From last November 4 to 8 I have been at PASS Summit in Seattle, attending excellent technical sessions and having the honour to deliver a lightning session, which is a small 10 minutes presentation.
Why should you read this?
Being one of the biggest data events in the world, PASS Summit usually exposes the present and future technologies that will drive the following year or more, pointing the direction for every data-related professional.
This summary, full of links and details about these technologies, can guide you during the exploration and learning of these new technologies.
Azure SQL Database Serverless
In the beginning, we had only Azure SQL Databases or custom VM’s, Platform as a Service (PaaS) or Infrastructure as a Service (IaaS) two extreme opposites in relation to price and features.
Want to know more? Take a look on this link: https://azure.microsoft.com/en-us/overview/what-is-paas/
The first change happened in pricing: The creation of Elastic Pools. By using an Elastic Pool, we could aggregate many databases in a single pool of resources, expecting that when one database is consuming too many resources, the others would not be consuming that much.
More about Elastic Pool: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-elastic-pool
However, Elastic Pool is better for pools with 5 or more databases, with fewer databases it becomes too expensive, doesn’t worth it.
Microsoft decided we were missing something and create the Azure SQL Server Managed Instances, a halfway between the existing solutions. Azure SQL Server Managed Instances is intended to be cheaper than a custom VM and have more features than an Azure SQL Database, allowing us to access features of an entire instance.
On my first experiences with Managed Instances, they were difficult to provision, taking hours to provision. During the PASS Summit, there was one demonstration provisioning Managed Instances in seconds using Azure ARC. I will go on details later on this blog.
Learn more about Azure SQL Server Managed Instances on this link: https://blogs.msdn.microsoft.com/sqlserverstorageengine/2018/03/07/what-is-azure-sql-database-managed-instance-2/
Now we have one more option: Azure SQL Database Serverless. It’s not a product, but a pricing tier of Azure SQL Databases, although it offers slightly different features.

The best way to understand this new pricing tier is comparing it with the database option “auto close”: When no connection is active on the database, the database shuts down and stop charging our azure account. When the following connection request arrives, the database will start again, making the connection slower than the rest, but only the connection, all further requests will be regular. It’s cheaper, of course, since we are only charged by the time the database is in use, this makes this tier cheaper than the usual Azure SQL Database, but the “auto-close” behaviour maybe not good for some environments.
Serverless databases have an additional configuration called Auto-Close Delay. You can define after how long time of inactivity the database should shut down. The minimum amount of time is 1 hour. This configuration can prevent disruptions during work hours. If we find the correct delay configuration the database may shut down only out of working hours.

In the future, a new feature to allow us to automate the start and shutdown may appear, providing us with better control and more savings.
More about Azure SQL Database Serverless: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-serverless
SQL Database Edge
IOT devices, especially in industries, send constant information to servers in order to the server monitor the device and discover if there is something wrong. More than just monitor after the device failure, the servers can run machine learning models over the data to identify potential future failures according to the device’s history.
The weakness of this architecture is the need of the devices to send the data to the server in order to be analysed and only then the server will be able to take an action, maybe changing some device configuration, or sending some alert.
SQL Database Edge is intended exactly to solve this weakness. It’s a SQL Server Edition which can be installed inside the IOT device. Instead of sending the data to the server, the IoT device can save the data in SQL Database Edge and execute the machine learning models using SQL Server, which has the SQL Server Machine Learning Service. In this way, the own device can identify possible future failures and take the possible actions to work around it or send an alert.
