
Adding A TTL To All Persistent Keys In Redis Using LaunchDarkly Feature Flags And Lucee CFML 5.2.9.40
The other week, I created a Redis key scanner using Jedis and Lucee CFML 5.2.8.50. I did this because I saw that one of our production Redis databases seemed to have a steady number of keys (about 14M); and, I wanted to see if they were all supposed to be there. By using the key scanner, I discovered a massive number of "persistent" keys - those without a TTL (Time to Live). So, I cleaned up much of the code that was producing these persistent keys. And then, I needed to write a script to safely iterate over the Redis key-space and assign a TTL to all persistent keys. I did this using LaunchDarkly feature flags and Lucee CFML 5.2.9.40.
ASIDE: I recently learned that you can get some statistics on keys using the
infooperation in Redis:
info keyspaceThis command will give you the total number of keys; and, the number of keys that are set to expire (ie, those that have a TTL - Time to Live). The difference between the two numbers represents the number of persistent keys that will live forever unless explicitly deleted.
If you try to search for solutions about adding a TTL to persistent keys in Redis, you will find examples of small Bash and PHP scripts that use the SCAN operator to easily traverse the Redis key-space, applying the TTL and EXPIRE operations as needed. And, that's great if you have a single Redis instance that you can access from your local computer; and, if you are not worried about putting undue pressure on an in-use production database instance.
However, the situation at InVision isn't quite so simple. We have many server clusters that represent a mixture of multi-tenant and single-tenant applications; I cannot actually access the vast majority of these clusters; and, I have no idea as to how these applications will perform if I start blasting them with SCAN, TTL, and EXPIRE operations.
This means that my solution for adding a TTL to all persistent keys has to be:
An algorithm that lives in the application code-base such that it isdeployed to each cluster and has access to every Redis instance.
An algorithm that logs StatsD metrics about how it is progressing such that I can monitor it across hundreds of different ColdFusion application instances.
An algorithm that can be turned on-and-off as needed, creating a safety-valve if the application performance should be negatively affected.
An algorithm that can be "ramped up" in aggressiveness such that the performance of the application can be monitored as the number of Redis operations slowly increases.
This is exactly the kind of problem that I live for! Let's face it - I'm a mediocre programmer from a technical stand-point. But, this problem doesn't call for fancy-pants OOP and Functional programming - this problem just requires grit and spit and elbow-grease. And, gosh darn it, that's what I've got!
To get this done, I patched directly into the health check end-point of the application. This is the end-point that Kubernetes (K8) pings every 10-seconds to see if an application pod is responsive (and ready to receive traffic). I am using this health check as my "task runner" and the ingress to my Redis SCAN algorithm.
Here's a snippet of the Controller method that executes the health check end-point:
<cfscript>
// --- TEMPORARY HACK. ------------------------------------------------------- //
// --- TEMPORARY HACK. ------------------------------------------------------- //
// This is here because we need a way to run an arbitrary script in all
// production environments. As such, I am hijacking the probe to act as a task
// runner (in as safe a manner as I possibly can).
// --
// NOTE: I don't technically need this try/catch since the task backfill service
// has one internally. But, I'm just being PARANOID and this will help me feel
// better about these shenanigans.
try {
redisTTLBackfillService.backfillAsync();
} catch ( any error ) {
debugLogger.error( error, "Error invoking Redis TTL backfill task." );
}
// --- TEMPORARY HACK. ------------------------------------------------------- //
// --- TEMPORARY HACK. ------------------------------------------------------- //
</cfscript>
As you can see, this Controller method is calling:
redisTTLBackfillService.backfillAsync()
It does this as part of every call to the health check end-point. Which means, that the method call has to be non-blocking, safe, and synchronized across all pods in the same application cluster. The "non-blocking" and "safe" aspects just mean that it can't negatively affect the operation of the health check itself (otherwise Kubernetes might kill the pod). And, the "synchronized" aspect is because the SCAN operation uses a cursor, which means only one instance can walk the Redis database key-space at a time (otherwise, the cursor will get messed-up).
How exciting is this?!
