blog
How to Configure Cluster-to-Cluster Replication for PostgreSQL

As we recently announced, ClusterControl 1.7.4 has a new feature called Cluster-to-Cluster Replication. It allows you to have a replication running between two autonomous clusters. For more detailed information please refer to the above mentioned announcement.
We will take a look at how to use this new feature for an existing PostgreSQL cluster. For this task, we will assume you have ClusterControl installed and the Master Cluster was deployed using it.
Requirements for the Master Cluster
There are some requirements for the Master Cluster to make it work:
- PostgreSQL 9.6 or later.
- There must be a PostgreSQL server with the ClusterControl role ‘Master’.
- When setting up the Slave Cluster the Admin credentials must be identical to the Master Cluster.
Preparing the Master Cluster
The Master Cluster needs to meet the requirements above mentioned.
About the first requirement, make sure you are using the correct PostgreSQL version in the Master Cluster and chose the same for the Slave Cluster.
$ psql
postgres=# select version();
PostgreSQL 11.5 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bitIf you need to assign the master role to a specific node, you can do it from the ClusterControl UI. Go to ClusterControl -> Select Master Cluster -> Nodes -> Select the Node -> Node Actions -> Promote Slave.
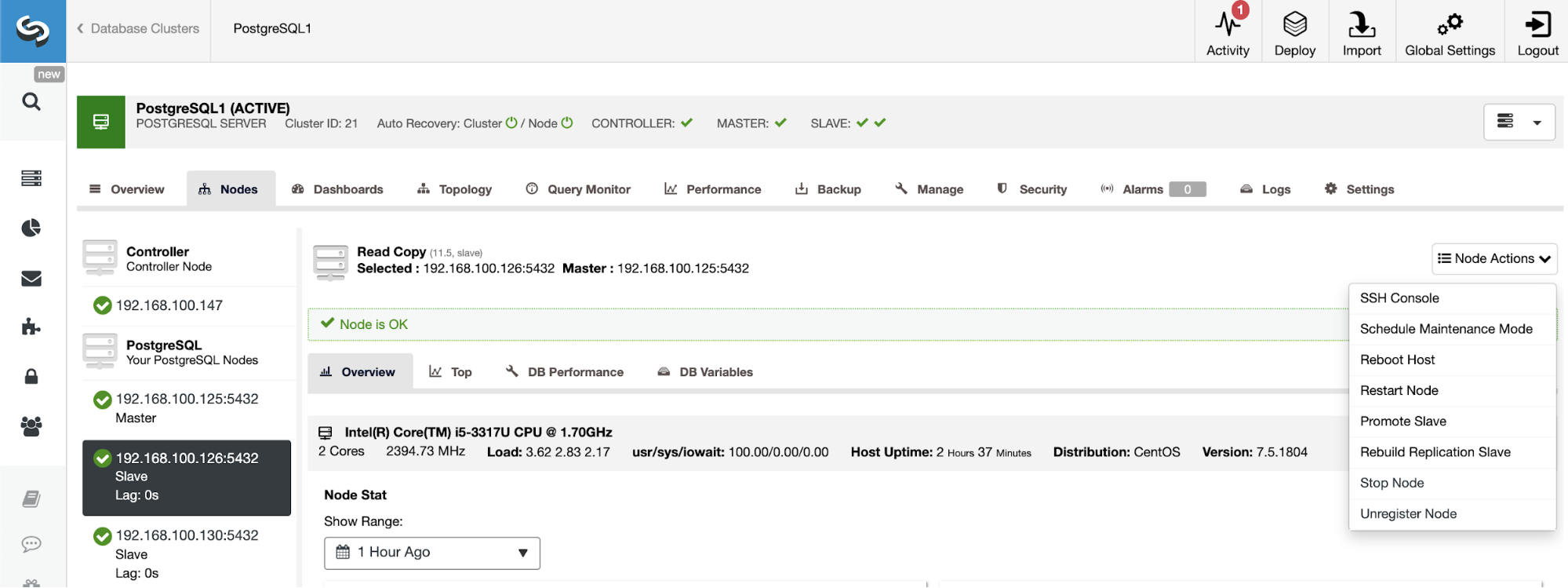
And finally, during the Slave Cluster creation, you must use the same admin credentials that you are using currently in the Master Cluster. You will see where to add it in the following section.