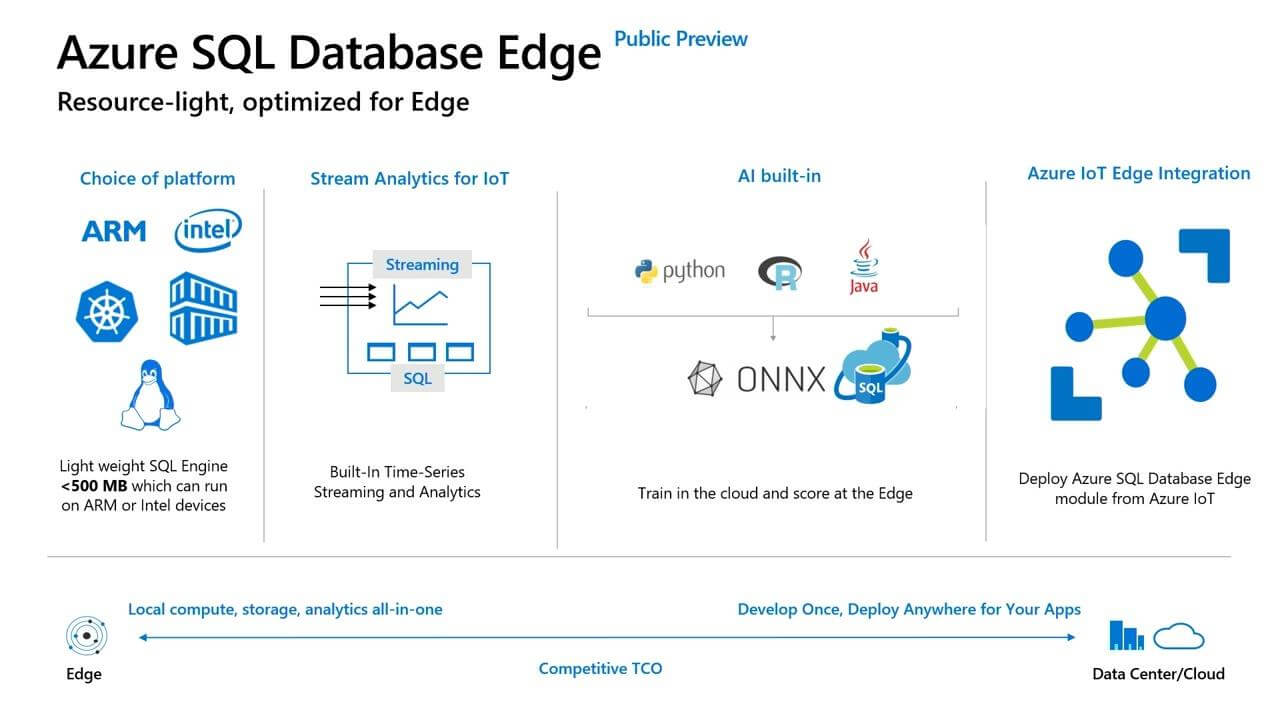
Empowering the device, we distribute the load from the server to hundreds or thousands of devices, allowing for faster and more reliable problem identification and workaround using machine learning models.
One more interesting detail is the ability to distribute Azure SQL Database Edge to the devices using IOT Hub.
You can read more about Azure SQL Database Edge here: https://azure.microsoft.com/en-us/services/sql-database-edge/
Learn more about SQL Server Machine Learning Service on this link: https://docs.microsoft.com/en-us/sql/advanced-analytics/what-is-sql-server-machine-learning?view=sql-server-ver15
More about IOT Hub on this link: https://azure.microsoft.com/en-us/services/iot-hub/
Accelerate Data Recovery
This is a new SQL Server 2019 feature which is being much highlighted, not only in PASS Summit.
Long-running operations are something very common to happen. However, sometimes, after 1 or 2 hours of a running operation, some junior DBA may decide it was too much and try to kill the process and rollback. Here the problem begins.
In order to stop the running transaction, all the activities need to be rolled back and this can take almost or even the same time the transaction has taken until the kill was requested. There is no solution, the DBA can only wait for the rollback.
The Accelerated Data Recovery (ADR) arrived with Hyperscale cloud database, announced in PASS Summit 2018. This year, ADR was included in SQL Server 2019. It allows for a fast recovery, without all the rollback waiting time that usually happens.
ADR uses row versioning techniques, but with a different internal structure than the one used by snapshot isolation level.
In order to know more about ADR, check these links:
https://www.linkedin.com/pulse/sql-server-2019-how-saved-world-from-long-recovery-bob-ward/
Azure ARC
Microsoft knows many companies use more than a single cloud provider. If Microsoft relies only on their cloud services, the war among cloud providers would be difficult, Microsoft can win some, lose others. So, why not a complete change in the battlefield?
