
Just recently, I have been asked to look into what a Disaster Recovery site for InnoDB Cluster would look like.
If you’re reading this, then I assume you’re familiar with what MySQL InnoDB Cluster is, and how it is configured, components, etc.
Reminder: InnoDB Cluster (Group Replication, Shell & Router) in version 8.0 has had serious improvements from 5.7. Please try it out.
So, given that, and given that we want to consider how best to fulfill the need, i.e. create a DR site for our InnoDB Cluster, let’s get started.
Basically I’ll be looking at the following scenario:
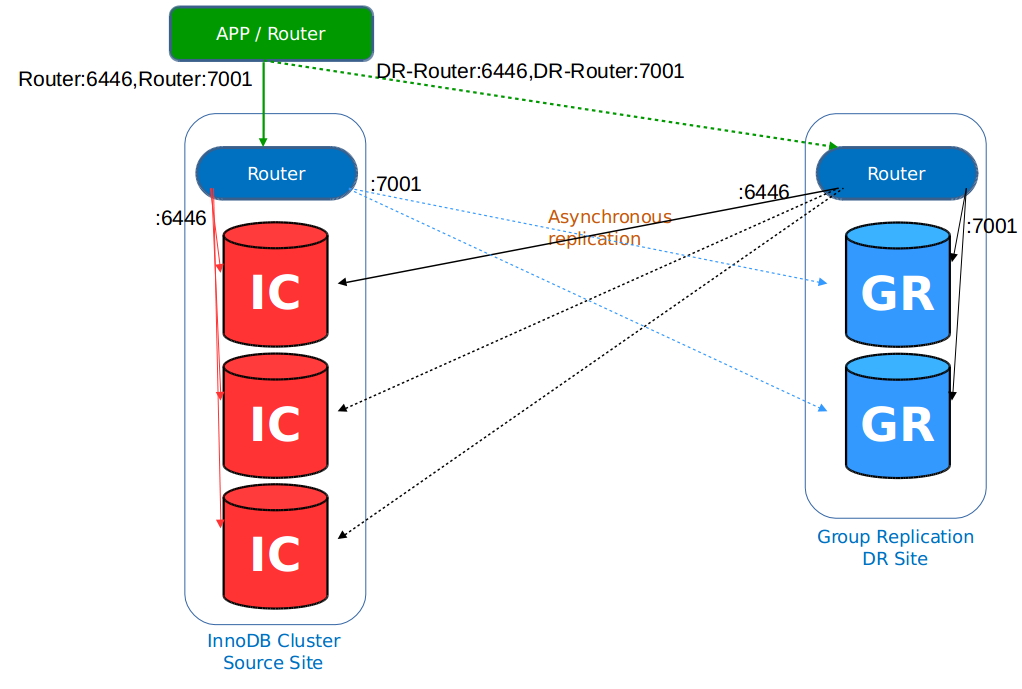
Now, just before we get into the nitty-gritty, here’s the scope.
Life is already hard enough, so we want as much automated as possible, so, yes, InnoDB Cluster gets some of that done, but there are other parts we will still have to assume control over, so here’s the idea:
Source Site:
– InnoDB Cluster x3
– Router
– Accesses Source (Dynamic) & DR (Static)
– Full Automation
DR Site:
– Group Replication x2
– Router
– Accesses Source (Dynamic) & DR (Static)
– Configured Asynchronous Replication from Primary node.
External / LBR 3rd Site:
– MySQL Router (static) routing connections to Source Router
– Allowing for 2 instance automatic failovers at Source site.
– Manually reroute connections to DR site once Source Site outage confirmed or use different Router port.
– Redundancy recommended to reduce SPOF.
Let’s get it all started then.
First things first, if you’re not quite sure what you’re doing, then I highly suggest looking at the following:
https://thesubtlepath.com/mysql/innodb-cluster-managing-async-integration/
Replicating data between two MySQL Group Replication sets using “regular” asynchronous replication with Global Transaction Identifiers (GTID’s)
(And thanks to Andrew & Tony for their continuous help!)
Let’s set up our Source Site
- 3x CentOS 7 servers.
- 8.0.20: Server, Shell & Router.
:: All servers have had their SELinux, firewalls, ports, /etc/hosts and so on checked and validated, haven’t they? We will want to be using a private IP between all hosts, for obvious reasons..
