
Because we have ranges! 🙂
The problem with eager evaluation
Since C++ was invented, developers have often lamented the fact that expressions are eagerly evaluated. For example, when performing any kind of gradient descent, we often find ourselves wanting to compute the sum of two mathematical vectors, where one of those vectors is scaled by some constant like so:
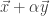
But unfortunately an expression like this often results in first computing a new vector as the result of 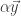
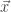
To avoid these wasted cycles, programmers often roll their own specialized functions for every possible scenario like so:
using Vector = /*...*/;
using Scalar = /*...*/;
Vector LinearCombinationOfVectors(const Vector& left, Scalar left_scalar, const Vector& right, Scalar right_scalar)
{
Vector result;
for(size_t i = 0; i < result.size(); ++i)
result[i] = left[i] * left_scalar + right[i] * right_scalar;
return result;
}
// ...
auto result = LinearCombinationOfVectors(x_vec, 1.0, y_vec, alpha);Look familiar?
If it doesn’t, I promise you code like this exists. In fact, here’s a cplusplus.com forum post where someone did exactly that for computing a conjugate gradient.
On a small scale, code like this is fine. In fact, the code I linked to is overall surprisingly well written not just for a cplusplus.com forum post, but for scientific code in general*.
On a larger scale, the codebase becomes absolutely littered with every possible permutation of these computations†. These functions are often implemented N times because there are so many that one couldn’t be bothered to check if the function they needed had already been written.
Functional programming languages like Haskell and F# have lazily evaluated expressions, meaning that values are computed on demand — only when they’re needed. This feature can be extremely useful for composing expressions endlessly until we’re ready to evaluate them.
It’s so useful that people like to simulate this sort of lazy computation in eager languages (like C++).
(*the code in the forum post is very representative of the kind of code I encounter on a daily basis.)
(†Oftentimes this is a necessary evil when you are trying to maximize performance with eager evaluation. But if you’re going for top of the line performance, I recommend you first reach for a linear algebra library instead of rolling your own.)
Expression Templates
Enter Expression templates, a way to represent a lazy computation in C++. Expression templates have been around probably as long as C++ has. As recent as CppCon 2019, Bowie Owens gave an interesting talk about how Expression Templates helped his team in the financial sector write more readable and testable code in C++17.
There are many resources online that demonstrate how expression templates work, so I’ll just give a brief rundown of them here. (Note: the goal isn’t to write a perfect implementation, but merely to demonstrate the concepts).
- First we create a class to represent an expression between two objects (like Addition).
template<class T, class U, class Callable>
struct BinaryExpression
{
// ...
auto operator()() const
{
return callable(*left, *right);
}
const T* left = nullptr;
const U* right = nullptr;
Callable callable;
};- Then we create a function class representing the computation for two objects:
struct Plus
{
template<class T, class U>
auto operator()(const T& left, const U& right) const
{
return left + right;
}
};(Or we could use one of the built-in function classes like std::plus, or even a lambda.)
- And now we can bind data (e.g., integers) to an operation (addition) via the
BinaryExpressionclass, to be invoked later:
int left = 1;
double right = 40.0;
BinaryExpression expr(left, right, Plus{});
// ...
expr(); // 41
// ...
short next_value = 1;
BinaryExpression expr2(expr, next_value, Plus{});
// ...
expr2(); // 42
C++17’s deduction guides saves the caller the hassle of specifying template arguments (or us providing a trampoline function like make_binary_expression) when constructing a BinaryExpression
template<class T, class U, class Callable>
struct BinaryExpression
{
template<class Func>
BinaryExpression(const T& _left, const U& _right, Func&& _func) : left{&_left}, right{&_right}, callable{std::forward<Func>(_func)}
{}
// ...
};
template<class T, class U, class Func>
BinaryExpression(const T&, const U&, Func&&) -> BinaryExpression<T, U, Func>;Composing BinaryExpressions is made easy if we allow them to be implicitly converted to the same type as the result of invoking them like so:
template<class T, class U, class Callable>
struct BinaryExpression
{
// ...
using result_t = decltype(std::declval<Callable>()(std::declval<const T&>(), std::declval<const U&>()));
operator result_t() const
{
return this->operator()();
}
};Yay! Lazy evaluation in C++…. between scalars. These can be useful for lazily evaluating expression trees or for implementing the Command Pattern. We’re not quite there yet, though, because the holy grail of expression templates is evaluating expressions between containers on-the-fly.