Creating the Slave Cluster from the ClusterControl UI
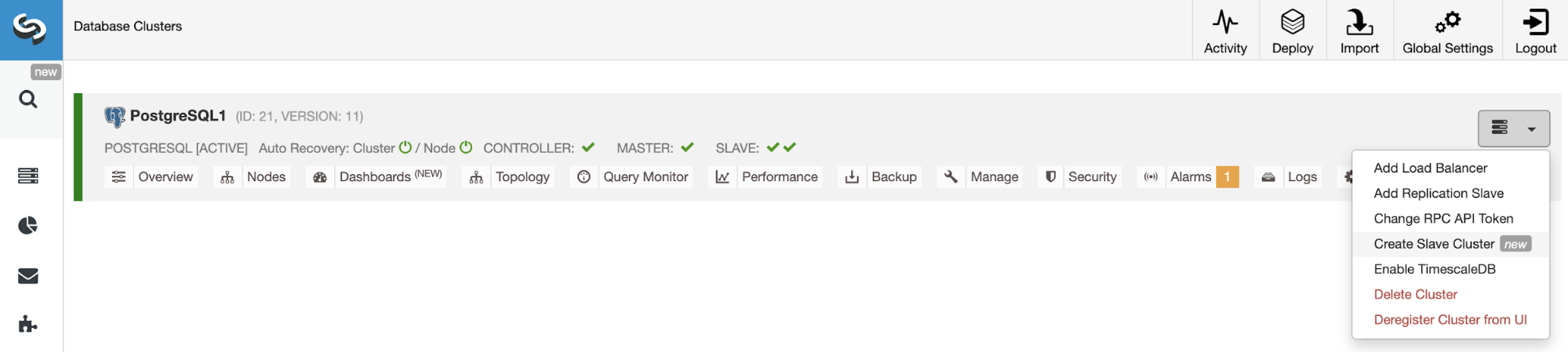
To create a new Slave Cluster, go to ClusterControl -> Select Cluster -> Cluster Actions -> Create Slave Cluster.
The Slave Cluster will be created by streaming data from the current Master Cluster.
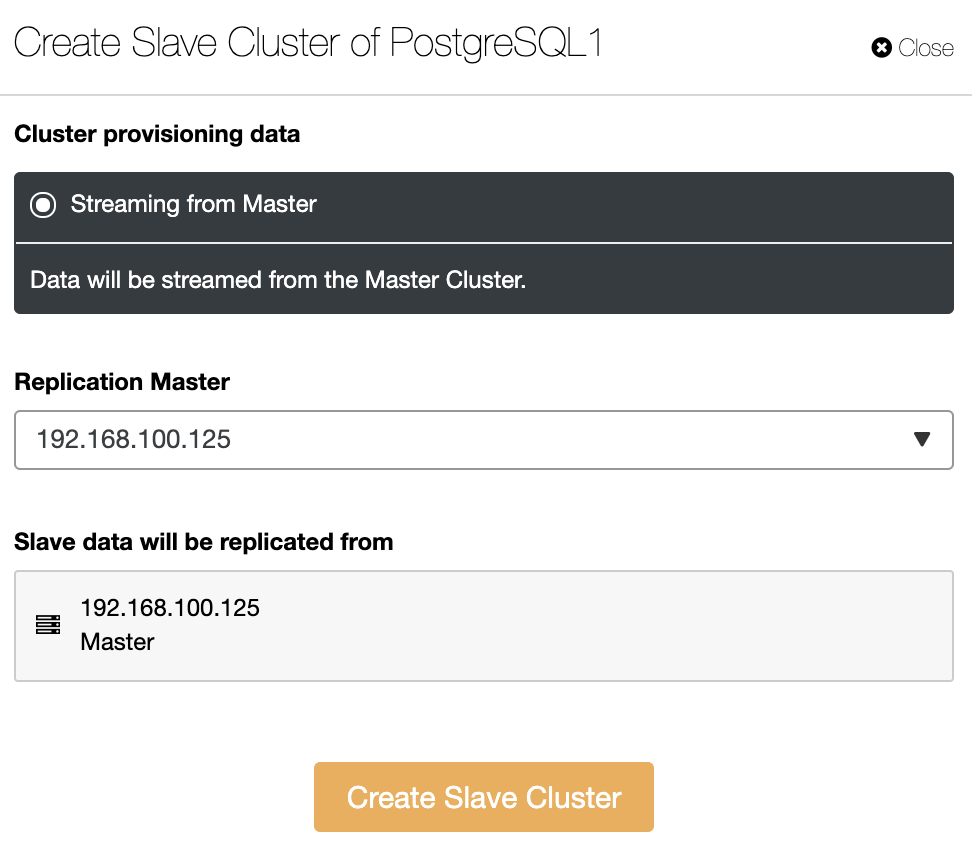
In this section, you must also choose the master node of the current cluster from which the data will be replicated.