Azure ARC allows the deployment and management of Microsoft cloud services to many different clouds: Azure, Google, AWS, all the deployment and management made from a single tool – Azure ARC. This completely changes the battlefield, even if one company has some reason to use a different cloud provider, they can still use Azure ARC to manage the entire environment and even deploy Microsoft services to other cloud providers.
Even more: Azure ARC also allows the deployment of Azure Services to on-premises services.
During the demonstration, Azure ARC was able to provision an Azure SQL Managed Instance in 30 seconds. It was incredible! Just a few weeks before I have talked about Azure SQL Managed Instance and the provisioning time was 3 hours or more. So, I asked at the Data Clinic, how was it possible? How could Azure ARC cause a so huge difference in the provision time?
The answer was very interesting: Because Azure ARC was provisioning the managed instance inside a container. In this case, would the container version of a SQL Managed Instance have any difference in relation to the regular version of a SQL Managed Instance? Yes, they will be slightly different, but the difference is not clearly documented yet.
In order to learn more about Azure Arc you can access this link: https://azure.microsoft.com/en-us/services/azure-arc/
![]()
Azure Synapse Analytics
It’s an oversimplification think that Azure Synapse Analytics is a new name for Azure SQL Datawarehouse. Azure Synapse Analytics contains Azure SQL Datawarehouse, but also contains many new features. It seems that it’s going to be a central point for all, or almost all, Azure Data Platform.
One very important new feature is the Azure Synapse Studio. This new tool creates a unified experience among many data platform services: Azure SQL Datawarehouse, Spark, Power BI and more being used from a single front-end tool.
Explaining in a better way: from the Azure Synapse Studio we have access to the Data Warehouse model in Azure SQL Datawarehouse (this name will die, now it’s Azure Synapse Analytics), manipulation of the data using Spark (I’m not sure if it’s linked with Databricks), machine learning models with Azure Machine Learning and visualization dashboards with Power BI, this one connected to the Power BI portal. You can see the changes made in the portal and anything you change from Synapse Analytics will affect the portal.
![]()
Can you make any kind of Power BI implementation inside Azure Synapse Studio, such as dataflows and so on? Not yet, but it’s just a beginning, it’s expected to evolve a lot.
In summary, Azure Synapse Analytics is much more than only Azure SQL Datawarehouse, it’s not a only a name change.
You can learn more about Azure Synapse Analytics on these links:
https://azure.microsoft.com/en-us/services/synapse-analytics/
Data Tools for Synapse Analytics
SQL Server Data Tools – SSDT – is around for many years, even more than Entity Framework Migrations, which is broadly used today.
I have used SQL Server Data Tools as part of the deployment process in many projects, it’s great to control the version of the database and make schema compares.
The most recent versions were a bit disappointing, the features for schema compare were reduced, I never discovered why. Due to that, the best recommendation was to go for 3rd part tools when needed.
It seems our relationship with SSDT is getting into a new chapter. SSDT has a new database project for Synapse Analytics, allowing us to create our data warehouse structure in SSDT and control the CICD process.
You can learn more about SSDT and Synapse Analytics on this link: https://cloudblogs.microsoft.com/sqlserver/2019/11/07/new-in-azure-synapse-analytics-cicd-for-sql-analytics-using-sql-server-data-tools/
Azure Data Share
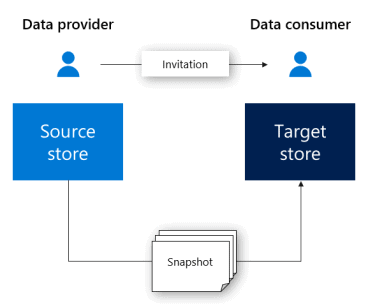
Data Share is a new azure service which allows a company to share data with other companies.
Is it better than creating services for the other company?
Well, using Data Share we are manipulating data, sharing parts of our data lake without need to develop something. In the same way, the other company will receive data in order to input in their own system. Is this a benefit? Maybe.
Another possible reason to use Data Share would be for governance: all shared pieces of data would be controlled in the same place, the data shares. However, it may only work well among companies using Azure, if the other company is using another cloud service, I believe data share may not work.
