CTO called me early in morning: “Server is down”. He was talking about an old GoLang code which was a acting as a store-and-forward server with a MongoDB behind. The database was used to save a copy of all passed traffic from clients.
I wasn’t familiar with that code. It wasn’t a well formatted code, no comments and lots of files in bad named directories.
“Do we have backup?”, I asked. And the answer was positive. The Network & Virtualization team is hero. They create a backup from whole machine periodically, and it’s perfect.
So we asked for a mirror server to keep service online. They switched IP addresses of main server and the mirror server, and we were online! Bravo!
Now we have to find the problem. We don't have time. Mirror server will die soon. So simply sshed to the server (which is not currently under load) and asked for top process list and df disk status.
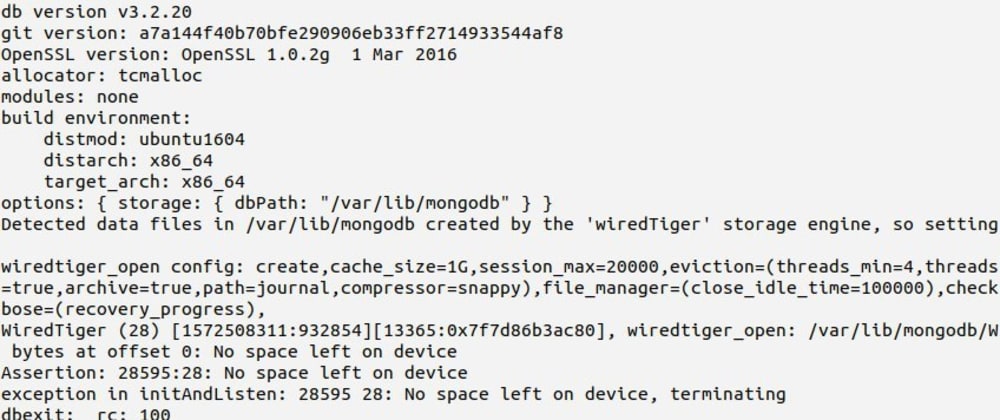
Disk was full!!! There wasn’t any free space. Even for a byte of data! I just asked the hero team (Network & Virtualization) to add some space to sda1. And they said that it’s not possible on their infrastructure. Maybe because that server’s startup time was for more than a year, software was old, no updates, nothing, totally an orphan server that no one cares about it’s existence.
At first we thought that we must read the source code. How this code is working? Which data is it storing? What’s going on?
But later we figured out that these are not good questions in this moment. We must ask, how can we kill this snake? The resource limitations? And which files we have to move?
sudo du -a / | sort -n -r | head -n 5 → We called this command on the second server that had free space. It will not run on a machine which is out of space.
So again we asked N&V team to add an external drive to the Ubuntu machine. A giant disk was added and it was time to move database files to new directory. We did so.
Time for some edits in services. sudo service mongod status. Failed to start with lots of errors in log file. But EXEC command was a big help. It was a --quite run of MongoDB. So I pasted it in terminal: mogod –config /etc/mongod.conf
Edited the dbpath to new directory. And it was another little problem. mongodb user wasn’t permitted to r/w on that directory. I don’t know why but chown mongodb:mongodb -R /media/blob/bob did not work for us so we changed the .service user to whoami output with a nice 755 permission to the mentioned username.
It’s time to clear the database log : > /var/log/mongodb/mongodb.log and remove the lock file which allows MongoDB to fire sudo rm /tmp/mongodb-27017.sock and sudo rm /var/lib/mongodb/mongodb.lock.
We are now refactoring the code, moving data to a safe place, and writing a new SOS protocol.
Lessons we learned:
Never accept a bad documented code.
Write a rescue plan that a five year old kid can read, understand, and perform it's actions step by step.
It's not important that how much big and complicated your business is, never forget old servers. Pay someone to take care of old infrastructure.
Never keep your technical support team busy with non-critical stuff.
Ask system administrators to make limitations on software and users, so they will shutdown before reaching operating system's red lines.
Use SSH-based monitoring tools to monitor details which are not accessible from ESXi monitoring panel.





Top comments (2)
Men your title had me 😂
😂 Ha ha 🌷 You are a smart man who didn't waste his time on Instagram.