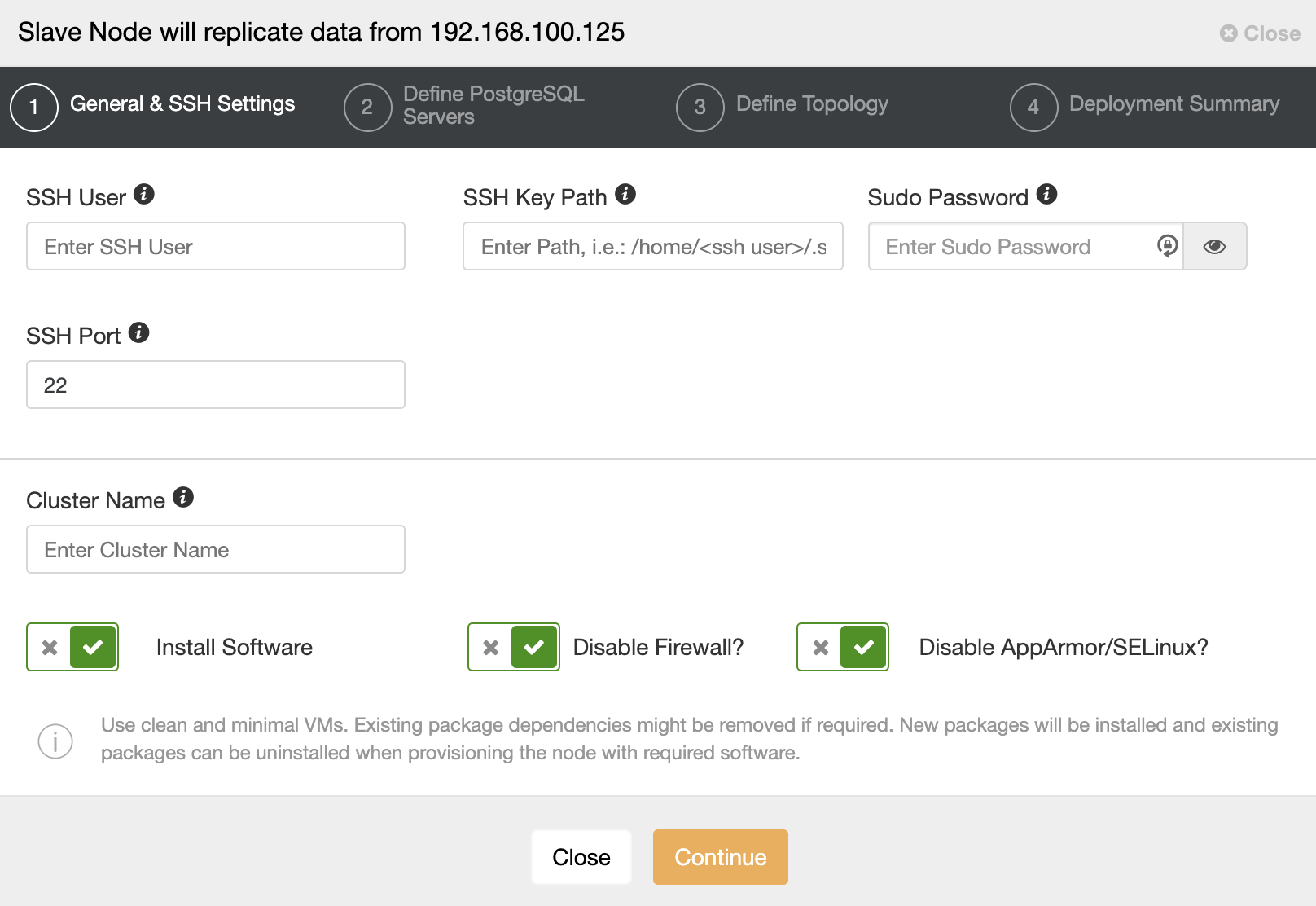
When you go to the next step, you must specify User, Key or Password and port to connect by SSH to your servers. You also need a name for your Slave Cluster and if you want ClusterControl to install the corresponding software and configurations for you.
