflare’s Web Application Firewall (WAF) protects against malicious attacks aiming to exploit vulnerabilities in web applications. It is continuously updated to provide comprehensive coverage against the most recent threats while ensuring a low false positive rate.
As with all Cloudflare security products, the WAF is designed to not sacrifice performance for security, but there is always room for improvement.
This blog post provides a brief overview of the latest performance improvements that were rolled out to our customers. Visit our learning center to learn more about how a Web Application Firewall (WAF) works.
Transitioning from PCRE to RE2
Back in July 2019, the WAF transitioned from using a regular expression engine based on PCRE to one inspired by RE2, which is based around using a deterministic finite automaton (DFA) instead of backtracking algorithms. This change came as a result of an outage where an update added a regular expression which backtracked enormously on certain HTTP requests, resulting in exponential execution time.
After the migration was finished, we saw no measurable difference in CPU consumption at the edge, but noticed execution time outliers in the 95th and 99th percentiles decreased, something we expected given RE2's guarantees of a linear time execution with the size of the input.
As the WAF engine uses a thread pool, we also had to implement and tune a regex cache shared between the threads to avoid excessive memory consumption (the first implementation turned out to use a staggering amount of memory).
These changes, along with others outlined in the postmortem blog post, helped us improve reliability and safety at the edge and have the confidence to explore further performance improvements.
But while we’ve highlighted regular expressions, they are only one of the many capabilities of the WAF engine.
Matching Stages
When an HTTP request reaches the WAF, it gets organized into several logical sections to be analyzed: method, path, headers, and body. These sections are all stored in Lua variables. If you are interested in more detail on the implementation of the WAF itself you can watch this old presentation.
Before matching these variables against specific malicious request signatures, some transformations are applied. These transformations are functions that range from simple modifications like lowercasing strings to complex tokenizers and parsers looking to fingerprint certain malicious payloads.
As the WAF currently uses a variant of the ModSecurity syntax, this is what a rule might look like:
SecRule REQUEST_BODY "@rx /\x00+evil" "drop, t:urlDecode, t:lowercase"
It takes the request body stored in the REQUEST_BODY variable, applies the urlDecode() and lowercase() functions to it and then compares the result with the regular expression signature \x00+evil.
In pseudo-code, we can represent it as:
rx( "/\x00+evil", lowercase( urlDecode( REQUEST_BODY ) ) )
Which in turn would match a request whose body contained percent encoded NULL bytes followed by the word "evil", e.g.:
POST /cms/admin?action=post HTTP/1.1
Host: example.com
Content-Type: text/plain; charset=utf-8
Content-Length: 16
thiSis%2F%00eVil
The WAF contains thousands of these rules and its objective is to execute them as quickly as possible to minimize any added latency to a request. And to make things harder, it needs to run most of the rules on nearly every request. That’s because almost all HTTP requests are non-malicious and no rules are going to match. So we have to optimize for the worst case: execute everything!
To help mitigate this problem, one of the first matching steps executed for many rules is pre-filtering. By checking if a request contains certain bytes or sets of strings we are able to potentially skip a considerable number of expressions.
In the previous example, doing a quick check for the NULL byte (represented by \x00 in the regular expression) allows us to completely skip the rule if it isn’t found:
contains( "\x00", REQUEST_BODY )
and
rx( "/\x00+evil", lowercase( urlDecode( REQUEST_BODY ) ) )
Since most requests don’t match any rule and these checks are quick to execute, overall we aren’t doing more operations by adding them.
Other steps can also be used to scan through and combine several regular expressions and avoid execution of rule expressions. As usual, doing less work is often the simplest way to make a system faster.
Memoization
Which brings us to memoization - caching the output of a function call to reuse it in future calls.
Let’s say we have the following expressions:
1. rx( "\x00+evil", lowercase( url_decode( body ) ) )
2. rx( "\x00+EVIL", remove_spaces( url_decode( body ) ) )
3. rx( "\x00+evil", lowercase( url_decode( headers ) ) )
4. streq( "\x00evil", lowercase( url_decode( body ) ) )
In this case, we can reuse the result of the nested function calls (1) as they’re the same in (4). By saving intermediate results we are also able to take advantage of the result of url_decode( body ) from (1) and use it in (2) and (4). Sometimes it is also possible to swap the order functions are applied to improve caching, though in this case we would get different results.
