
When developers work with text, they often need to clean it up first. Sometimes it’s by replacing keywords. Like replacing “Javascript” with “JavaScript”. Other times, we just want to find out whether “JavaScript” was mentioned in a document.
Data cleaning tasks like these are standard for most Data Science projects dealing with text.
Data Science starts with data cleaning.
I had a very similar task to work on recently. I work as a Data Scientist at Belong.co and Natural Language Processing is half of my work.
When I trained a Word2Vec model on our document corpus, it started giving synonyms as similar terms. “Javascripting” was coming as a similar term to “JavaScript”.
To resolve this, I wrote a regular expression (Regex) to replace all known synonyms with standardized names. The Regex replaced “Javascripting” with “JavaScript”, which solved 1 problem but created another.
Some people, when confronted with a problem, think
“I know, I’ll use regular expressions.” Now they have two problems.
The above quote is from this stack-exchange question and it came true for me.
It turns out that Regex is fast if the number of keywords to be searched and replaced is in the 100s. But my corpus had over 10s of Thousands of keywords and a few Million documents.
When I benchmarked my Regex code, I found it was going to take 5 days to complete one run. My reaction:

Clearly something needed to be done.
[Update]
I started with trying to optimise the Regex I was using. I learned that compiled regex are faster so I switched to it. To replace multiple terms together ther is group option and I adapted that. I was still having trouble with keywords having special characters like 'C++', '.Net' Link.
Sorting the keywords when loading into regex also improved the performance.
My best learnings came from this Link. Trie Based regex are faster Link I didn't Know about this when I started my project, But I went in the same direction of using a Trie.
I don't mean to say that Regex in general are bad, It's just really hard to understand so many different implementations. I was using the Python version, where as RUST has a compiled version which is even faster. Also there are c++ versions which are even more faster.
If you are solely looking for speed maybe you can try one of those. I needed more control and simplicity in use so I built a tool. This helped me abstract the details out making sure anyone with little knowledge of Regex could use it.
[Update End]
I asked around in my office and on stack-overflow. And a couple of suggestions came up. Both Vinay, Suresh and Stack Overflow pointed towards this beautiful algorithm called Aho-Corasick algorithm and Trie dictionary approach. I looked for some existing solutions but couldn’t find much.
So I wrote my own implementation and FlashText was born.
Before we get into what is FlashText and how it works, let’s have a look at how it performs.
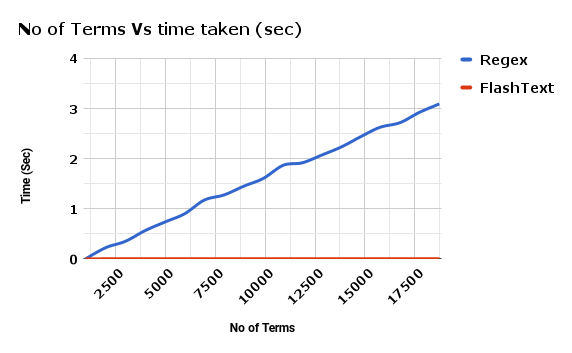
Time taken by FlashText to find terms in comparison to Regex.

The chart shown above is a comparison of Complied Regex against FlashText for 1 document. As the number of keywords increase, the time taken by Regex grows almost linearly. Yet with FlashText it doesn’t matter.
FlashText reduced our run time from 5 days to 15 minutes!!

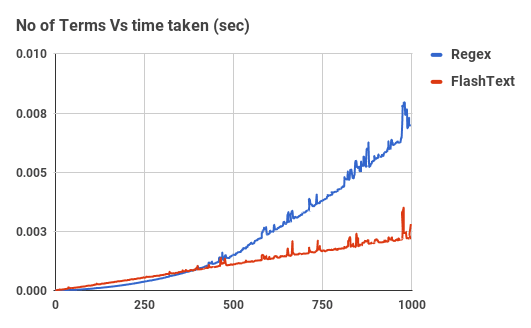
Time taken by FlashText to replace terms in comparison to Regex.
Code used for the benchmark shown above is linked here, and here.
So what is FlashText?
FlashText is a Python library that I open sourced on GitHub. It is efficient at both extracting keywords and replacing them.
To use FlashText first you have to pass it a list of keywords. This list will be used internally to build a Trie dictionary. Then you pass a string to it and tell if you want to perform replace or search.