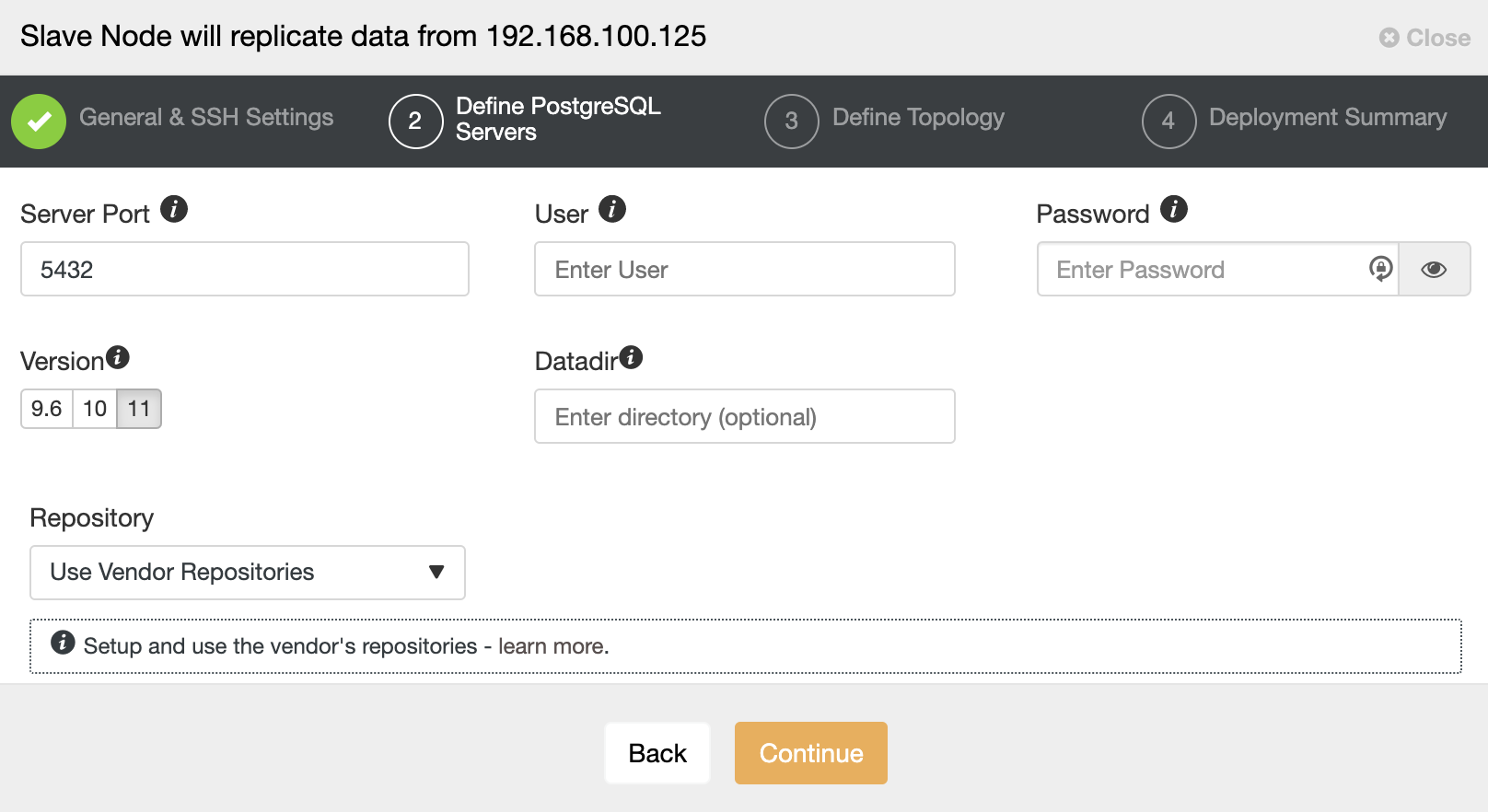
After setting up the SSH access information, you must define the database version, datadir, port, and admin credentials. As it will use streaming replication, make sure you use the same database version, and as we mentioned earlier, the credentials must be the same used by the Master Cluster. You can also specify which repository to use.