You can read more about Data share on this link: https://docs.microsoft.com/en-us/azure/data-share/
Big Data Cluster
Big Data Clusters are the most highlighted feature in SQL Server 2019. A big summary of what it is would be saying it’s a Microsoft implementation of a Hadoop and Data Lake solution.
Would you like to know more about Hadoop? Check this link: https://hadoop.apache.org/
Learn more about Data Lake on this link: https://en.wikipedia.org/wiki/Data_lake
Let’s simplify the explanation, step by step. Big Data Cluster is an implementation of a Cluster processing solution. This means this feature allows to create a set of servers, with a master node and slave nodes. The master node can receive jobs to process, break these jobs among the slave nodes and collect the results later, resulting the job being processed by many servers as a set, allowing SQL Server to process huge amounts of data.
In the past, this solution was built before using the name of Parallel Data Warehouse. PDW is a SQL Server appliance, but it can be easily understood as a different SQL Server edition. It’s a cluster for parallel processing, exactly as Big Data Cluster. What’s the difference?
You can learn more about Parallel Data Warehouse on this link: https://docs.microsoft.com/en-us/sql/analytics-platform-system/parallel-data-warehouse-overview?view=aps-pdw-2016-au7
The difference is in relation to the language and storage of the data. PDW is totally based on SQL architecture and language. On the other hand, we have for a long time an open architecture called Hadoop and some variations of it, such as Spark.
During the growth of Azure and the cloud environment, both solutions were created in the cloud. PDW was created as SQL Data Warehouse while Hadoop was created as HD Insight, which provides many flavours of Hadoop, such as Spark and more. It became a kind of a race to see which technology would conquer the heart of the market, parallel processing clusters based in SQL or based in Hadoop.
Learn more about HD Insight on this link: https://azure.microsoft.com/en-us/services/hdinsight/
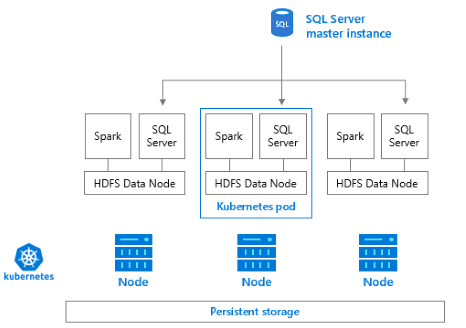
Big Data Cluster is a Hadoop-like solution which can be used in the on-premises environment. However, it’s way more than a simple Hadoop-like solution. Big Data clusters use HDFS Tiering to create Data Virtualization and allow us the creation of a Data Lake, an environment where the data doesn’t need to be moved from its source location in order to be processed.
HDFS tiering was also introduced to us during a sponsored breakfast organized by DELL. It’s a feature linked to Big Data Cluster in SQL Server 2019 which allow us to mount external storages into a single HDFS storage. This leads us to the Data Lake concept: instead of moving the data among storages and technologies, leave the data in its place and process the data where it already is.
You can read more about HDFS tiering here: https://docs.microsoft.com/en-us/sql/big-data-cluster/hdfs-tiering?view=sql-server-ver15
Learn more about Data Virtualization on this link: https://blogs.technet.microsoft.com/machinelearning/2017/06/21/data-virtualization-unlocking-data-for-ai-and-machine-learning/
Another huge difference is the use of Polybase. In order to reach the data sources, Big Data Cluster uses Polybase. However, that’s not the old Polybase we discovered in SQL Server 2016. That’s a new Polybase with support to many different data sources, such as Oracle and much more. Polybase uses its pushdown technology to delegate the processing of SQL predicates to the remote machine responsible for the data.
I still have a lot to understand and write about the evolution of Polybase, because the old Polybase in SQL Server 2016 required a server configuration to set the technology to which the connection would be made, so one SQL Server instance would be tied with a single technology source for Polybase. Besides that, the pushdown technology was very difficult to configure with Hadoop. I believe all these have changed, resulting in the Big Data Clusters, an on-premise (or IaaS) solution for the creation of a Data Lake.