A naive implementation of this system can simply be a hash table with each entry having the function(s) name(s) and arguments as the key and its output as the value.
Some of these functions are expensive and caching the result does lead to significant savings. To give a sense of magnitude, one of the rules we modified to ensure memoization took place saw its execution time reduced by about 95%:
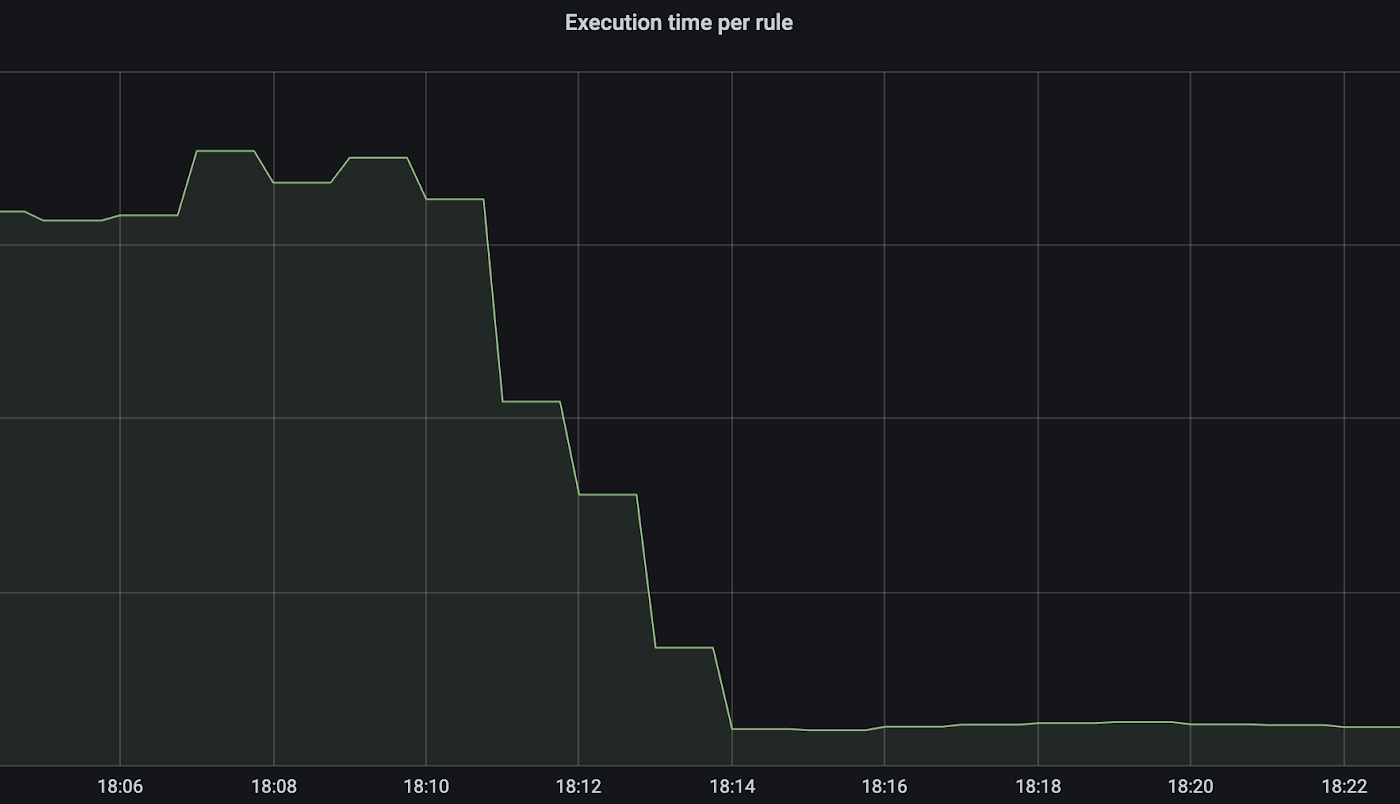
The WAF engine implements memoization and the rules take advantage of it, but there’s always room to increase cache hits.