I downloaded all the MySQL Enterprise rpm’s from https://edelivery.oracle.com and run the following on all 3 servers (getting mystic here: “centos01”, “centos02” & “centos03”):
sudo yum install -y mysql-*8.0.20*rpm
sudo systemctl start mysqld.service
sudo systemctl enable mysqld.service
sudo grep 'A temporary password is generated for root@localhost' /var/log/mysqld.log |tail -1
mysql -uroot -p
Once we’re in, we want to control what command get into the binlogs, and the ”alter user’ and create user’ will cause us issues later on, hence “sql_log_bin=OFF” here:
SET sql_log_bin = OFF; alter user 'root'@'localhost' identified by 'passwd'; create user 'ic'@'%' identified by 'passwd'; grant all on . to 'ic'@'%' with grant option; flush privileges; SET sql_log_bin = ON;
This “ic@%” user will be used throughout, as we just don’t know when and which instance will end up being the source primary and/or a clone so by using this single user setup, I keep things easier for myself. For your production setup, please look deeper into specific privs ‘n’ perms.
mysqlsh --uri root@localhost:3306
dba.checkInstanceConfiguration('ic@centos01:3306')
dba.configureInstance('ic@centos01:3306');
Say “Y” to all the restarts n changes.
On just one of the servers (this will be our Single Primary instance):
\connect ic@centos01:3306
cluster=dba.createCluster("mycluster")
cluster.status()
cluster.addInstance("ic@centos02:3306")
cluster.addInstance("ic@centos03:3306")
cluster.status();
Now, you will see that, although we have installed the binaries and started up the instances on centos02 & centos03, “addInstance” goes and clones our primary. This makes life soooo much easier.
HINT: Before cloning, if you need to provision data, do it prior and we kill a couple of proverbial birdies here.
Now we have a 3 instance Single Primary InnoDB Cluster.
Setting up the local “InnoDB Cluster aware” Router:
mkdir -p /opt/mysql/myrouter chown -R mysql:mysql /opt/mysql/myrouter cd /opt/mysql mysqlrouter --bootstrap ic@centos02:3306 -d /opt/mysql/myrouter -u mysql ./myrouter/start.sh
Now Router is up and running.
Let’s set up our Group Replication Disaster Recovery site now.
Here, I’m doing a naughty, and just setting up a 2 node Group Replication group. If you want to see how you should be doing it, then let me reference Tony again:
MySQL 8.0 Group Replication – Three-server installation
:: Again, ports, firewalls, SELinux, /etc/hosts n similar have been validated again? Please?
The environment:
- 2x Oracle Linux 7 servers.
- Version 8.0.20: MySQL Server, Router & Shell
Do the following on both replica servers (olrep01 & olrep02):
sudo yum install -y mysql-8.0.20rpm
sudo systemctl start mysqld.service
sudo systemctl enable mysqld.service
sudo grep 'A temporary password is generated for root@localhost' /var/log/mysqld.log |tail -1
mysql -uroot -p
SET sql_log_bin = OFF; alter user 'root'@'localhost' identified by 'passwd'; create user 'ic'@'%' identified by 'passwd'; grant all on . to 'ic'@'%' with grant option; flush privileges; SET sql_log_bin = ON;
No we have basic servers created, we need to clone the data from the Primary instance in our InnoDB Cluster.
This means installing the mysql_clone plugin.
On cluster Primary node:
SET sql_log_bin = OFF;
INSTALL PLUGIN CLONE SONAME "mysql_clone.so";
GRANT BACKUP_ADMIN ON . to 'ic'@'%';
GRANT SELECT ON performance_schema.* TO 'ic'@'%';
GRANT EXECUTE ON . to 'ic'@'%';
SET sql_log_bin = ON;
Now on each replica:
INSTALL PLUGIN CLONE SONAME "mysql_clone.so"; INSTALL PLUGIN group_replication SONAME 'group_replication.so'; SET GLOBAL clone_valid_donor_list = 'centos02:3306'; GRANT CLONE_ADMIN ON . to 'ic'@'%'; # Keep this, if we ever want to clone from any of the replicas GRANT BACKUP_ADMIN ON . to 'ic'@'%'; GRANT SELECT ON performance_schema.* TO 'ic'@'%'; GRANT EXECUTE ON . to 'ic'@'%';
Now to execute the clone operation:
set global log_error_verbosity=3; CLONE INSTANCE FROM 'ic'@'centos02':3306 IDENTIFIED BY 'passwd';
View how the clone process is going:
select STATE, ERROR_NO, BINLOG_FILE, BINLOG_POSITION, GTID_EXECUTED,
CAST(BEGIN_TIME AS DATETIME) as "START TIME",
CAST(END_TIME AS DATETIME) as "FINISH TIME",
sys.format_time(POWER(10,12) * (UNIX_TIMESTAMP(END_TIME) - UNIX_TIMESTAMP(BEGIN_TIME))) as DURATION
from performance_schema.clone_status \G
As we’re cloning, we might run into the duplicate UUID issue, so, on both of the replicas, force the server to have a new UUID:
rm /var/lib/mysql/auto.cnf
systemctl restart mysqld
Setting up the Group Replication config