Learn more about Polybase on this link: https://docs.microsoft.com/en-us/sql/relational-databases/polybase/polybase-guide?view=sql-server-ver15
You can read more about Big Data Clusters on this link: https://docs.microsoft.com/en-us/sql/big-data-cluster/big-data-cluster-overview?view=sql-server-ver15
Azure Databricks
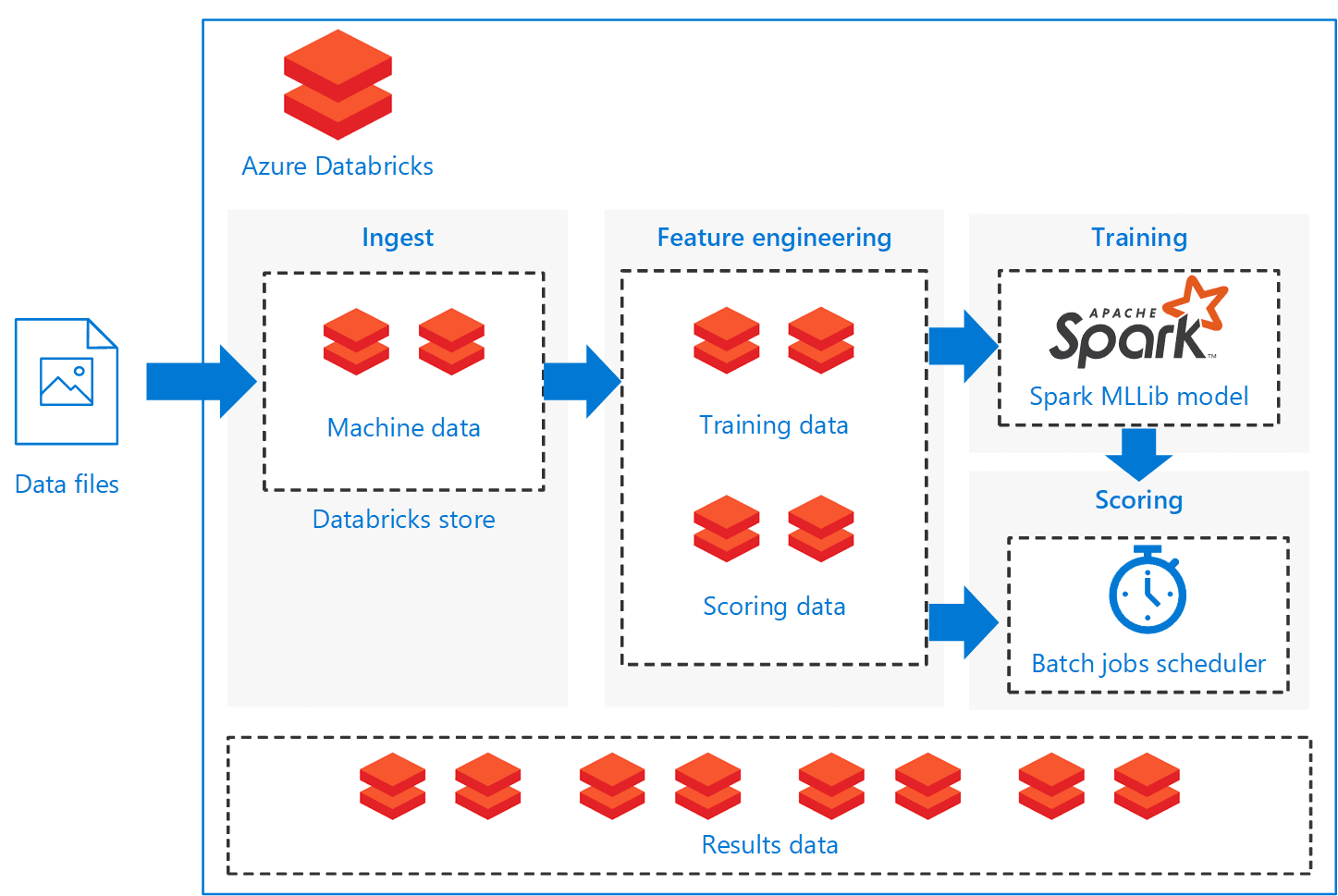
Databricks is Spark with a new name. This was everything I knew about Databricks before the PASS Summit and this leaves a lot of questions.