For replace it will create a new string with replaced keywords. For search it will return a list of keywords found in the string. This will all happen in one pass over the input string.
Here is what one happy user had to say about the library:
 Radim Řehůřek@radimrehurek
Radim Řehůřek@radimrehurek @arnicas 28x faster than a compiled regexp for 1k keywords & ~10k tokens per document. Nice @vi3k6i5!
@arnicas 28x faster than a compiled regexp for 1k keywords & ~10k tokens per document. Nice @vi3k6i5!
Pure Python t… twitter.com/i/web/status/9…08:48 AM - 05 Sep 2017


Radim Rehurek is the creator of Gensim.
Why is FlashText so fast ?
Let’s try and understand this part with an example. Say we have a sentence which has 3 words I like Python, and a corpus which has 4 words {Python, Java, J2ee, Ruby}.
If we take each word from the corpus, and check if it is present in sentence, it will take 4 tries.
is 'Python' in sentence?
is 'Java' in sentence?
...
If the corpus had n words it would have taken n loops. Also each search step is <word> in sentence? will take its own time. This is kind of what happens in Regex match.
There is another approach which is reverse of the first one. For each word in the sentence, check if it is present in corpus.
is 'I' in corpus?
is 'like' in corpus?
is 'python' in corpus?
If the sentence had m words it would have taken m loops. In this case the time it takes is only dependent on the number of words in sentence. And this step, is <word> in corpus? can be made fast using a dictionary lookup.
FlashText algorithm is based on the second approach. It is inspired by the Aho-Corasick algorithm and Trie data structure.
The way it works is: First a Trie dictionary is created with the corpus. It will look somewhat like this
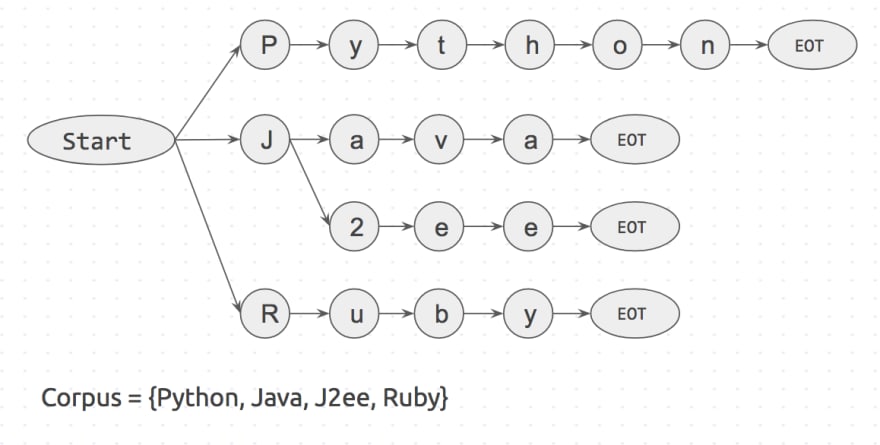
Start and EOT (End Of Term) represent word boundaries like space, period and new_line. A keyword will only match if it has word boundaries on both sides of it. This will prevent matching apple in pineapple.
Next we will take an input string I like Python and search it character by character.
Step 1: is <start>I<EOT> in dictionary? No
Step 2: is <start>like<EOT> in dictionary? No
Step 3: is <start>Python<EOT> in dictionary? Yes

Since this is a character by character match, we could easily skip <start>like<EOT> at <start>l because l is not connected to start. This makes skipping missing words really fast.
The FlashText algorithm only went over each character of the input string ‘I like Python’. The dictionary could have very well had a million keywords, with no impact on the runtime. This is the true power of FlashText algorithm.
You can get similar speed by building Trie based Regex Link
So when should you use FlashText?
Simple Answer: When Number of keywords > 500
Complicated Answer: Regex can search for terms based on regular expression special characters like ^,$,*,\d,. all this is not supported in FlashText. All FlashText understands the Start and End of terms. Simply speaking it understands \w,\b.
So it’s no good if you want to match partial words like word\dvec. But it is excellent for extracting complete words like word2vec.
How to use FlashText
To Find Terms:
To Replace Terms:
What Next?
If you know someone who works on Entity recognition, NLP, Word2vec, Keras, Tensorflow please share this blog with them. This library has been really useful for us. I am sure it would be useful for others also.