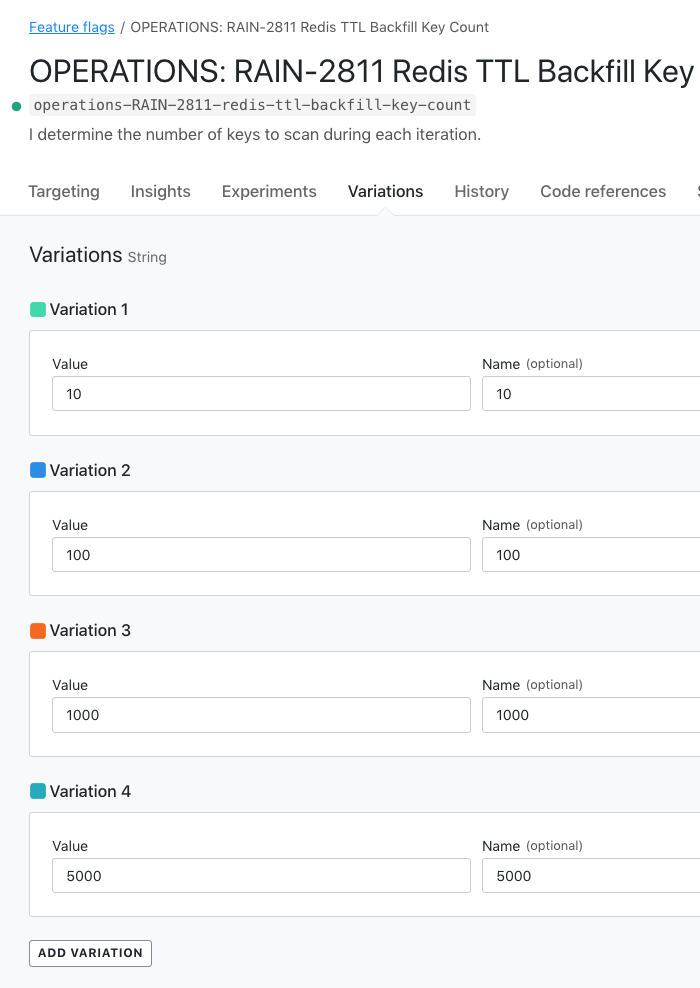
Internally to my RedisTTLBackfillService ColdFusion component, I am using a boolean LaunchDarkly feature flag to turn the algorithm on-and-off. However, even after the algorithm is enabled, I'm using another multi-variate LaunchDarkly feature flag to ramp-up the number of keys that are scanned during each SCAN operation. This way, I can watch the performance of the application and of the associated Redis instance as the algorithm iterates over the key-space.
The overall algorithm isn't terribly complicated; but, it does have a number of different responsibilities. To keep the code easier to write and to reason about, I've tried to isolate each responsibility within its own ColdFusion component method:
.backfillAsync()- This is the only public method and acts as the ingress into algorithm. It is responsible for safely spawning an asynchronousCFThreadthat runs the algorithm without blocking the health check end-point..backfillSyncSafe()- Called from within the aforementionedCFThread, this methods uses a distributed lock to safely synchronize access to the algorithm across all of the pods in the given Kubernetes cluster..backfillSyncUnsafe()- This method performs the actualSCANof the Redis database, applying a TTL to all persistent keys using theEXPIREoperation.
These three methods are the "work horses" of the algorithm. The rest of the methods in the RedisTTLBackfillService ColdFusion component support the operation of these methods. Let's take a look:
component
accessors = true
output = false
hint = "I scan the Redis key-space, using a cursor, and add a TTL to all persistent keys."
{
// Define properties for dependency-injection.
property datadog;
property debugLogger;
property distributedLockService;
property featureFlagService;
property jedisPool;
property jedisPoolJavaLoader;
/**
* I initialize the backfill service.
*/
public any function init() {
// I determine how long synchronized access to the backfill algorithm will last.
// All work performed for one chunk should fit within this time-window.
// --
// CAUTION: The synchronization mechanism will try to execute multiple scans
// during this lock-window if time allowed.
variables.lockDurationInSeconds = 20;
// I am the key at which to store the cursor value for our SCAN operation. The
// cursor itself will be stored in Redis (but, with a TTL, obviously).
variables.scanCursorKey = "operations-RAIN-2811-scan-cursor";
// I am the TTL to apply to persistent keys (ie, keys with no configured TTL).
variables.ttlInSecondsForPersistentKeys = (
60 * // 1 minute (60 seconds).