Expression templates for containers
We still have issues when we wish to compose binary expressions over collections, so let’s create a BinaryContainerExpression to act like a collection by exposing an indexing operator that will lazily compute the next value. You’ll notice that the impl is nearly identical to BinaryExpression; we add operator[] and size methods and remove a converting operator:
template<class T, class U, class Callable>
struct BinaryContainerExpression
{
template<class Func>
BinaryContainerExpression(const T& _left, const U& _right, Func&& _callable) :
left_{&_left},
right_{&_right},
callable_{std::forward<Func>(_callable)}
{
assert(_left.size() == _right.size());
}
auto operator[](size_t index) const
{
return callable_((*left_)[index], (*right_)[index]);
}
size_t size() const
{
return left_->size();
}
const T* left_= nullptr;
const U* right_= nullptr;
Callable callable_;
};
template<class T, class U, class Func>
BinaryContainerExpression(const T&, const U&, Func&&) -> BinaryContainerExpression<T, U, Func>;And now we can create and compose binary expressions over containers like so:
std::vector<int> left_vals{1, 2, 3};
std::vector<int> right_vals{1, 1, 1};
auto plus = [](int lhs, int rhs){return lhs + rhs;};
auto add_vectors = BinaryContainerExpression(left_vals, right_vals, plus);
// print 2 3 4
for(size_t i = 0; i < add_vectors.size(); ++i)
std::cout << add_vectors[i] << std::endl;
std::vector<int> more_vals = {10, 20, 30};
auto add_more_vectors = BinaryContainerExpression(add_vectors, more_vals, plus);
// print 12 23 34
for(size_t i = 0; i < add_more_vectors.size(); ++i)
std::cout << add_more_vectors[i] << std::endl;We can even solve our scaled vector addition problem from earlier:
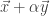
auto alpha = 4;
auto add_scaled = [&alpha](int lhs, int rhs){return lhs + alpha*rhs;};
auto add_scaled_vectors = BinaryContainerExpression(left_vals, right_vals, add_scaled);
// print 5 6 7
for(size_t i = 0; i < add_scaled_vectors.size(); ++i)
std::cout << add_scaled_vectors[i] << std::endl;Demo
If we wanted to get extra fancy, we could create a unary container expression class to represent the scalar * vector operation, and then compose that expression into a binary expression that adds the "lhs" vector. But that’s not the point here.
We could also do some fancy operator overloading to allow the client to just use + and * to get what they want, but again, not the point. Bowie does this in his talk, so I encourage you to check that out.
Something is missing…
Two things are bothering me:
- A scalar can be thought of as a container with a single element, right? So why can’t we use
BinaryContainerExpressionfor both scalars and containers?
- This is modern C++; we should be able to write a ranged-for loop over our
BinaryContainerExpressionlike so:
for(auto next_element : expression)
// ...
So let’s get started on addressing those.
We’ll create a make_single_container helper that wraps a variable in a container-like class for scalars, and then we’ll add begin and end to our BinaryContainerExpressionClass….
Wait a second.
This looks familiar.
Oh yeah,
We’ve just reinvented ranges
Ranges
In C++20, we finally get ranges (po896), which all but deprecates our need for expression templates.
What’s in a range?
Concretely, std::vector is a range. So is a std::list, or any standard collection, really. A range is a generalization of a container that basically says "You can iterate over this thing".
More formally, a Range is any object C for which calling ranges::begin(C) and ranges::end(C) is well-defined. Beyond that, there are all kinds of specializations like a SizedRange for which we know the size in constant time. etc.
Views
Views are what we’re actually interested in from the Ranges proposal. The difference between a range and a view is subtle. A view is a range, but not vice versa. Concretely, a view can be a range that generates its elements on demand. See where I’m going with this.
More formally, a view specializes the range concept to additionally require constant time copy, move, and assignment operators; the cost is not tied to the number of elements in a view (which might actually be infinite). For example, a view over a std::vector under the hood really just wraps the begin and end iterators.
Generating elements on demand
"Generating elements on demand" is the wording used in the proposal, but another way of phrasing it might be "lazily evaluating an expression that returns a value". Or, in other words, the entire purpose of expression templates.
The power of views becomes apparent when you realize you can compose transformations on them.
(Note: until we get compiler support for ranges, we shall be using Eric Niebler’s range-v3 library, from which the proposal is based.)