Originally posted here
:wq





Top comments (46)
It seems like you discovered that regex is not the right tool for keyword detection or replacement :)
I like how you explain the role of tries in you eventual solution. I learned from your 'mistake', so thanks for writing.
Thanks :) Completely agree that one size fit all doesn't work. It's just that when we start, we start with a simpler problem and sometimes to scale we need to re-think at an algorithmic level.
PS: Thanks for your feedback :)
I've read your article on Medium, and my reaction was that regular expressions simply weren't the right choice.
I really like regular expressions but they have to be used for some kind of tasks, not as a sledgehammer to open a door, when a lockpick could be also available.
Good for you that you've found the lockpick. Even with a language as slow as Python, the difference could be of several orders of magnitude. The point is that regular expressions are a pseudo-language on its own, with its rules and principles.
Remember, you wouldn't use regexes to parse HTML.
But that's because html isn't regular... I don't want to be "that guy", but regular expressions is definitely the lockpick, and this trie-stuff is the sledgehammer. Whenever you can use re, you should, because it's the absolutely fastest and simplest you can do. It's just that many re libraries out there are pretty slow and unintuitive to use...
I'll leave this here:
Now, I think this is extremized, and regular expressions do have a place in development (and I also like them a lot in general), but there are very critical aspects to consider:
There a lot of cases where you can use regular expressions, but a lot less where you should use them. I'll also leave this:
(Now that's another hyperbole, but the point is that we have to maintain the code we write, so it's better to make out life easier.)
And that's indeed another aspect to consider: many regex engines are slow to boot but we have to deal with that, because we simply just have no alternatives. And also have awkward APIs, too.
So, should we use them anyway, you say?
Sure, that quote is fun, but it doesn't carry a very strong point.
The language and what you can do with it is standardized - unions, differences, kleene stars and so on. The rest is just syntax.
A well designed regex engine is a finite automata. That's it.
I don't think this is too hard to read.
Maybe.
Of course you can step-by-step a RE. It's just a finite automata; just step though it.
But we do have alternatives. Ragel, as mentioned above, is a really good one. re2 for python is supposedly good. The rust regex is good. Alex is also pretty good.
Not so easy. The point is that you can't transpose a regular expression from a different language without any second thinking. It means that regular expressions are another layer of programming language that you have to take into consideration.
A computer doesn't care what a regex is. You shouldn't either, as it doesn't make any difference. The implementation can be very different and something that should be cared about.
That's not a regular expression: it's a list of definitions used by a regex engine.
Only if you have a library that replicate a regex engine. In many languages, you just use the regular expression engine that's natively implemented, because any non-native solution is usually several orders of magnitude slower, it's basically a reinvented wheel, and it just adds another dependency to the project.
If it's slower and takes additional configuration, the "fastest and simplest you can do" part simply disappears.
In some languages maybe they're worth considering. But nobody uses a custom regex engine in JavaScript, or in PHP, or in Python, except for very limited cases.
I never, ever get tired of that post. Such an important lesson for all developers!
Super, super cool! Did you try comparing it to a regex with branching by any chance as well? ie, for finding "python" or "java" or "javascript", did you do
~(java(script)?|python)~or~(javascript|java|python)~? I'm just curious; I suspect yours would be faster regardless!Hey Shemayev,
What I did was something like this:
\b(javascript|java|python)\b. I didn't benchmark it against something that you are suggesting~(java(script)?|python)~I will look at it sometime :) Thanks for the suggestion. Building it for 10K+ keywords will be really hard though. I will try :)Those days I often work on NLU so that sounds pretty good.
It would be interesting to apply a normalizing function on the input text, just for matching. Something like:
This would help normalizing the writing of keywords without screwing the whole sentence.
@remy : Sorry, I didn't get that completely. Can you please elaborate on the expected output and how normalise function is making it happen?
Suppose that your input is one of
My name is remyMy name is RÉMYMy name is RémyThen your output would be
My name is RémyIt's like when you say you want to replace different instances of
JavaScript. If you wantJavaScriptformated the same way all the time then you can use this technique to achieve that.That can already be done right?
Yup but then you're getting
my name is Rémyinstead ofMy name is Rémy.Also it would allow to process the string without holding it several times in memory (and thus possibly to work on a stream). If you're dealing with big texts it might be interesting as well
I don't have a direct application right now though, but from the things I usually do I'm guessing it would make sense.