60 * // 1 hour (60 minutes).
24 // 1 day (24 hours).
);
}
// ---
// PUBLIC METHODS.
// ---
/**
* I am the ingress to the Redis TTL backfill service. I orchestrate the algorithm in
* a manner that is both ASYNCHRONOUS and SAFE to call. Meaning, no error will ever
* bubble-up to the calling context, and no blocking operation is performed, which
* means that we can safely piggy-back on any other process (such as the server's
* health-check).
*/
public void function backfillAsync() {
try {
// SAFETY VALVE: Check to see if the feature flag is turned-off.
// --
// NOTE: Our feature flags are controlled by LaunchDarkly which uses an
// in-memory cache of keys and rules. As such, this check will have
// negligible, "non-blocking" execution time.
if ( ! shouldProcessBackfill() ) {
return;
}
thread
name = "RedisTTLBackfillService.backfillAsync"
action = "run"
{
backfillSyncSafe();
} // END: CFThread.
} catch ( any error ) {
debugLogger.error( error, "Could not spawn async thread for Redis TTL backfill." );
}
}
// ---
// PRIVATE METHODS.
// ---
/**
* I manage the synchronization (locking) and the execution of the backfill inside the
* asynchronous thread. The execution of this method is SAFE; meaning, all errors will
* be caught, logged, and swallowed.
*/
private void function backfillSyncSafe() {
try {
// Since the TTL is going to be applied using a SCAN cursor, we can really
// only have one server executing a chunk of this algorithm at a time. As
// such, we have to synchronize across all of the servers in this cluster.
synchronizeAcrossServers(
() => {
// Once we are inside the synchronized execution, the scan will
// execute much faster than our lock-duration (Redis is hella fast).
// As such, we can try to execute multiple scans while the lock is
// still active.
// --
// NOTE: We're using 90% of the lock window to perform scans.
var executionWindowInMilliseconds = ( lockDurationInSeconds * 1000 * 0.9 );
var tickCountCutoffAt = ( getTickCount() + executionWindowInMilliseconds );
// Continue scanning until we reach the end of our scan window.
// --
// NOTE: As a SAFETY VALVE we are checking the feature flag on each
// iteration so that we can force a halt to the algorithm if needed.
while ( shouldProcessBackfill() && ( getTickCount() <= tickCountCutoffAt ) ) {
backfillSyncUnsafe();
sleep( 1000 );
}
}
);
} catch ( any error ) {
debugLogger.error( error, "Error processing sync Redis TTL backfill." );
}
}
/**
* I implement a SINGLE PASS of the actual Redis TTL backfill portion of the overall
* algorithm. This method expects to execute in a SAFE and SYNCHRONIZED context.
*/
private void function backfillSyncUnsafe() {
var startedAt = getTickCount();
var scanCursor = withJedis(
( jedis ) => {
return( jedis.get( javaCast( "string", scanCursorKey ) ) );
}
);
// If the cursor value is NULL, it means that this is the first execution of the
// TTL backfill algorithm in this cluster. As such, we need to start iterating
// at the beginning (ie, an offset of 0).
if ( isNull( scanCursor ) ) {
scanCursor = 0;
// If the stored cursor value is ZERO, it means that the TTL backfill algorithm
// has successfully scanned-over the entire key-space in this cluster. We have
// obtained enlightenment.
} else if ( scanCursor == 0 ) {
return;
}
var scanParams = jedisPoolJavaLoader
.create( "redis.clients.jedis.ScanParams" )
.init()
.count( javaCast( "int", getScanKeyCount() ) )
;
// Get the chunk of keys to examine. We can't SCAN and do a TTL in a single
// operation. As such, we'll have to gather the keys at this scan offset and then
// check the keys for a TTL in the next step.
var scanResults = withJedis(
( jedis ) => {
return( jedis.scan( javaCast( "int", scanCursor ), scanParams ) );
}
);
var nextCursor = scanResults.getCursor();
var keys = scanResults.getResult();
// Now that we have the list of keys that we want to inspect in this chunk, we
// need to generate a pipeline that gathers the TTL for all of the targeted keys.