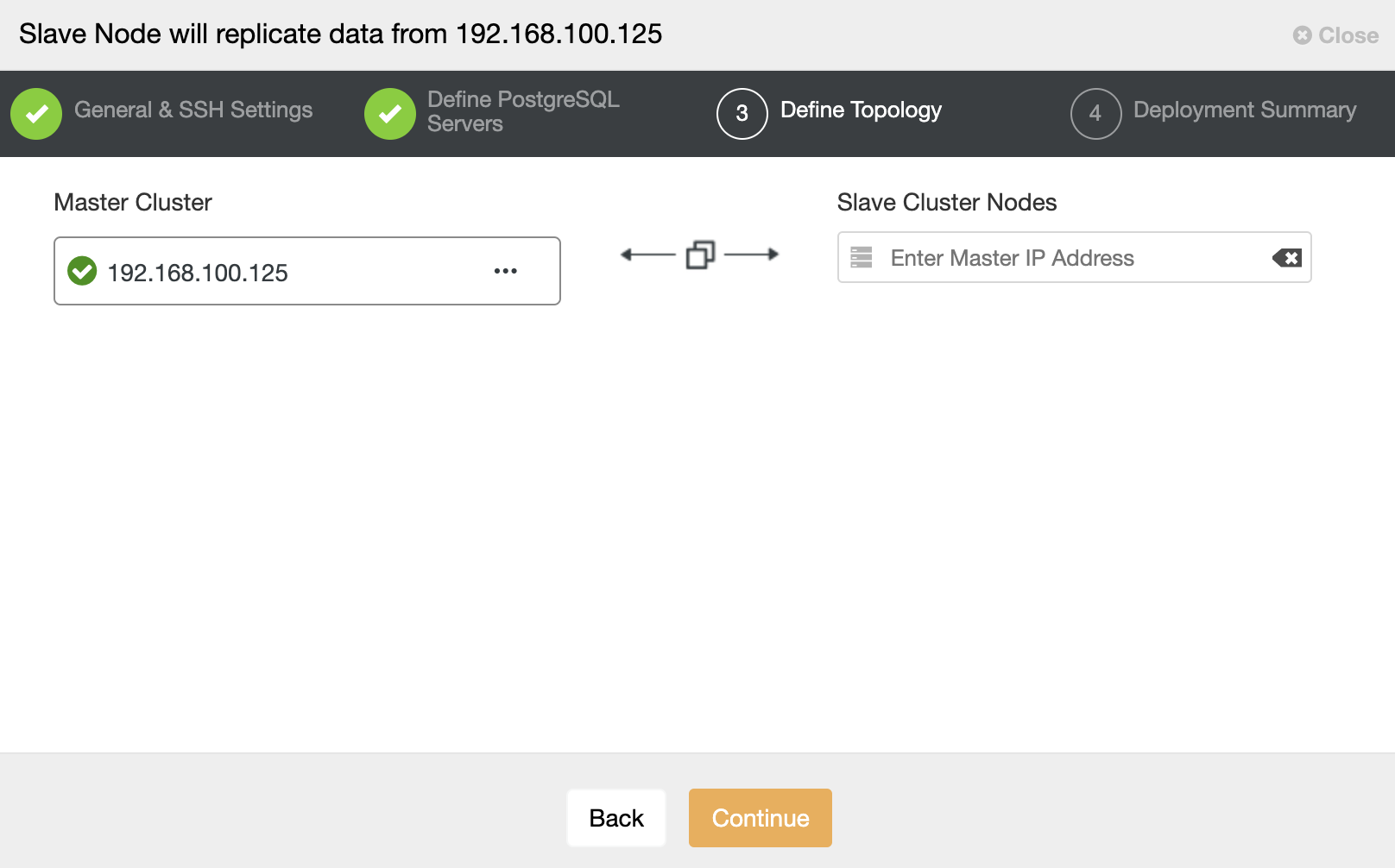
In this step, you need to add the server to the new Slave Cluster. For this task, you can enter both IP Address or Hostname of the database node.
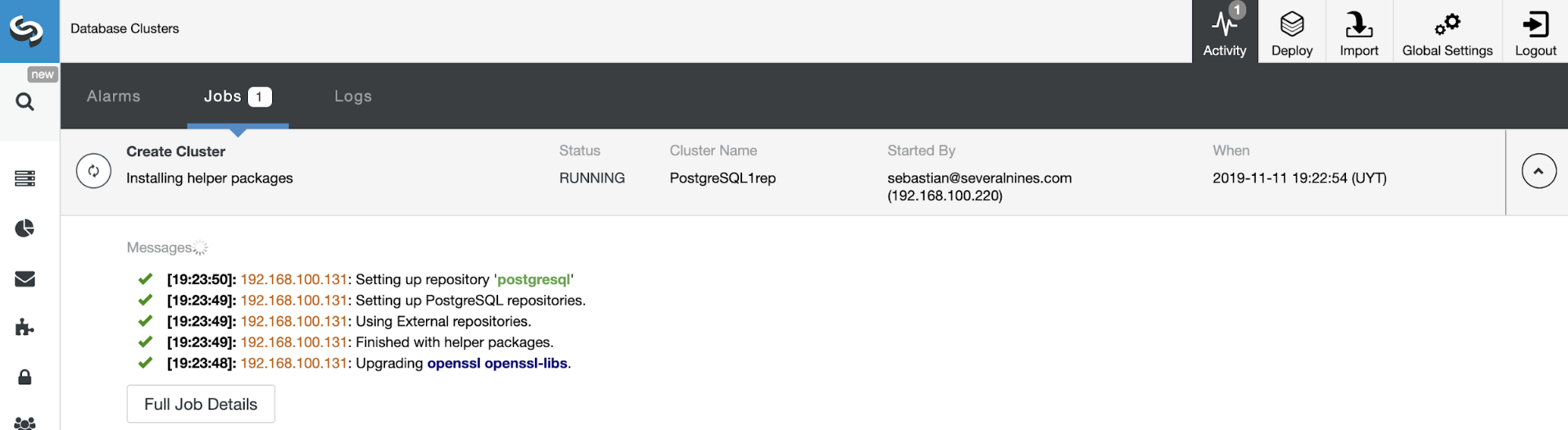
You can monitor the status of the creation of your new Slave Cluster from the ClusterControl activity monitor. Once the task is finished, you can see the cluster in the main ClusterControl screen.