Ok Remy, Btw, if we change normalize method to not lower the text your requirement will be solved.
Also, if I call normalize from within FlashText or outside FlashText it will be the same amount of memory and computation.
Still, I will keep looking for a possible use case for your suggestion. Thanks for bringing it up :) :)
I just want to clarify that regular expressions, by the themselves, is not the problem - indeed regular expressions is the theoretically fastest way to parse a string and always grows linearly with the input string length (never by "regex complexity") - the problem is pythons re library and replacement.
Cool nonetheless.
I would be interested in the comparison between flashtext versus RE2. In my experience you almost always want to use RE2 in any language that supports it. It is vastly faster than any other real RE implementation I've used and its limitations (i.e., you can't use the non-regular PCRE features) only stop you from doing things you shouldn't be doing with a regular expression anyway.
I agree. I would be even more interested in a comparison between flashtext and a well designed Ragel parser (or similar; I've heard that the Rust RE is pretty good too).
I will checkout RE2 and Ragel. I had tried Regex in java also and some advanced Regex libraries in python.
The conclusion I came to was that FlashText is fast because it doesn't do backtracking. Any Regex library that does backtracking would be slower, time complexity wise. C/C++ might execute faster, but backtracking will be slow Algo.
I will still checkout the libraries you guy suggested, Thanks :)
Yes -- RE2 doesn't do backtracking precisely so that it can run faster, which is why I thought it would be an interesting comparison. Here is a page that describes the basic idea, and here is a larger pool of resources for efficient regex implementation (considering "real" regular expressions only, not PCRE-compatible regexes that may contain non-regular constructs that would need to be implemented with backtracking).
Hmm. I applaud you for creating a library that is useful, but, having a solution that works in 5 days - If you had a multi-core machine you might have used N instances of your regex program running on 1/n'th of your inputs to get it down to running in, say, a day?
Given hundreds of replacements, I would have at least got estimated run times for that version where you look up each word in a dictionary of replacements.
(Simplistically):
out = ' '.join([lookup.get(word, word) for word in text.strip().split()])But the community gains a new tool! I applaud you sir :-)
@paddy3118 FlashText is designed to deal with multi term keywords like
'java script' getting replaced with 'javascript'. There is also the problem of extracting java fromI like java.(notice the full stop in the end). There are multiple other problems with assuming that this problem is as simple as you assumed it to be.PS: You assuming that I wouldn't have tried your suggestion is fine, but you assuming that everyone who clapped are not smart enough to figure your suggestion by themselves is not.
Not sure of what you are accusing me of there?
On the comment on what makes a word, and multi-word lookups then solving those issues could be thought of as a task you would have to do for your new library, but the new library then goes on to use a trie whereas dicts are a built-in datatype.
I am sorry, I can't help you. Let's move on in life and do better things :)
All the best :)
What you are doing does not even seem like a job for a Regex.
Regex is a pattern matching engine (like globbing).
A good example for what to use Regexes is filtering non-comment lines in config files (
/^\s*(#|$)/), as this requires an actual pattern.Another good thing about Regexes is their grouping
There's a pretty good reason why, at work, I am always using
grep -rF foobar /etcovergrep -re foobar /etcwhen looking for something.Instead of
It's not that regex is slow either, it's just that you are creating a terrible overhead by using it even though you don't even use the overhead for anything.
What you probably want is lazily splitting the input by whitespace and using a replacement-map (as seen here).
There's a few important things with that:
If search&replacing in a large body of text: don't load it to memory.
You will end up replacing variable-length text, so you're either going to need some sort of Rope, or you're running into performance problems, due to lots of copies and/or reallocations.
Best thing to do is lazily reading the file and outputting it somewhere else (preferably reading stdin and writing to stdout, that way the program is very easy to use).
Second, you might want to take a look at PHF tables.
Rust has a great library for that which generates the PHF table at compile time, so that at runtime it only hashes the value with a very fast and efficient algorithm and does a single comparison to get the desired value of the map.
Update
I did implement this using the above methods (in Rust though).
The PHF is raising the compile time, currently ~12 seconds for ~50k replacement entries, which is quite okay I guess.