// This way, we don't block and wait for each result (it's the same number of
// operations, but they are executed in a manner that buffers results in Redis
// for a final read / sync operation).
var ttlResults = withJedis(
( jedis ) => {
var pipeline = jedis.pipelined();
for ( var key in keys ) {
pipeline.ttl( javaCast( "string", key ) );
}
return( pipeline.syncAndReturnAll() );
}
);
// In the results, a TTL of -1 means that the key exists but does NOT have a TTL.
// These are the keys that we want to expire. To gather the keys, we have to
// map the keys to the TTL results and then filter on -1.
var persistentKeys = keys.filter(
( key, i ) => {
return( ttlResults[ i ] == -1 );
}
);
// Now that we have collected our persistent keys, let's explicitly set the TTL
// and update the cursor for the next iteration of the algorithm. Again, we're
// going to perform this using a pipeline for better performance.
withJedis(
( jedis ) => {
var pipeline = jedis.pipelined();
for ( var key in persistentKeys ) {
pipeline.expire(
javaCast( "string", key ),
javaCast( "int", ttlInSecondsForPersistentKeys )
);
}
pipeline.setex(
javaCast( "string", scanCursorKey ),
javaCast( "int", ttlInSecondsForPersistentKeys ),
javaCast( "string", nextCursor )
);
pipeline.sync();
}
);
// Since this algorithm is going to be executing in the background, across many
// clusters, let's record the number of keys that we are looking at using StatsD.
// This way, we can look in our metrics dashboards to get a sense of which
// clusters are still processing (and how fast the algorithm is).
recordKeyCount( "all", keys.len() );
recordKeyCount( "persisted", persistentKeys.len() );
recordExecutionTime( startedAt );
}
/**
* I return the number of keys to scan in a single iteration of the algorithm. This is
* controlled by a LaunchDarkly multi-variant feature flag so that we can ramp the
* aggressiveness of the scan UP OR DOWN based on the cluster and the performance of
* the application.
*/
private numeric function getScanKeyCount() {
return( val( featureFlagService.getMultiVariantByUserID( "operations", "operations-RAIN-2811-redis-ttl-backfill-key-count" ) ) );
}
/**
* I record the time (in milliseconds) that it took to execute a single pass of the
* scan algorithm. Each metric will get implicitly tagged by our stats aggregation
* with the cluster so that we can see how each cluster is performing.
*
* @startedAt I am the tick-count at which the current pass of the scan started.
*/
private void function recordExecutionTime( required numeric startedAt ) {
datadog.timing(
key = "statsd.projects.redis-ttl-backfill.time",
milliseconds = ( getTickCount() - startedAt )
);
}
/**
* I record the key-count for the given metric. Each metric will get implicitly tagged
* by our stats aggregation with the cluster so that we can see which clusters are
* still inspecting keys.
*
* @metric I am the metric being recorded.
* @count I am the count of keys being recorded.
*/
private void function recordKeyCount(
required string metric,
required numeric count
) {
datadog.increment(
key = "statsd.projects.redis-ttl-backfill.#metric#",
magnitude = count
);
}
/**
* I determine if this machine should attempt to process the backfill of the Redis TTL
* based on a feature flag. This allows us to turn this process on / off if the very
* execution of the task seems to be having a detrimental affect on Redis or on the
* application servers.
*
* THIS IS OUR SAFETY VALVE.
*/
private boolean function shouldProcessBackfill() {
return( featureFlagService.getFeatureByUserID( "operations", "operations-RAIN-2811-redis-ttl-backfill" ) );
}
/**
* I synchronize execution of the given callback across all of the servers in the
* cluster using a distributed lock.
*
* CAUTION: Lock errors are swallowed. All other errors will bubble-up.
*
* @callback I am the callback whose execution is synchronized.