Here’s a simple example of adding 1 to each element of a std::vector<int>
using ranges::views::transform;
std::vector<int> elements = {-1, 0, 1};
auto add_one_view = elements | transform([](int _next){return _next + 1;});Evaluating add_one_view will lazily generate the next element in the view. We can print the entire view with a range-based for loop like so:
// print 0 1 2
for (auto element : add_one_view)
std::cout << element << " ";
However, Eric was kind enough to overload the stream operators for printing ranges for us, so we can write this instead:
// print [0,1,2]
std::cout << add_one_view;
We don’t need no stinking expression templates!
Ranges covers all* the use cases that expression templates do, except that ranges are now built into the language, whereas you’d have to find a library for expression templates, or write your own (shudder).
(*or nearly all, I’m sure there are still some good use cases for expression templates)
Binary scalar expressions
Eric also realized that a variable could be thought of as a container (range) consisting of simply one element. So Ranges comes with a View named single_view that makes a singular variable appear as a range.
Here’s how we can compose binary expressions on scalars to be evaluated later with views (refer to our example with BinaryExpression way above for reference of how it was done before):
int left = 1;
double right = 40.0;
auto expr = zip_with(std::plus<>{}, single_view{left}, single_view{right});
// print [41]
std::cout << expr << std::endl;
short next_value = 1;
auto expr2 = zip_with(std::plus<>{}, expr, single_view{next_value});
// print [42]
std::cout << expr2 << std::endl;Demo
Granted, if you want to specifically access the value, you’d need to dereference the begin() iterator of your view.
Lazy binary expressions over containers
We can very easily implement lazy vector addition with ranges:
std::vector<int> left_vals{1, 2, 3};
std::vector<int> right_vals{1, 1, 1};
auto add_vectors = zip_with(std::plus<>{}, left_vals, right_vals);
// print [2, 3, 4]
std::cout << add_vectors << std::endl;
std::vector<int> more_vals = {10, 20, 30};
auto add_more_vectors = zip_with(std::plus<>{}, add_vectors, more_vals);
// print [12, 23, 34]
std::cout << add_more_vectors << std::endl;And scaled vector addition:
std::vector<int> left_vals{1, 2, 3};
std::vector<int> right_vals{1, 1, 1};
auto alpha = 4;
auto scaled_rhs = right_vals | transform([&alpha](int val){return alpha * val;});
auto scaled_addition = zip_with(std::plus<>{}, left_vals, scaled_rhs);
// print [5,6,7]
std::cout << scaled_addition << std::endl;Demo
This syntax is much cleaner than before; we instead create a new range out of our right_vals that will lazily provide scaled values. With expression templates, we’d need to model a unary expression that we could then pass into a binary expression. With ranges, this all comes for free.
Taking ranges further (too far?)
So far we’ve seen
- scalar/scalar binary operations
- vector unary operations (binding a scalar)
- vector/vector binary operations
We can go deeper
Matrix/vector multiplication
Multiplying a row-major order matrix by a column vector can also be done lazily with ranges:
// row-major
using Matrix = std::vector<std::vector<double>>;
// column vector
using Vector = std::vector<double>;
Matrix A = {{1, 2, 3},
{4, 5, 6}};
Vector x = {7,
8,
9};
auto product = A | transform([&x](const auto& row){
return inner_product(row, x, 0.0);
});
// print [50, 122]
std::cout << product;Demo
The hard part at this point is keeping track of what’s being piped into what (and now you can start to understand why functional programs are sometimes hard to read without excessive commenting).
Fortunately we wouldn’t encourage clients to write code like this every time they wanted to perform Matrix/vector multiplication; we’d pop that logic into an overload for operator* like so:
// Ax = B
auto operator*(const Matrix& A, const Vector& x)
{
auto product = A | transform([&x](const auto& row){
return inner_product(row, x, 0.0);
});
return product;
}
// ...
auto product = A * x;Matrix/Matrix multiplication
As a generalization of matrix/vector multiplication, we can also perform matrix/matrix multiplication.
This is a bit tricky w/ ranges because we have to return a range of ranges, but we can lean on our Matrix x vector multiplication we implemented above.
For the sake of this post, I’m not going to transpose a row-major matrix into a column-major matrix for the multiplication; rather I’ll assume it.
Here’s what it looks like:
auto operator*(const Matrix& A, const Matrix& B)
{
auto product = A | transform([&B](const auto& row){
return B * row;
});
return product;
}It’s not the easiest thing to wrap your head around on first blush. The code can be read as "For each row in A, multiply it by the B matrix as-if the row was a column vector and the B matrix was row-major.", which turns out to be equivalent to an inner product between each column of B with the row of A.