Since we already had Spark working as one of the flavours of HDInsight, why we need Databricks?
I got two answers for that:
A) Databricks is a more complete spark, since it loads a more complete set of modules by default than the Spark we can provision with HDInsight.
B) Databricks doesn’t have the provision problem. Spark in HDInsight needs to be provisioned, used and deleted because the cost to have the Spark servers provisioned is huge. Databricks, on the other hand, doesn’t have this problem, it charges you for the time you use it.
You can learn about this provisioning challenge on this link: https://docs.microsoft.com/en-us/azure/data-factory/v1/data-factory-compute-linked-services#azure-hdinsight-on-demand-linked-service
I loved the second explanation, and this leads us to the next question. However, I would find later this was an incomplete answer. The correct answer, but incomplete.
Since Databricks doesn’t have the provisioning problem anymore, it’s competing with Azure Data Lake, isn’t it? Aren’t both doing the same thing?
The unofficial answer I received was: Yes, they are. However, Azure Data Lake its language, U- SQL, are dead, you shouldn’t build anything new with them
First, it’s important for you to mind that in this context I’m not talking about Data Lake Storage, which is alive and kicking. I’m talking about Azure Data Lake and its language, U-SQL, which were a cluster processing solution on-demand, without the provisioning challenges. At some point, Azure Data Lake started to be called Azure Data Lake Analytics.
You can read more about Azure Data Lake Analytics here: https://azure.microsoft.com/en-us/services/data-lake-analytics/
Learn more about U-SQL language on this link: https://docs.microsoft.com/en-us/u-sql/
Another thing you should mind is that this is an unofficial answer. If you will consider this or not, it’s your choice, according how usually unofficial answers from people close to Microsoft are proven to be true sometime later.
These are not the only advantages of Databricks. The demonstrations during the sessions highlighted how Databricks keeps a record of machine learning training models in such a way we can identify a history of improvement according we work in our ML models.
It’s not clear how much would this be linked to Azure Machine Learning, but it doesn’t seem to be a kind of link such as Synapse Analytics has with Power BI.
Databricks also has an improved storage which received its own name: Delta Lake.
You can read more about Databricks on this link: https://azure.microsoft.com/en-us/services/databricks/
Learn more about Delta Lake on this link: https://docs.microsoft.com/en-us/azure/databricks/delta/delta-intro
Get more information about Azure Machine Learning: https://docs.microsoft.com/en-us/azure/machine-learning/overview-what-is-azure-ml
Power BI
One of the main highlights for Power BI was the Data Protection and Governance new features. This show how Microsoft is engaged in turning Power BI into an enterprise product.
In summary, Power BI will have a link with Sensitive Labels already used in Microsoft Office in order to classify information. Users will be able to classify the information as confidential and other levels and this new feature comes with additional features for monitoring, permissions, governance and so on.
You can learn more about Sensitive Labels on this link: https://docs.microsoft.com/en-us/microsoft-365/compliance/sensitivity-labels
Well, I’m not so sure if this will become something usual, Sensitive Labels require an additional level of management and planning in the organization, I don’t see many clients using this feature.
You can read more about these features here: https://powerbi.microsoft.com/en-us/blog/announcing-new-data-protection-capabilities-in-power-bi/
In some ways linked to this, but way more important is the Data Lineage feature, an important feature for data warehouse environments.
In the past, Microsoft tried to include this feature inside ETL tools, it was when SSIS was still called DTS (ops, this may reveal my age!). It didn’t get the attention it deserves, in my opinion not because the feature was bad, but because usually data lineage, although very important, is way down in the list of concerns when building a data warehouse and many people working on this don’t even know exactly what data lineage is and why it’s important.
As the name stands for, the Data Lineage feature keeps track of the source data used to produce a report or dashboard. This feature can save your job when, after building a very expensive data warehouse, two dashboards built by different users show opposite information about the company business. Using the Data Lineage, you can track the information used by the users and identify why the dashboards are different, understanding each dashboard point of view.
