
Red Hat’s leadership in the container orchestration space with OpenShift mirrors Couchbase’s leadership in the containerized database space with its Autonomous Operator. This fact is the foundation of the partnership between Red Hat and Couchbase. I’ve personally worked on the partnership over the last two years. I wanted to take this opportunity to discuss why now is a great time to run Couchbase on Red Hat OpenShift.
The Current “State” of Kubernetes
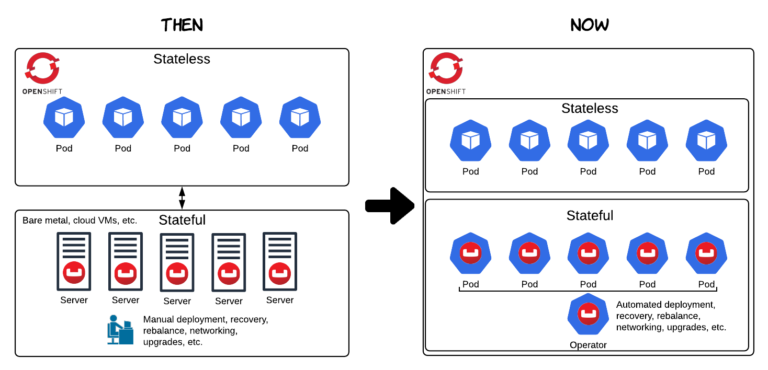
Prior to joining Couchbase I worked at a SaaS monitoring company. Working at a monitoring company gives you unique insight into which technologies your customers are using. By 2017 you could see Kubernetes’ and OpenShift’s tipping point in our customers’ monitoring dashboards. It was clear that Red Hat OpenShift was winning the container orchestration wars among large enterprises. But there was one thing you definitely did not see: databases on Kubernetes. Especially in production. In fact, running any “stateful” workloads on Kubernetes was considered risky. The typical architecture involved running your stateless workloads on Kubernetes or OpenShift and running your databases elsewhere.
As any database engineer will tell you, managing state in a distributed application is hard. When you throw multiple layers of abstraction and elastic scaling into the mix, it gets even harder. Kubernetes is and was great at managing compute and memory resources, but storage was not something managed by Kubernetes directly. In other words, Kubernetes and OpenShift were great for managing stateless workloads, but only a few brave souls dared to run stateful, persistent applications directly on Kubernetes (i.e. databases). The typical pattern was to host your database elsewhere (see “Then” in the diagram below).
Storage – Persistent Volumes
The community wanted to tackle this problem and Persistent Volumes was a major building block. Persistent Volumes (PVs) provided a solution to storage management and isolation in the form of an API that supports connecting different storage classes to running pods. PVs have a life-cycle independent from any individual pod, therefore allowing them to persist their data even after a pod is destroyed. This means you don’t have to worry about losing data in a disaster scenario when you lose a database or OpenShift node.
Multiple storage vendors have added support for Kubernetes via the Persistent Volumes API including the cloud providers and fellow Red Hat partner, Portworx. This means you have options when choosing your storage. This is critical from a Database vendor’s point of view, where choosing the right storage can have a big impact on performance and reliability.
The Operator Framework
The second major innovation and the one which has enabled Couchbase to become the leader for NoSQL databases on OpenShift, is the Operator Framework. Couchbase was the first NoSQL database company to make a serious investment in developing an Operator (see “Top Kubernetes Operators advancing across the Operator Capability Model“). We collaborated with the CoreOS team early on during the development of the Operator Framework. Today, Couchbase customers can rely on the Couchbase Autonomous Operator to manage many of their cluster operations for them including deployment, scaling, disaster recovery, rolling upgrades, and more. This represents a tremendous value to Couchbase customers and is also helping drive OpenShift adoption.
So what is an Operator? This quote from the Red Hat CoreOS team summarizes it best:
“Conceptually, an Operator takes human operational knowledge and encodes it into software that is more easily packaged and shared with consumers. Think of an Operator as an extension of the software vendor’s engineering team that watches over your Kubernetes environment and uses its current state to make decisions in milliseconds. Operators follow a maturity model that ranges from basic functionality to having specific logic for an application. Advanced Operators are designed to handle upgrades seamlessly, react to failures automatically, and not take shortcuts, like skipping a software backup process to save time.”
https://coreos.com/blog/introducing-operator-framework
Given that managing distributed state is challenging, and different systems manage state differently based on very specific implementation details, it was never reasonable to expect the Kubernetes community to code for every possible scenario that any and every stateful application could encounter. The Operator Framework enables developers to bridge that gap, and do so in a way that fits the Kubernetes paradigm. For example: In a disaster scenario, when an OpenShift node running a Couchbase pod goes down, the Couchbase Autonomous Operator will automatically and gracefully restore the cluster and re-balance your data without any interruption to services using Couchbase. And if you’re using Persistent Volumes, it will even reattach the volume from your lost pod to your new Couchbase pod – greatly speeding up the time it takes to rebalance your data.
Operator Lifecycle Manager
As Operators have matured so has the tooling around them. The best example is the Operator Lifecycle Manager (OLM). OLM was in tech preview as of OpenShift 3.11. As of OpenShift 4 it is an officially supported feature. Typically, installing an Operator requires cluster admin privileges and a few manual steps such as installing a Custom Resource Definition. OLM automates the installation task and can also mange updates for you without requiring cluster admin privileges. OLM hooks directly into the OperatorHub catalog, meaning as new Operator updates are pushed out, they will appear in the OperatorHub catalog and become installable through OLM. This allows users to find the Operator they need and install it in just a couple of clicks.