In node 1:
vi /etc/my.cnf # GR setup server-id =11 log-bin =mysql-bin gtid-mode =ON enforce-gtid-consistency =TRUE log_slave_updates =ON binlog_checksum =NONE master_info_repository =TABLE relay_log_info_repository =TABLE transaction_write_set_extraction=XXHASH64 plugin_load_add ="group_replication.so" group_replication = FORCE_PLUS_PERMANENT group_replication_bootstrap_group = OFF #group_replication_start_on_boot = ON group_replication_group_name = 8E2F4761-C55C-422F-8684-D086F6A1DB0E group_replication_local_address = '10.0.0.41:33061' # Adjust the following according to IP's and numbers of hosts in group: group_replication_group_seeds = '10.0.0.41:33061,10.0.0.42:33061'
On 2nd node:
server-id =22 log-bin =mysql-bin gtid-mode =ON enforce-gtid-consistency =TRUE log_slave_updates =ON binlog_checksum =NONE master_info_repository =TABLE relay_log_info_repository =TABLE transaction_write_set_extraction=XXHASH64 plugin_load_add ="group_replication.so" group_replication = FORCE_PLUS_PERMANENT group_replication_bootstrap_group = OFF #group_replication_start_on_boot = ON group_replication_group_name = 8E2F4761-C55C-422F-8684-D086F6A1DB0E group_replication_local_address = '10.0.0.42:33061' # Adjust the following according to IP's and numbers of hosts in group: group_replication_group_seeds = '10.0.0.41:33061,10.0.0.42:33061'
Restart both servers:
systemctl restart mysqld
Check they’re in a GR group and the plugin is ok:
mysql -uroot SELECT * FROM performance_schema.replication_group_members; SELECT * FROM performance_schema.replication_group_members\G select * from information_schema.plugins where PLUGIN_NAME = 'group_replication'\G
Now to create the recovery replication channel on all servers (although this is for single primary setup, the source could fail and then come back as a Read-Only replica, so we need to set this up):
CHANGE MASTER TO MASTER_USER='ic', MASTER_PASSWORD='passwd' FOR CHANNEL 'group_replication_recovery';
On Server 1:
SET GLOBAL group_replication_bootstrap_group=ON;
START GROUP_REPLICATION;
SET GLOBAL group_replication_bootstrap_group=OFF;
On Server 2:
START GROUP_REPLICATION;
Check all the servers super_read_only mode and if they’re in a group:
select @@super_read_only; SELECT * FROM performance_schema.replication_group_members;
Set up Router on one of the replicas bootstrapping against the InnoDB Cluster source:
mkdir -p /opt/mysql/myrouter
chown -R mysql:mysql /opt/mysql/myrouter
mysqlrouter --bootstrap ic@centos02:3306 -d /opt/mysql/myrouter -u mysql
cd /opt/mysql/myrouter
./start.sh
Check connectivity:
mysql -uic -P6446 -h olrep01 -N -e "select @@hostname, @@port" mysql -uic -P6446 -h centos02 -N -e "select @@hostname, @@port"
Replication config for replicas
Setting up replication for the replica from the primary means that we MUST be prepared to script the following for when the primary fails in the group replication setup, or keep the following command at hand, as it isn’t automatic so we’ll need to control this ourselves.
Also, albeit a Group Replication group, when the primary fails n the DR site, we will also need to check all connections and sessions to the GR DR site to make sure we can set this up safely.
So, from the PRIMARY instance only, execute the following:
CHANGE MASTER TO MASTER_HOST = 'olrep01', MASTER_PORT = 6446, MASTER_USER = 'ic', MASTER_PASSWORD = 'passwd', MASTER_AUTO_POSITION = 1 FOR CHANNEL 'idc_gr_replication' ;
As you can see, this is replicating via the GR DR site Router that is bootstrapped against the InnoDB Cluster. Hence when the primary on the cluster moves, Router will take us to the new primary without having to re-create replication or similar.
Now let’s start it all up:
start slave ;
And have a look at our InnoDB Cluster source site replicating data to our DR Group Replication site:
show slave status for channel 'idc_gr_replication'\G
Application Connectivity
Now we have a HA solution for our data, what about connecting to one and the other.
We have 2 routers, each local to each data-saving site, fine. But, if we’re being realistic, we have 1 data entry point, the InnoDB Cluster Primary instance on centos01, and then 4 copies of the data, syncing nicely between a (dedicated? please?) local network to ensure we’re as safe as possible.
As you’ll probably have noticed, upon bootstrapping Router on both sides, it chooses the routing_strategy=first_available on the default port 6446 which is fine. And yes, this port can be changed if we want to, so feel free to adjust as required.