*/
private void function synchronizeAcrossServers( required function callback ) {
try {
// CAUTION: We are not providing a lock wait-timeout here because we want to
// synchronize access to Redis across all of the servers in this cluster. As
// such, if the lock is already in place, it means one of the other servers
// is already consuming the SCAN cursor - just let this code throw a Lock
// error while the other server is doing the work.
var distributedLock = distributedLockService.obtainLockWithoutTimeout(
name = "RedisTTLBackfillService.synchronizeAcrossServers",
expiration = lockDurationInSeconds
);
try {
callback();
} finally {
distributedLock.release();
}
} catch ( InVisionApp.Lock error ) {
// We're expecting Locking errors to occur for MOST servers while the
// backfill process has not yet completed. As such, we can safely Ignore
// this error.
}
}
/**
* I provision a Jedis connection (to Redis) from the connection pool and pass it to
* the execution of the given callback. The connection is managed properly so that
* the callback does not have to worry about it. The return value of the callback is
* passed through to the calling context.
*
* @callback I am the function to execute with a Jedis connection.
*/
private any function withJedis( required function callback ) {
try {
var jedis = jedisPool.getResource();
return( callback( jedis ) );
} finally {
jedis?.close();
}
}
}
ASIDE: You may notice that my feature flag names all contains
RAIN-XXXX. I am on "Team Rainbow" and that number represents the JIRA Ticket associated with the work. We use this pattern or naming so that every feature flag can easily be tracked back to the documented business case that necessitated it.
This ColdFusion component is only a couple-of-hundred lines of code; but, I feel like it's packed with a multitude of interesting tidbits: closures, threading, distributed locks, feature flags, StatsD metrics, and Redis operations. It was quite thrilling to write!
Once you get down to the meat of the algorithm, the approach is an uncomplicated brute-force traversal:
- Get
Nnumber of keys using theSCANoperation. - Check the
TTLfor those keys. - Apply the
EXPIREoperation to each persistent key. - Save cursor offset for next
SCANoperation.
At the end of each execution, I am logging a set of StatsD metrics so that I could watch the progression of the TTL backfill across all of the production applications. I then created a DataDog dashboard for our multi-tenant environment:

As you can see from the graphs, in just under 2-hours, this Redis TTL backfill service scanned-over 9.3M keys and applied a TTL to 6.25M keys.
ASIDE: You may notice that the number of keys in this Redis database is reported as 14M, but that I only iterated over 9M. I suspect that the 5M missing keys represent very short-lived keys. The
SCANoperation only guarantees a traversal of keys that are present at the time theSCANcursor is created. As such, transient keys may not show-up during traversal.That said, if I run
info keyspaceon this instance, we can see that just about every single key has a TTL:> info keyspace # Keyspace db0:keys=14763116,expires=14763090,avg_ttl=0So, even though I only examined 9M keys, almost the entire set of keys in this Redis instance is now set to expire at some point.
You can also see from the graphs that the number of Redis operations slowly ramps-up. That's me using the multi-variate LaunchDarkly feature flag to gradually increase the run-rate of the algorithm:
As the number of keys in each SCAN operation increased, I monitored the application performance using various New Relic and DataDog dashboards. Once everything appeared copacetic as one level of aggressiveness, I moved the feature flag up to the next level.
Now, the above graph represents our Multi-Tenant system. But, this algorithm was simultaneously running in hundreds of Single-Tenant instances. Each of which was logging StatsD metrics that I could graph in Grafana:

Each one of those colorful bars represents the StatsD metrics in a different Single-Tenant instance. The magnitude of the Single-Tenant and Multi-Tenant graphs are difference (which make sense given the relative number of users in each system); but, you can see that the ramp-up of the algorithm is the same in all environments.
Once the Redis TTL backfill algorithm completed in all environments, I turned off the LaunchDarkly feature flags and everything returned to normal.
This was a lot of fun to write. Not only because it has some very interesting technical aspects to it; but, because it I believe it showcases the joy of just getting $h!t done without over-thinking it. I am sure there are other ways that I could have gotten this done more elegantly; but, there's no doubt that such approaches would have required cross-team coordination. And, I ain't got time for that. So, I chose the brute-force method that allowed me to bias towards action and take ownership of the problem.
Yo, how awesome are Lucee CFML / ColdFusion, LaunchDarkly, and Redis? I feel lucky to wake up in the morning and get to work with these technologies.