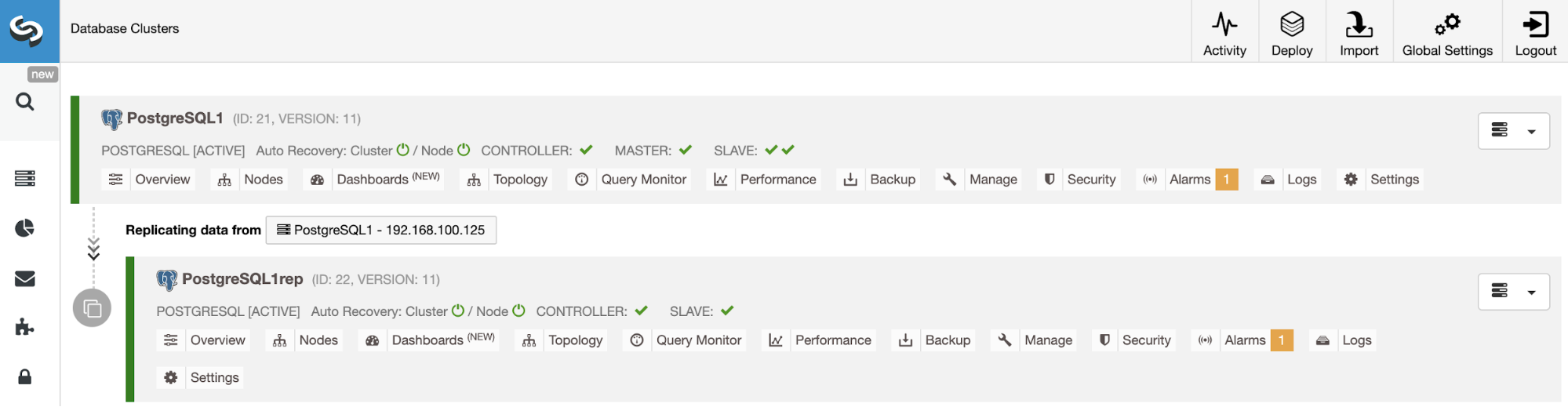
Managing Cluster-to-Cluster Replication Using the ClusterControl UI
Now you have your Cluster-to-Cluster Replication up and running, there are different actions to perform on this topology using ClusterControl.
Rebuilding a Slave Cluster
To rebuild a Slave Cluster, go to ClusterControl -> Select Slave Cluster -> Nodes -> Choose the Node connected to the Master Cluster -> Node Actions -> Rebuild Replication Slave.