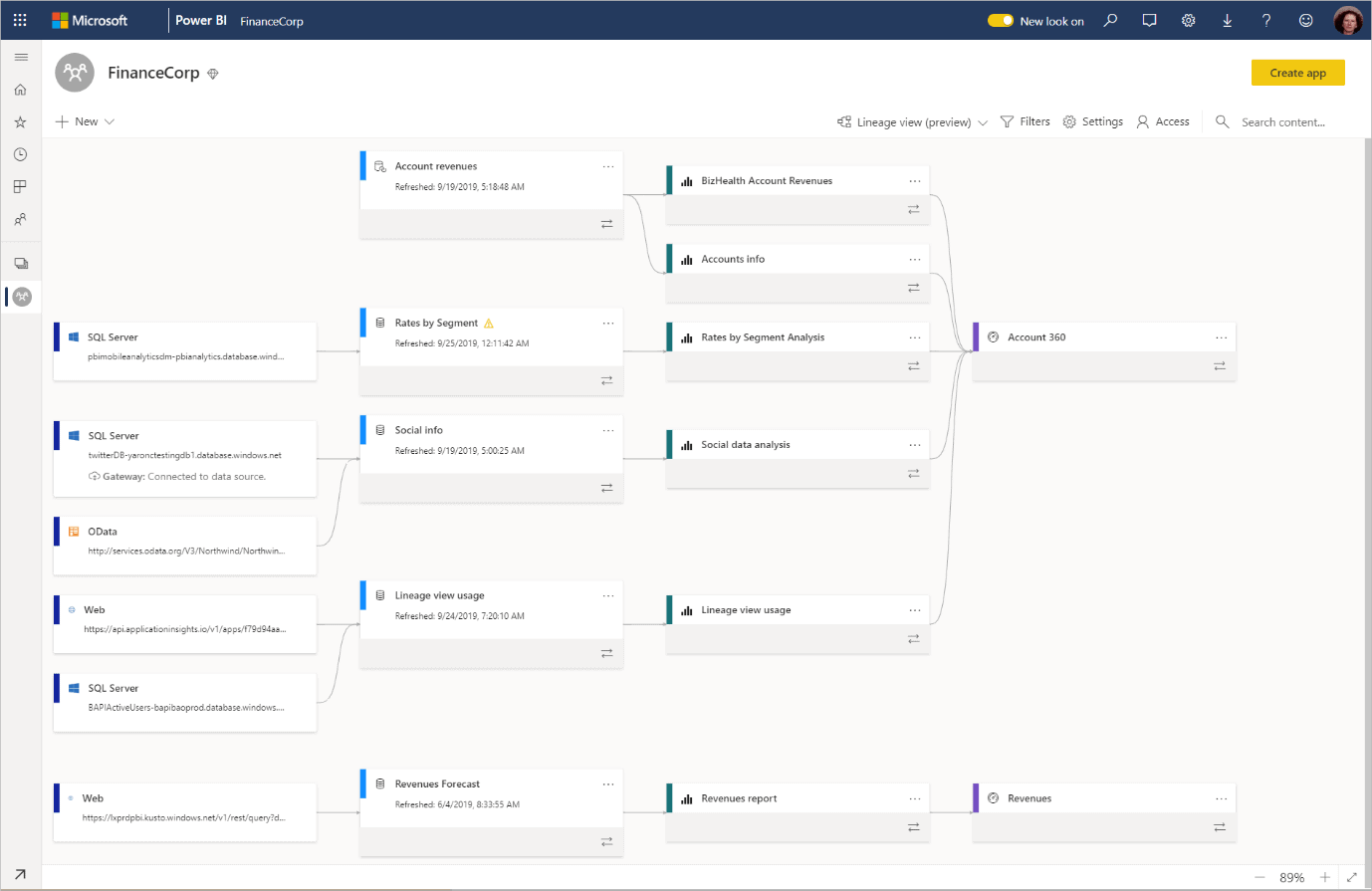
So, will this feature work this time? I hope so.