One of the main benefits of this is developer productivity. It gives Developers “Operators as a Service” within their OpenShift development environments.
Why Couchbase?
In recent years, the term “Cloud Native” has become part of the common parlance in tech. It comes up particularly often in the context of Kubernetes and OpenShift discussions. Kubernetes is often positioned as the platform for Cloud Native applications. Cloud Native means software that is designed to take advantage of the cloud computing model. In practice, this means applications that fit more of a microservices and service oriented architecture pattern (as opposed to a monolithic architecture), aim to scale horizontally (as opposed to scaling vertically) and can be run in relatively light-weight containers. This poses a problem for traditional, relational (and some NoSQL) databases which very much follow monolithic patterns and weren’t designed to scale out horizontally in the way that Couchbase was.
This is where Couchbase shines relative to other options. Early on in Couchbase’s life, it was pushed and challenged to support web scale workloads in cloud environments by its biggest users. Couchbase adopted an architecture from the beginning that resembles what we now call Cloud Native. In Couchbase, this is reflected in our Multi-dimensional scaling capability. Multi-dimensional Scaling allows each of Couchbase’s services (data, index, query, analytics, full text search, and eventing) to be scaled independently, while online and serving traffic. This is exactly how you would want to design an application with cloud native in mind.
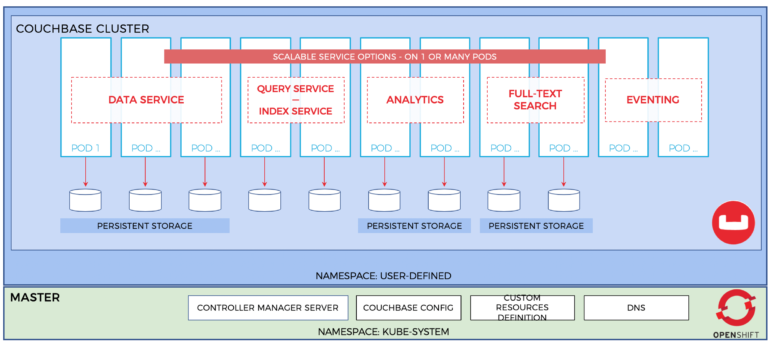
In addition to Multi-dimensional scaling, other Couchbase features such as auto-sharding and a robust, built-in administrative interface only help to smooth the experience of managing your NoSQL workloads on OpenShift.
Where We Go From Here
Couchbase Autonomous Operator 2.0 Beta
We aim to automate all Couchbase operational best practices necessary to run clusters with our Operator. The ultimate goal being that our customers and Red Hat’s customers can efficiently operate their own Couchbase DBaaS running in any OpenShift environment in the cloud, on prem, or both. Even Couchbase’s own DBaaS offering relies heavily on the Couchbase Autonomous Operator.
We recently launched the Couchbase Autonomous Operator 2.0 Beta. While we continue to add new features to the Operator itself, we recognize that Couchbase is just one piece of the infrastructure. In practice, there are other functions such as metrics and logs monitoring and security which span multiple pieces of the infrastructure. Operator 2.0 includes built-in integration with the Couchbase Prometheus Exporter for collecting and exposing Couchbase Server metrics. This means you can monitor Couchbase along-side your other applications within your Ret Hat OpenShift environment.
Enabling Multi and Hybrid Cloud Workloads
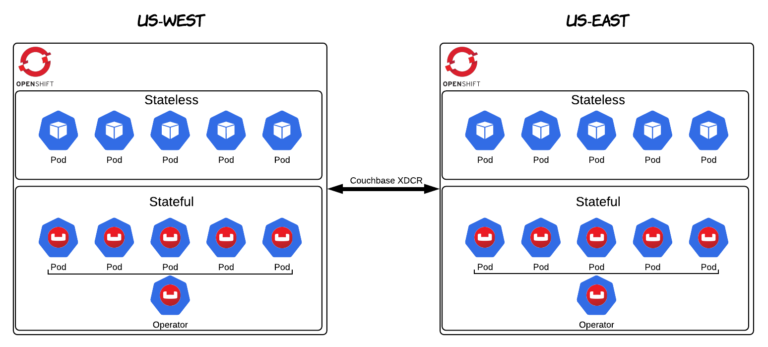
I would be remiss if I didn’t mention another key feature of Couchbase – Cross Data Center Replication (XDCR). XDCR has always been a popular feature of Couchbase. The reason it is important in this context is because of its role in enabling Multi and Hybrid Cloud stateful workloads on OpenShift. OpenShift already makes it easy to deploy applications on different clouds and on-prem. With XDCR you can also achieve data replication across OpenShift clusters. Over the next few weeks we (Red Had and Couchbase) plan on providing more content and updates on this topic specifically. Stay tuned!
Resources
- Red Hat OpenShift Blog:Top Kubernetes Operators advancing across the Operator Capability Model
- Couchbase Autonomous Operator 2.0 Beta Announcement
- Installing the Couchbase Autonomous Operator on Red Hat OpenShift
- Couchbase’s Red Hat Partner Page