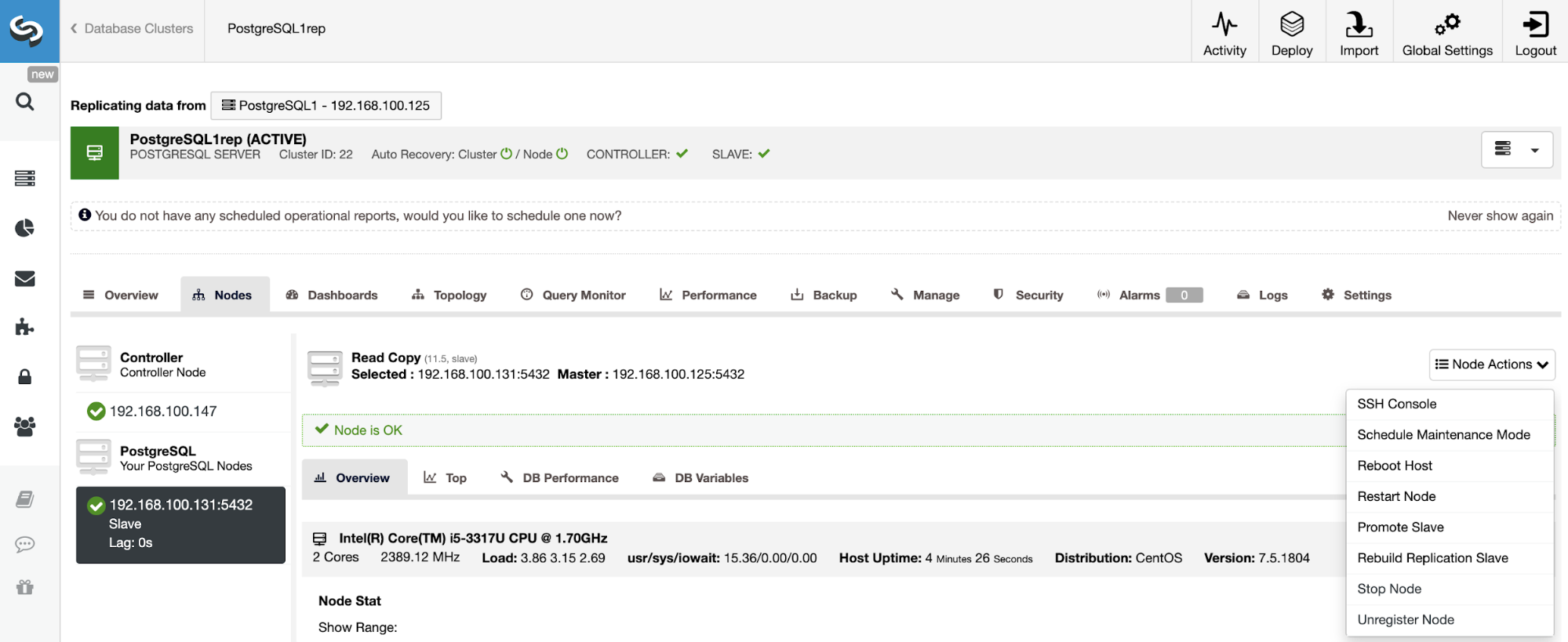
ClusterControl will perform the following steps:
- Stop PostgreSQL Server
- Remove content from its datadir
- Stream a backup from the Master to the Slave using pg_basebackup
- Start the Slave
Stop/Start Replication Slave
The stop and start replication in PostgreSQL means pause and resume it, but we use these terms to be consistent with other database technologies we support.
This function will be available to use from the ClusterControl UI soon. This action will use the pg_wal_replay_pause and pg_wal_replay_resume PostgreSQL functions to perform this task.
Meanwhile, you can use a workaround to stop and start the replication slave stopping and starting the database node in an easy way using ClusterControl.
Go to ClusterControl -> Select Slave Cluster -> Nodes -> Choose the Node -> Node Actions -> Stop Node/Start Node. This action will stop/start the database service directly.
Managing Cluster-to-Cluster Replication Using the ClusterControl CLI
In the previous section, you were able to see how to manage a Cluster-to-Cluster Replication using the ClusterControl UI. Now, let’s see how to do it by using the command line.
Note: As we mentioned at the beginning of this blog, we will assume you have ClusterControl installed and the Master Cluster was deployed using it.
Create the Slave Cluster
First, let’s see an example command to create a Slave Cluster by using the ClusterControl CLI:
$ s9s cluster --create --cluster-name=PostgreSQL1rep --cluster-type=postgresql --provider-version=11 --nodes="192.168.100.133" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=admin --db-admin-passwd=********* --vendor=postgres --remote-cluster-id=21 --logNow you have your create slave process running, let’s see each used parameter:
- Cluster: To list and manipulate clusters.
- Create: Create and install a new cluster.
- Cluster-name: The name of the new Slave Cluster.
- Cluster-type: The type of cluster to install.
- Provider-version: The software version.
- Nodes: List of the new nodes in the Slave Cluster.
- Os-user: The user name for the SSH commands.
- Os-key-file: The key file to use for SSH connection.
- Db-admin: The database admin user name.
- Db-admin-passwd: The password for the database admin.
- Remote-cluster-id: Master Cluster ID for the Cluster-to-Cluster Replication.
- Log: Wait and monitor job messages.
Using the –log flag, you will be able to see the logs in real time:
Verifying job parameters.
192.168.100.133: Checking ssh/sudo.