More about Power BI Data Lineage: https://docs.microsoft.com/en-us/power-bi/service-data-lineage
Now, let’s talk about the most surprising news about Power BI: the fact Microsoft is moving Power BI towards a position to replace Azure Analysis Service. Yes, replace Azure Analysis Services.
In order to better understand this, let’s go back in time. SQL Server Analysis Services (SSAS) is an on-premises server built to create Semantic Models as Data Marts.
Data Mart is a focused piece of the Data Warehouse which can be distributed through the company. That’s why Data Marts are usually built as Semantic Models, a model which can be easily understood by business people, less complex than the entire Data Warehouse
On this link, you will find more information about this move: https://powerbi.microsoft.com/en-us/blog/power-bi-premium-and-azure-analysis-services/
Before mentioning the most surprising news about Power BI, let’s analyse the current relationship between SSAS and Power BI.
SSAS is a tool which allows us to create a semantic model for our Data Warehouse. According to the data warehouse architecture, this is a Data Mart, a focused piece of the entire DW. The SSAS data mart is not only focused, but it’s a semantic model, meaning it’s built to be self-explaining to businesspeople. One of the best client tools for SSAS is Excel, once connected to SSAS, the data mart is exposed as a cube, allowing the business user to create pivot table reports using the measures they need at the moment, in a tool they are already used to.
SSAS supports two types of models: Multi-dimensional and Tabular. They have many differences between them, but these differences are disappearing with the evolution of the tool, although we can’t say yet they have the same features.
In order to better understand the difference between the two models, you can follow the two articles in which I illustrate how to build the same data mart with each of the models, highlighting the differences.
Multi-dimensional model: https://www.red-gate.com/simple-talk/sql/bi/creating-a-date-dimension-in-an-analysis-services-ssas-cube/
Tabular model: https://www.red-gate.com/simple-talk/sql/bi/creating-a-date-dimension-in-a-tabular-model/
You can learn more about SSAS semantic model on this link: https://blogs.msdn.microsoft.com/microsoft_press/2017/10/23/designing-a-multidimensional-bi-semantic-model/
Azure Analysis Services only implements the tabular model, not the multi-dimensional model. This creates questions about the future of the multi-dimensional model, although the differences/limitations of the tabular in relation to the multi-dimensional. For example, I’m not a fan of the tabular limitation to have only one active relationship between two tables. What do you think about? Let’s talk more in the comments.
Power BI, on the other hand, was created to be a Visualization and Self-Service BI tool. The idea is to allow the business users to access the corporate Data Warehouse/Data Mart and merge it with any additional information the business needs, even information collected from the web. In this way, the user doesn’t need to make special requests to the corporate IT department, avoiding delays and overwhelming the IT department. As part of the Self-Service BI concept, Power BI also offers Self-Service ETL using Power Query and, more recently, Power BI Dataflows, allowing even a business user to create ETL code to retrieve the needed information.
Power BI was born from Excel plug-ins. Each part of Power BI was a different Excel plug-in, such as Power Query and Power Pivot. Power Pivot, on the other hand, was created from the same tabular engine than SSAS, just with some additional size limitations to fit into Excel.
Therefore, Power BI, SSAS and Azure Analysis Services share the same core engine for the tabular model and Microsoft is working to eliminate the differences. It makes sense the idea of replacing Azure Analysis Services with Power BI, leaving only two questions without a clear answer:
- The complete set of tabular model features is only available in Power BI Premium, which is expensive. Power BI Pro has limitations which prevent the development of a complete tabular semantic model. Analysis Services, on the other hand, has SSAS as an on-premises option, allowing the company to start the development on the correct way and scale up for bigger and cloud editions in the future. How to solve this dilemma?
- Will the tabular model, an in-memory solution, really replace the multi-dimensional model, which could store pre-calculations of many combinations of the dimensions?
On this link, you will find more information about the replacement move between power bi premium and Azure Analysis Services: https://powerbi.microsoft.com/en-us/blog/power-bi-premium-and-azure-analysis-services/
Conclusion
2020 is starting full of new and exciting technologies for Data Platform in the cloud, it’s time to recycle our knowledge.
Load comments