From the client’s perspective it’s not bad:
Matrix A = {{1, 2, 3},
{4, 5, 6}};
// assume column matrix
Matrix B = {{7, 9, 11},
{8, 10, 12}};
auto mat_product = A * B;
// print [[58,64],[139,154]]
std::cout << mat_product << std::endl;Why didn’t you create a transposed view?
Because it is a huge PITA.
In fact, Eric did originally create a transposed view over a matrix for his canonical "calendar" example (found here), except that it
- uses an undocumented
make_view_closurehelper, - uses a since-removed
interleaveview, and - took ~60 lines of code to implement
"60 Lines of code doesn’t sound like a lot"
We’re talking about transposing a matrix here. It’s not a complicated procedure. Granted, his code is more generic, but we can do it in eagerly evaluated code with an order of magnitude less code:
Matrix transposed_mat(const Matrix& mat)
{
size_t num_cols = mat[0].size();
Matrix toReturn(num_cols, Vector(mat.size(), 0));
for (size_t j = 0; j < num_cols; ++j)
for (size_t i = 0; i < mat.size(); ++i)
toReturn[j][i] = mat[i][j];
return toReturn;
}At this point, we kind of hate functional programming, and we kind of hate ourselves for writing this.
Simplified lazy evaluation
Ranges are great because they result in composable, lazily-evaluated expressions. The downside is that this can come at a cost in understandability and some occasional code bloat. (The performance trade-off is usually something you’ve already accepted when you decided to go with lazy evaluation).
Remember our first, eager approach to expressing a linear combination of two vectors?
using Vector = /*...*/;
using Scalar = /*...*/;
Vector LinearCombinationOfVectors(const Vector& left, Scalar left_scalar, const Vector& right, Scalar right_scalar)
{
Vector result;
for(size_t i = 0; i < result.size(); ++i)
result[i] = left[i] * left_scalar + right[i] * right_scalar;
return result;
}
// ...
auto result = LinearCombinationOfVectors(x_vec, 1.0, y_vec, alpha);It’s pretty simple. The downside is that pre-C++20 if we wanted this to be lazily evaluated, we’d have to range-ify it by creating an iterable class out of the local function variables.
It would be nice if we could simply write a "stateful" function that would return the first value, and then wait until it’s called again to retrieve the next, and so on.
In C++20, we can do that with coroutines (N4775).
Coroutines
For the purpose of this blog post, I’ll define a coroutine as
"A resumable function"
One thing the Python language absolutely nailed were generators:
def my_generator():
for val in range(0, 10):
yield val
my_generator looks like a function, but when you call it, you get an iterable object instead (a generator object).
gen = my_generator()
> gen
<generator object my_generator at 0x0000....>
Just like an Expression Template, generators compute the next value on demand.
Generators in C++20
I’ll spare you most of the nitty-gritty details about coroutines in this post; there are a few good deep dive posts on the web.
In C++20, coroutines are fancy functions whose data is stored on the heap instead of the stack. This allows them to persist after they’ve returned:
my_generator<int> generate_integers()
{
for (int i = 0; i < 10; ++i)
co_yield i;
}When the compiler encounters co_yield, it then generates a bunch of boilerplate code to make generate_integers resumable; just like the Python generator above.
my_generator<int> is a coroutine-friendly type. More formally, it’s called a promise object, and it must implement certain methods and specialize certain types to satisfy the compiler.
Just like when you write a template, you might assume certain methods exist on the template arguments, so too does the compiler when you write a coroutine.
Again, I’ll spare you the gritty details. The wording in the TS isn’t exactly user-friendly on what you have to do to properly write a coroutine (nor is the wording even finalized). The proposal does offer us a one nice thing; a sample implementation of generator<T>, which let’s just assume exists in namespace std*:
namespace std{
template<class T>
struct generator
{
// return true if the generator still has values to yield
bool move_next(){/*...*/}
// get the next value
T current_value(){/*...*/}
// ...