192.168.100.133: Checking if host already exists in another cluster.
Checking job arguments.
Found top level master node: 192.168.100.133
Verifying nodes.
Checking nodes that those aren't in another cluster.
Checking SSH connectivity and sudo.
192.168.100.133: Checking ssh/sudo.
Checking OS system tools.
Installing software.
Detected centos (core 7.5.1804).
Data directory was not specified. Using directory '/var/lib/pgsql/11/data'.
192.168.100.133:5432: Configuring host and installing packages if neccessary.
...
Cluster 26 is running.
Generated & set RPC authentication token.Rebuilding a Slave Cluster
You can rebuild a Slave Cluster using the following command:
$ s9s replication --stage --master="192.168.100.125" --slave="192.168.100.133" --cluster-id=26 --remote-cluster-id=21 --logThe parameters are:
- Replication: To monitor and control data replication.
- Stage: Stage/Rebuild a Replication Slave.
- Master: The replication master in the master cluster.
- Slave: The replication slave in the slave cluster.
- Cluster-id: The Slave Cluster ID.
- Remote-cluster-id: The Master Cluster ID.
- Log: Wait and monitor job messages.
The job log should be similar to this one:
Rebuild replication slave 192.168.100.133:5432 from master 192.168.100.125:5432.
Remote cluster id = 21
192.168.100.125: Checking size of '/var/lib/pgsql/11/data'.
192.168.100.125: /var/lib/pgsql/11/data size is 201.13 MiB.
192.168.100.133: Checking free space in '/var/lib/pgsql/11/data'.
192.168.100.133: /var/lib/pgsql/11/data has 28.78 GiB free space.
192.168.100.125:5432(master): Verifying PostgreSQL version.
192.168.100.125: Verifying the timescaledb-postgresql-11 installation.
192.168.100.125: Package timescaledb-postgresql-11 is not installed.
Setting up replication 192.168.100.125:5432->192.168.100.133:5432
Collecting server variables.
192.168.100.125:5432: Using the pg_hba.conf contents for the slave.
192.168.100.125:5432: Will copy the postmaster.opts to the slave.
192.168.100.133:5432: Updating slave configuration.
Writing file '192.168.100.133:/var/lib/pgsql/11/data/postgresql.conf'.
192.168.100.133:5432: GRANT new node on members to do pg_basebackup.
192.168.100.125:5432: granting 192.168.100.133:5432.
192.168.100.133:5432: Stopping slave.
192.168.100.133:5432: Stopping PostgreSQL node.
192.168.100.133: waiting for server to shut down.... done
server stopped
…
192.168.100.133: waiting for server to start....2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv4 address "0.0.0.0", port 5432
2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv6 address "::", port 5432
2019-11-12 15:51:11.769 UTC [8005] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2019-11-12 15:51:11.774 UTC [8005] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
2019-11-12 15:51:11.798 UTC [8005] LOG: redirecting log output to logging collector process
2019-11-12 15:51:11.798 UTC [8005] HINT: Future log output will appear in directory "log".
done
server started
192.168.100.133:5432: Grant cluster members on the new node (for failover).
Grant connect access for new host in cluster.
Adding grant on 192.168.100.125:5432.
192.168.100.133:5432: Waiting until the service is started.
Replication slave job finished.Stop/Start Replication Slave
As we mentioned in the UI section, the stop and start replication in PostgreSQL means pause and resume it, but we use these terms to keep the parallelism with other technologies.
You can stop to replicate the data from the Master Cluster in this way:
$ s9s replication --stop --slave="192.168.100.133" --cluster-id=26 --logYou will see this:
192.168.100.133:5432: Pausing recovery of the slave.
192.168.100.133:5432: Successfully paused recovery on the slave using select pg_wal_replay_pause().And now, you can start it again:
$ s9s replication --start --slave="192.168.100.133" --cluster-id=26 --logSo, you will see:
192.168.100.133:5432: Resuming recovery on the slave.
192.168.100.133:5432: Collecting replication statistics.
192.168.100.133:5432: Slave resumed recovery successfully using select pg_wal_replay_resume().Now, let’s check the used parameters.
- Replication: To monitor and control data replication.
- Stop/Start: To make the slave stop/start replicating.
- Slave: The replication slave node.
- Cluster-id: The ID of the cluster in which the slave node is.
- Log: Wait and monitor job messages.
Conclusion
This new ClusterControl feature will allow you to quickly set up replication between different PostgreSQL clusters, and manage the setup in an easy and friendly way. The Severalnines dev team is working on enhancing this feature, so any ideas or suggestions would be very welcome.