Rewriting Rules and Results
Cloudflare has a very regular cadence of releasing updates and new rules to the Managed Rulesets. However, as more rules are added and new functions implemented, the memoization cache hit rate tends to decrease.
To improve this, we first looked into the rules taking the most wall-clock time to execute using some of our performance metrics:
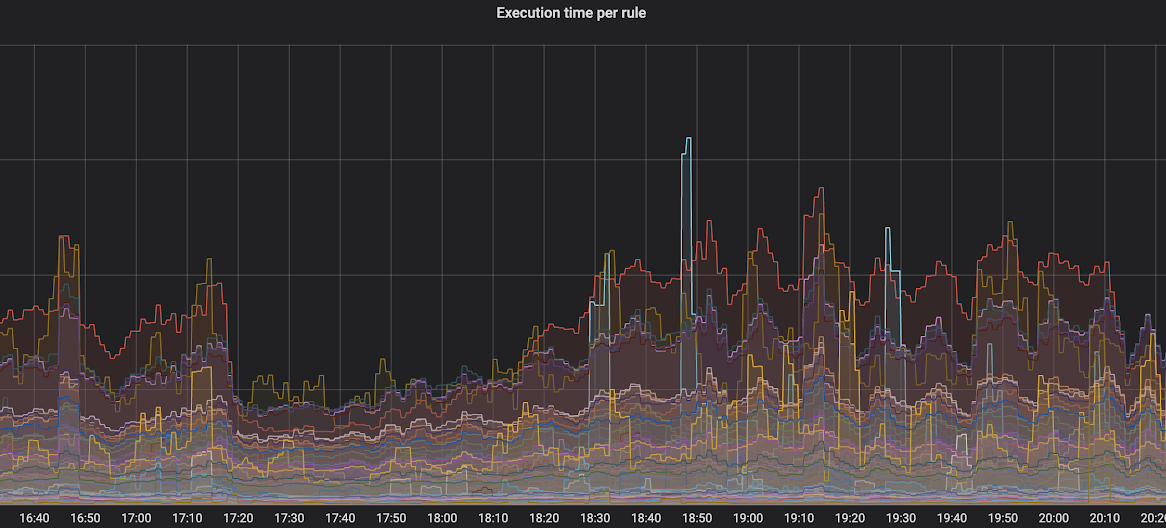
Having these, we cross-referenced them with the ones having cache misses (output is truncated with [...]):
$ ./parse.py --profile
Hit Ratio:
-------------
0.5608
Hot entries:
-------------
[urlDecode, replaceComments, REQUEST_URI, REQUEST_HEADERS, ARGS_POST]
[urlDecode, REQUEST_URI]
[urlDecode, htmlEntityDecode, jsDecode, replaceNulls, removeWhitespace, REQUEST_URI, REQUEST_HEADERS]
[urlDecode, lowercase, REQUEST_FILENAME]
[urlDecode, REQUEST_FILENAME]
[urlDecode, lowercase, replaceComments, compressWhitespace, ARGS, REQUEST_FILENAME]
[urlDecode, replaceNulls, removeWhitespace, REQUEST_URI, REQUEST_HEADERS, ARGS_POST]
[...]
Candidates:
-------------
100152A - replace t:removeWhitespace with t:compressWhitespace,t:removeWhitespace
100214 - replace t:lowercase with (?i)
100215 - replace t:lowercase with (?i)
100300 - consider REQUEST_URI over REQUEST_FILENAME
100137D - invert order of t:replaceNulls,t:lowercase
[...]
After identifying more than 40 rules, we rewrote them to take full advantage of memoization and added pre-filter checks where possible. Many of these changes were not immediately obvious, which is why we’re also creating tools to aid analysts in creating even more efficient rules. This also helps ensure they run in accordance with the latency budgets the team has set.
This change resulted in an increase of the cache hit percentage from 56% to 74%, which crucially included the most expensive transformations.
