
In our last episode, I’d expanded our query to include DisplayName and Age – two columns that weren’t in our nonclustered index:
|
1 2 3 4 |
SELECT LastAccessDate, Id, DisplayName, Age FROM dbo.Users WHERE LastAccessDate > '2018-09-02 04:00' ORDER BY LastAccessDate; |
So as a result, I was getting key lookups in the execution plan:
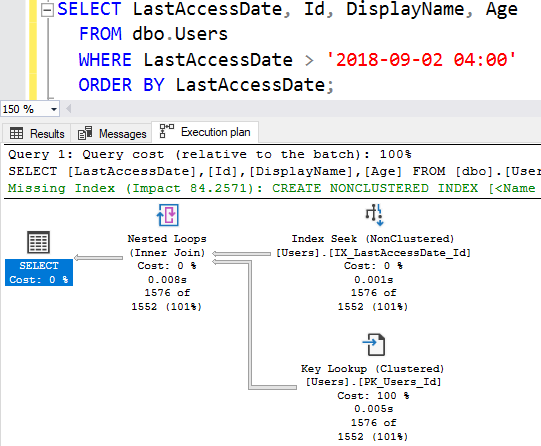
And I spent a lot of time talking about the overhead that each key lookup incurs. Astute readers among the audience (as in, other people, not you) probably noticed the 2018-09-02 04:00 date and thought it was rather odd that I’d switch dates while telling this story.
Let’s query for just one hour earlier.
We were only getting 1,576 rows for Sept 2 4AM and after (because the data export I’m using was done on Sept 2, 2018) – let’s try 3AM:
|
1 2 3 4 |
SELECT LastAccessDate, Id, DisplayName, Age FROM dbo.Users WHERE LastAccessDate > '2018-09-02 03:00' ORDER BY LastAccessDate; |
And SQL Server ignores my index:
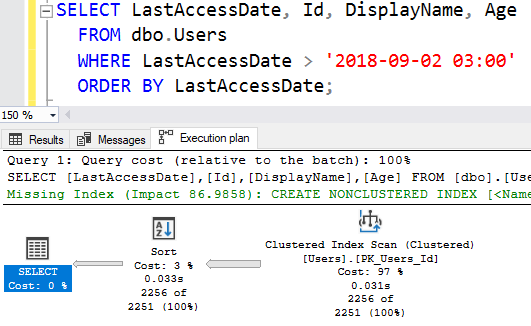
Even though only 2,256 rows are being returned, SQL Server would rather just scan the whole table than deal with the index seek + key lookup combo. There are 299,398 rows in the table – and even though we’re querying LESS THAN ONE PERCENT OF THE TABLE, the index gets ignored.
Is that the right decision?
To find out, let’s force the index.
I’ll run two queries back to back – first, letting SQL Server decide which index to use, and then second, forcing the nonclustered index by using a query hint:
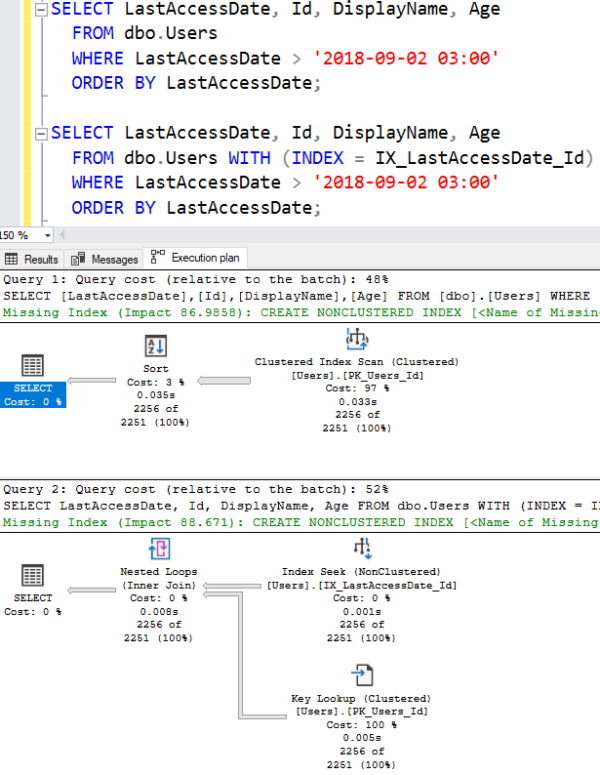
Then check the Messages tab for our logical reads:

When we do a table scan, that’s 7,405 reads.
When we use the index, it’s 6,927 reads – assuming that we’re only getting 2,256 rows.
It’s tempting to say SQL Server was wrong, but here’s the thing: the table scan is a predictable 7,405 reads no matter how many rows are brought back from the query. It’s a safe decision when SQL Server just can’t be sure exactly how many rows are going to come back. If I query for just one more hour earlier, at 2AM:
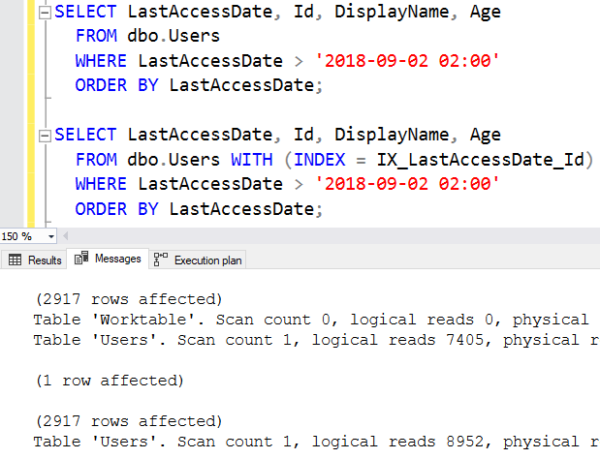
Now that 2,917 rows match our filter, the clustered index scan pays off: it’s reading less rows than the combination of the index seek + key lookup. The key lookup costs more and more with every additional execution.
If we go back just one day, the difference becomes huge:

We’re only getting 16,325 rows – about 5% of the table – and yet if we use the index, we do so many logical reads that it’s like reading the entire table seven times over! That’s exactly the problem SQL Server is trying to prevent, dealing with key lookups that read more pages than there are in the table.
Our 2AM-4AM WHERE clause is hovering around the tipping point.
Even though we’re only bringing back less than 1% of the users, it’s already more efficient for SQL Server to scan the entire table rather than use our index.
In our examples, the 3AM query erred just a tiny, tiny bit on the conservative side, picking a clustered index scan when an index seek + key lookup would have been more efficient. In this example, who cares? It’s a difference of less than 500 page reads. I’m happy with that decision.
So how does SQL Server figure out which query plan – the index seek or the table scan – is more appropriate before actually executing the query? That’s where statistics come in, and we’ll talk about those next.
One solution is to widen the index.
When you see an index seek + key lookup in an execution plan, hover your mouse over the key lookup and look at the Output List:
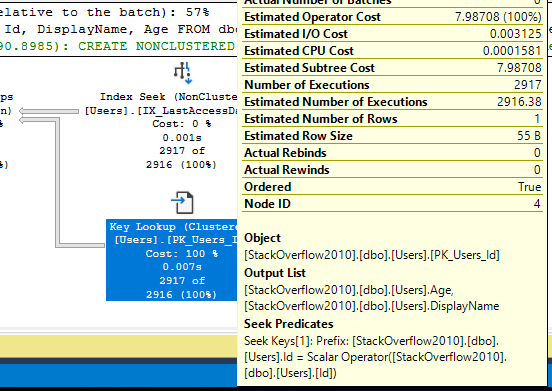
Then start asking a few questions:
Can my query live with less rows? The whole problem with the tipping point is based on the number of rows we’re bringing back. If you can do pagination, do it. If you can restrict the number of rows outright or force users to be more selective with their searches, do that too. When you truly want to scale, everything is important.
Can my query live with less columns? Sometimes it’s a matter of folks doing a SELECT * out of laziness, but sometimes we really do need all of the columns. The more columns we need, the less concerned I am about the key lookups – because I simply can’t afford to maintain multiple copies of the full table, all sorted in different orders.
How large are the columns? If they’re big ol’ NVARCHAR(MAX), VARCHAR(MAX), JSON, XML, etc., then the discussion is over. I’m fine with the cost of the key lookup. I wouldn’t want to add them to indexes because they’ll simply take up too much space.
How frequently are the columns updated? SQL Server doesn’t have asynchronous indexes: every index has to be kept up to date at all times with the clustered index. If the Age column changes all the time, for example, then it may not make sense to duplicate it on multiple indexes since we’re going to have to grab locks on those indexes when we run updates. (Inserts & deletes don’t matter as much since we have to touch the indexes at that point anyway no matter how many columns they contain.)
If we do need those columns, should we add them to the nonclustered index? By adding them, we could get rid of the cost of the key lookup altogether.
There are no stone-carved right-and-wrong answers here, only a series of decisions and compromises to make in your quest for performance. When you first get started, you don’t really notice when SQL Server tips over from index seeks to table scans because your data is relatively small. As your data grows and your users want higher performance, that’s when this kind of thing starts to matter more.
I won’t dig too deeply into nonclustered index design in this blog post series, but if you’re interested in that kind of thing, check out my one-day Fundamentals of Index Tuning course.
Next up, let’s see how SQL Server figures out where the tipping point will be for a query.

5 Comments. Leave new
“The more columns we need, the less concerned I am about the key lookups – because I simply can’t afford to maintain multiple copies of the full table, all sorted in different orders.” Sometimes it is worth doing exactly that and sometimes it isn’t.
What is the ratio of reads to updates of the columns in the proposed wider index and how big are they? (You covered those issues.) How critical is the performance of the query? How big is the table with all its indexes vs, how much RAM and disk space are we willing to pay for? This is another case where there are “no stone-carved right-and-wrong answers here”.
Key lookups become expensive on an OLTP database using a magnetic drive and insufficient RAM. Though anyone doing that sort of thing is probably not paying enough attention to Brent’s pop quiz ( https://ozar.me/2014/09/pop-quiz-things-cost/ ).
“SQL Server doesn’t have asynchronous indexes”
Pedantic comment:
Full text indexes are updated asynchronously. Also, they’re a waste of your SQL license; don’t use them.
Great point!
“Can my query live with less rows? ” or “Can my query live with fewer rows? ” 🙂