Want to use code from this post? Check out the license.
Reader Comments
@All,
So, 24-hours after this process started, the keys began to expire. However, having so many keys expire at the same time did lock up the Redis database ever-so-briefly. To give you a sense of the magnitude, the production app at the time, was getting tens-of-thousands of requests per minute, and I saw just over 1K errors in the logs regarding resource pools:
The wiser move, on my part, would have been do add some jitter to the expiration:
... where the
addJitter( time )method would have randomly added or subtracted some value, like:This would +/- an hour, spreading the expiration out a bit more, putting a less pressure on the DB. You can read more about why Redis can lock up during an expiration:
https://redis.io/commands/expire#how-redis-expires-keys
I figured it wouldn't be so bad; but, it was slightly worse than I expected it to be.
Holy cow! I think I will need to read this several times, whilst consulting the docs on Redis' Website.
Plus I don't really know much about Launch Darkly or DataDog.
But, this looks mighty impressive and must have been a lot of fun to watch the progress of your scan, as those graphs gradually built up.
When I look at stuff like this, I feel that the UK, is living in the dark ages, in terms of our knowledge of how to integrate systems.
Just out of interest, how do you actually connect your Coldfusion Service to all the different application clusters? Do you literally call a single method in your service and everything else just happens?
I have just had a look at LaunchDarkly.
So, essentially, it is really just a set of fancy conditional statements that are connected to a GUI dashboard. And you can switch the flags on and off.
So, presumably, you have lots of chunks of code on your production server that aren't being used, depending on which way your flags are set.
I have kind of been doing this with a CF Application that I have been building for the last 6 years. It is a CMS with a giant global settings dashboard. I can turn features on and off and APPLICATION scoped flags deal with the toggle.
Just one thing:
What does this part do?
@Charles,
The application clusters are all managed by our Ops Team; and, to be honest, I have no idea how most of it works :D All of our deployments are done via a Slack bot:
The Slack bot then makes API calls to the Ops platform which makes all the magic happen. It takes the current build of the Service and incrementally rolls it out to all of the servers in the different clusters. To me, it's all MAGIC :D
Re: Feature Flags
Yeah, it's basically just conditionals in the code. The nice thing about LaunchDarkly is that they have a rather nice UI dashboard for it. And the changes in the dashboard are synced to the application seamlessly using some sort of streaming protocol. So, when you check for the state of a feature flag, you're making a blocking HTTP request or anything - you're just checking an in-memory cache of the feature-flag values.
Re:
.setex()SETEXis just a Redis command that Sets a key with a value and an expiration time:https://redis.io/commands/setex
So, in that line, what I am doing is saving the next value for the
SCANcursor. You can think of this like thei++step in aforloop. This way, the next time the algorithm runs an iteration, it will get the next value of cursor and will start farther along in the key-space traversal.Thanks for the explanation.
I had a look at the:
Description and it only has 2 arguments on the Redis website.
However, I found this very obscure link:
http://tool.oschina.net/uploads/apidocs/jedis-2.1.0/redis/clients/jedis/Pipeline.html
And here, it indeed has 3 arguments, although the argument description was pretty sparse.
So, I also looked at the official Java Docs, and I found lots of stuff on pipeline, but not on pipelined().
Am I right in thinking that a pipeline is a connection that remains open like a websocket?
@Charles,
Here's some better documentation on "Pipelining" on the Redis site:
https://redis.io/topics/pipelining
The
.pipelined()method is specific to Jedis, which is just a Java implementation of the Redis driver; so, some it will differ from the Redis-CLI. As far as the underlying technology, the above link has some info, but I don't fully understand all of it. It sounds like the requests all fire as they are requested; but, that the processing doesn't stop-and-block until each request finishes. Instead, the responses are queued-up in the Redis server, and then retrieved as a final operation.Honestly, it's all just magic to me :P
Wow. Pipelines are awesome.
It says that I can line 10K requests on the server. Actually, it doesn't specify a limit, but due to the memory requirements for queuing them, it advises 10K as a maximum batch limit.
This beats the RTT required for a normal request, between client & server.
It sure sounds like magic!