Runtime scales linearly with the wordlist-length:
Out of curiosity, how long would a simple replace() take on your document set? Regular expressions are a good tool to use when you need to do complex matches, but are pretty inefficient when you're doing a simple text replacement.
str.replace()is likely to be far more efficient thanre.sub()when you're just doing simple string matching and not really using any of the power of regular expressions.To be clear, it's still likely to be a good bit slower than FlashText, but I'm just curious what the difference is.
Hey Vinay,
I had 10K+ terms. It simply didn't make sense to do 20K replace calls. Plus I need word boundaries to be honoured, So the only choice for me was some re library. Hope that answers your question.
PS: each
str.replace()will go over the entire document/string. so 20K * no of docs (will be too much complexity. + it won't take word boundaries into consideration.Thanks for sharing. Please try wReplace for 'massive' 500+ replacement:
(just Google for 'wReplace', I can't put links here).
Tell me if it fits your needs. If possible, please share/point me to your benchmark data.
Sure, Benchmark code is linked in the article
From the article
Code used for the benchmark shown above is linked here, and here.
is wReplace a UI based tool ? Is there an API interface for the library??
Building your own regex or string matching library is a rewarding experience.
That being said, this is familiar terrain. We built Hyperscan ( github.com/intel/hyperscan ) several years ago. I would hope it runs your workload faster than 5 days, and as a bonus extra, you can use multiple regular expressions, not just fixed literal strings.
Cool I will check it out Geoff.
There are very good Regex libraries out there, no question. But what is the best library, If I don't want to match a regular expression, rather just words with word boundaries?
I didn't find anything solving the problem I was facing (I googled and tried libraries for weeks before giving up and writing my own).. I am very lazy that way, Avoiding work till it's not an absolute necessity :D.
My use case does not involve multiple regular expressions, I do NLP and I deal with a lot of strings. I found it as a good use-case, hence wrote the library :)
PS: In my company we have built quite a few projects around it, and I didn't even ask people to use it, they started using it on their own accord. So I guess it's a good validation that there was a requirement for such a library :)
Multiple string match is a fun problem. I wrote a number of the subsystems that went into Hyperscan as "literal matchers": an early system that used hashing (essentially multiple hash function Rabin-Karp), a large-scale 'bucketed shift-or' algorithm called FDR, and a small-scale - up to about 96 literals - SIMD algorithm called Teddy).
I've also played around with a few other ideas; a favorite recent one is using PEXT (BMI2 instruction on Haswell and beyond) to look up a series of tables. This nice part of this is that you can pick which bits you want to key on (unlike hashing). So if you have a bunch of short strings (say 1 character) and someone has also given you a gazillion strings ending in the same suffix but differing a fair bit at, say, the 40th through 46th bit from the end, you can use PEXT to pull out those particular bits (say 0..7 and 40..46) and look up a table that tells you instantly whether you have one of your short strings and also helps reduce the number of strings you have to check if you have one of your difficult suffixes.
The Holy Grail here is a nice reliable string matching library that has good performance in the bad case but can hit 1 cycle per byte on non-matching traffic.
Aho-Corasick is a good solid algorithm, but the main problem with in IMO is that it's one damn thing after another; specifically a series of reads that depend on the previous state and the data. So it's never going to go all that fast (but it is extremely reliable and not too hard to understand).
Most people will reach for regexes (re.sub(r'foo', 'bar', article)) when what they want is replace (article.replace('foo','bar')) plus some tokenization. I'd bet that using replace + a loop on a vector of keywords/replacements would be faster then tries (though less space efficient).
I love Tries. They are my go-to data structure when performance is needed. I've used them to solve dice letter games, create a search suggestion service, and more.
Cool :) I am also loving Tries so much more now :)
It is trending on reddit! Awesome discussions there....
redd.it/7j3433
Hey Lilly,
Thanks for sharing.. Facing a simple problem with Trie re. Would love to switch though, if I get some help with this.
Ah, as I thought; tries in Python are not as fast, (or as simple), as using a dict based solution: paddy3118.blogspot.co.uk/2017/12/n...
Tries tend to do that, be fast :D
Couldn't solutions like elastic search or such be used to also modify texts? or they are only for searches.
I use elastic search heavily at my work place, and It did cross our mind (at least for extract keywords part). But then Elasticsearch is complicated to setup, load and play around with (because of special character's it becomes much more complicated. FlashText is much more easy to do and portable. It has become much more integrated it is in our projects now :)
All that is possible because it's fast and simple.
Tries tend to do that, be fast :DGood one :D