But, depending on where the application is, and the user entry point, you’ll have a VIP, floating IP or something similar halping to load balance maybe. But here is where we start to ask more questions:
What happens when the Source site goes down?
eg:

Well, there are a number of things to keep in mind. The local Routers will take care of instance failures, and here, I feel obliged to forewarn you all about what happens when we loose 2 out of 3 instances on the source site. Here, the last instance could be configured to have group_replication_exit_state_action=’OFFLINE_MODE’ or ABORT for example. That way, it doesn’t get used as a valid node via Router.
Now, once that has happened, i.e. the source site goes down, we need to manually intervene, and make sure that everything is really down, and kick into effect the DR site. Now both Routers on Source & DR site that were bootstrapped to the InnoDB Cluster will fail of course.
We are left with the Group Replication DR site.
So what do we do here? Well, create an additional Router, configured with a static (non-dynamic) setup, as we don’t have the metadata that the IdC-aware Router had via the mysql_innodb_cluster_metadata schema that gets stored in “dynamic_state=/opt/mysql/myrouter/data/state.json”.
What I did was create a new Router process on one of the other servers (instead of centos02 & olrep01, on centos01 & olrep02). Now this isn’t something you’d do in Production as we want Router close to the app, not the MySQL instances. So in effect you could just use a new path ,eg.
mkdir -p /opt/mysql/myrouter7001
chown -R mysql:mysql /opt/mysql/myrouter7001
cd /opt/mysql/myrouter7001
vi mysqlrouter.conf
[routing:DR_rw] bind_address=0.0.0.0 bind_port=7001 destinations=olrep01:3306,olrep02:3306 routing_strategy=first-available protocol=classic
Once configured, start them up:
mysqlrouter --user=mysql --config /opt/mysql/myrouter7001/mysqlrouter.conf &
test:
mysql -uic -P7001 -h olrep02 -N -e "select @@hostname, @@port" mysql -uic -P7001 -h centos01 -N -e "select @@hostname, @@port"
And this will give us back olrep01, then when that fails, olrep02.
When the InnoDB Cluster-bootstrapped-Router that listens on 6446 fails, we know to redirect all requests to port 7001 on our production IP’s (in my case, olrep02 & centos01).
Summing up, we’ve now got 4 routers running, 2 are InnoDB Cluster aware, listening on 6446, and the static GR DR Routers are listening on 7001.
That’s a lot of ports and a long connect string. Maybe we could make this simpler?
Ok, well I added yet another Router process, high level. This Router process, again, has a hard-coded static configuration, because we don’t have InnoDB Cluster-aware Routers on both sides, which means having a mysql_innodb_cluster_metadata schema on both sides, fully aware of both InnoDB Clusters, and also fully aware that metadata changes on the source are NOT to be replicated across. Who knows.. maybe in the future…
So in my case I created another Router process configuration on centos03:
mkdir -p /opt/mysql/myrouter chown -R mysql:mysql /opt/mysql/myrouter cd /opt/mysql/myrouter
(You might want to use something different, but I did this. I could have all of these on the same server, using different paths. There isn’t any limit to how many Router processes we have running on the same server. It’s more a “port availability” or should I say “network security” concern)
vi mysqlrouter.conf:
[routing:Source_rw] bind_address=0.0.0.0 bind_port=8008 destinations=centos02:6446,olrep01:6446 routing_strategy=first-available protocol=classic [routing:DR_rw] bind_address=0.0.0.0 bind_port=8009 destinations=centos01:7001,olrep02:7001 routing_strategy=first-available protocol=classic
Just in case I’ve lost you a little, what I’m doing here is providing a Router access point via centos03:8008 to the InnoDB-Cluster-aware Routers on centos02:6446 and olrep01:6446. And then an additional / backup access point to the static Routers on centos01: 7001 and olrep02:7001. The app would then have a connect string similar to “centos03:8008,centos03:8009”.
Now, I know to send Source site connections to centos03:8008 always. And when I get errors and notifications from monitoring that this is giving problems, I can use my back up connection to centos03:8009.
Side note: I originally setup the single Router process on each side, but with a mix of InnoDB Cluster aware entry and an additional static configuration. This didn’t work well as really, having bootstrapped against the IdC, the dynamic_state entry only allows for the members taken from the mysql_innodb_cluster_metadata schema. So it won’t work. Hence, the additional router processes. But if you think about it, making each Router more modular and dedicated, it makes for a more atomic solution. Albeit a little more to administer.
However, maybe instead of this high-level Router process listening on 8008 & 8009, you want to reuse your keepalived solution. Have a look at Lefred’s “MySQL Router HA with Keepalived” solution for that.
And there you have it!
This was all done on Oracle Cloud Infrastructure compute instances, opening ports internally within the Security List and not much else.