Most importantly, we also observed a sharp decrease of 40% in the average time the WAF takes to process and analyze an HTTP request at the Cloudflare edge.
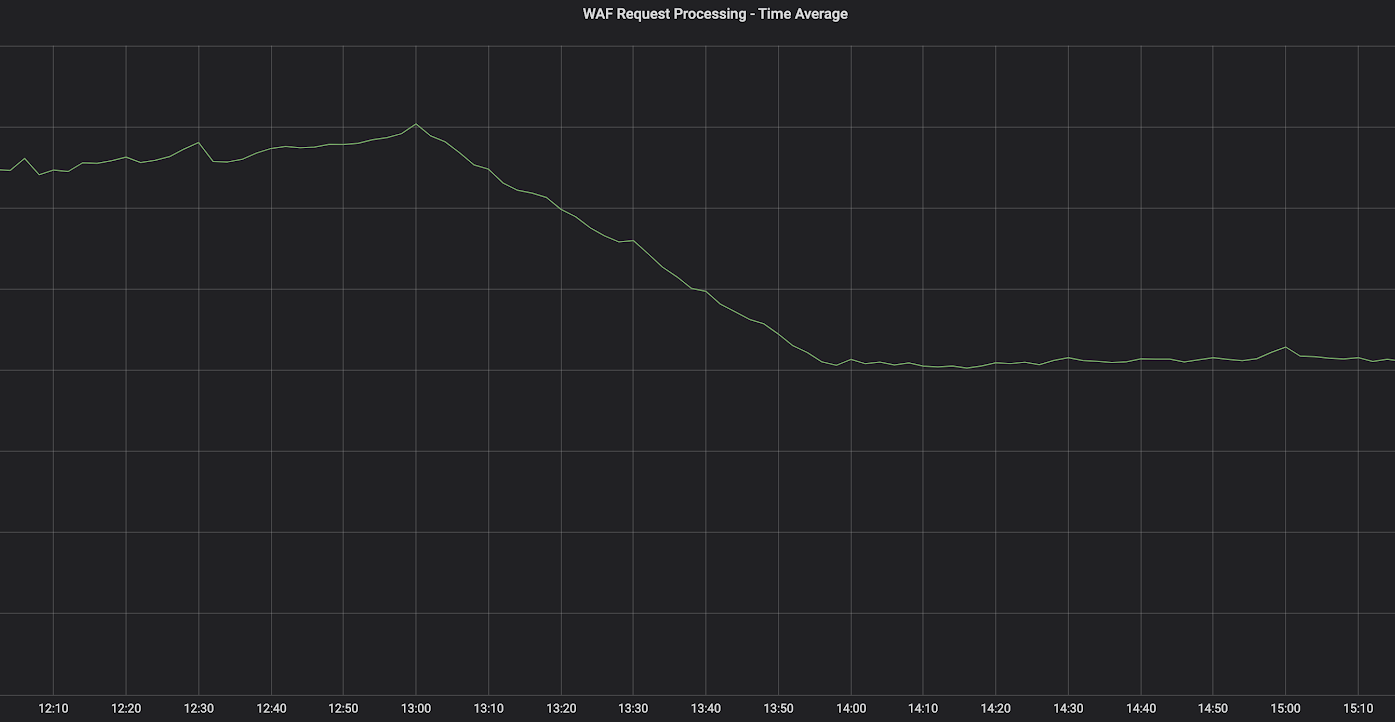
A comparable decrease was also observed for the 95th and 99th percentiles.
Finally, we saw a drop of CPU consumption at the edge of around 4.3%.
Next Steps
While the Lua WAF has served us well throughout all these years, we are currently porting it to use the same engine powering Firewall Rules. It is based on our open-sourced wirefilter execution engine, which uses a filter syntax inspired by Wireshark®. In addition to allowing more flexible filter expressions, it provides better performance and safety.
The rule optimizations we've described in this blog post are not lost when moving to the new engine, however, as the changes were deliberately not specific to the current Lua engine’s implementation. And while we're routinely profiling, benchmarking and making complex optimizations to the Firewall stack, sometimes just relatively simple changes can have a surprisingly huge effect.