};
} // std(*in MSVC, when you pass the /await flag to enable coroutine support, you will automatically have access to std::experimental::generator)
Scaled vector addition as a generator
Let’s revisit our eagerly evaluated method that computes a linear combination of vectors one more time:
Vector LinearCombinationOfVectors(const Vector& left, Scalar left_scalar, const Vector& right, Scalar right_scalar)
{
Vector result;
for(size_t i = 0; i < result.size(); ++i)
result[i] = left[i] * left_scalar + right[i] * right_scalar;
return result;
}To turn this into a coroutine is simple; we change the return type to indicate a generator, and then we simply co_yield the next value:
std::generator<double> LinearCombinationOfVectors(const Vector& left, Scalar left_scalar, const Vector& right, Scalar right_scalar)
{
for(size_t i = 0; i < result.size(); ++i)
co_yield left[i] * left_scalar + right[i] * right_scalar;
}And we’d use it like so:
Vector left_vals{1, 2, 3};
Vector right_vals{1, 1, 1};
Scalar alpha = 4;
auto add_scaled_vectors = LinearCombinationOfVectors(left_vals, 1.0, right_vals, alpha);
// print 5 6 7
while(add_scaled_vectors.move_next())
std::cout << add_scaled_vectors.current_value() << " ";Composing with generators
We can represent scaled vector addition as three expressions:
- scaling the left vector
- scaling the right vector
- adding the scaled vectors
With coroutines, writing lazily evaluated code looks almost like writing classic eagerly evaluated C++.
First, an overloaded multiplication operator for scaling a vector:
std::generator<double> operator*(const Vector& vec, Scalar factor)
{
for(double val : vec)
co_yield val * factor;
}Next, an overloaded addition operator for adding two generators
std::generator<double> operator+(std::generator<double> lhs, std::generator<double> rhs)
{
while(lhs.move_next() && rhs.move_next())
co_yield lhs.current_value() + rhs.current_value();
}So long as we can represent a Vector as a generator, we can use this function to compute the final addition. It’s fairly straightforward to wrap the Vector in a generator; just co_yield the elements in a loop:
std::generator<double> as_generator(const Vector& vec)
{
for(double val : vec)
co_yield val;
}And now we can write our expression fairly readably:
Vector left_vals{1, 2, 3};
Vector right_vals{1, 1, 1};
Scalar alpha = 4;
auto linear_combination = as_generator(left_vals) + right_vals * alpha;
// print 5 6 7
while(linear_combination.move_next())
std::cout << linear_combination.current_value() << " ";
Demo
With coroutines, we can write fairly simple code and get all the laziness for free*. More importantly,
We didn’t need expression templates!
We could write more overloads and specializations etc. to make it even nicer or more generic, but you get the point.
(*Because coroutines are so new, compilers are a little behind on optimizing them as well as other code, so the performance degradation may be more than expected).
Something is missing…
When we iterate over our generator, we have to check a boolean condition, and then call a function to get the next value internally:
while(my_generator.move_next())
std::cout << my_generator.current_value();
What if we created begin and end iterators that performed these checks for us? Then we could write a ranged-for loop like so:
for(double value : my_generator)
std::cout << value;
Wait.
This looks familiar (again).
Oh yeah.
We just invented Ranges (again)
While the Coroutines and Ranges proposals were developed independently, the author(s) of the Ranges TS was paying attention. The range-v3 library already offers its own generator type that works with ranges:
ranges::experimental::generator<double> transposed(const Matrix& mat)
{
assert(!mat.empty());
size_t ncols = mat[0].size();
for(size_t j = 0; j < ncols; ++j)
for(size_t i = 0; i < mat.size(); ++i)
co_yield mat[i][j];
}Now we can treat our transposed function like a range that lazily produces values:
Matrix B = {{7, 8},
{9, 10},
{11, 12}};
int num_cols = B.size();
auto transposed_b = transposed(B) | chunk(num_cols);
// {{7, 9, 11},
// {8, 10, 12}};
std::cout << transposed_b;The chunk function is the key to transforming our generator from a one-dimensional range into a two-dimensional one. It produces sub-ranges consisting of the desired chunk size. When we pass in the expected number of columns per row in our transposed matrix, we get what we need.
"That’s a lot shorter than 60 LOC"
Indeed, it seems like we can achieve terser and clearer code when we mix Coroutines and Ranges.
"Now we can use our tranposed range for lazy matrix multiplication, right?"
Not quite. Ranges isn’t quite mature enough for this kind of functionality. Generators are barely in the range-v3 library, and the chunk function doesn’t quite produce a type that is compatible with the Ranges algorithms.
It will be very exciting to watch the features co-evolve in C++23 and beyond. Who knows what we’ll be able to do then?
A few caveats to Coroutines*
(Feel free to skip this section and go right to "Closing thoughts")
- Coroutines are usually not copyable because the underlying impl doesn’t play nicely
This leaves us with using reference semantics (pass by ref or std::move) when we want to pass our generators around. For example, if we wanted to decompose our linear combination generator above, we’d need to std::move:
auto scaled_rhs = right_vals * alpha;
auto linear_combination = as_generator(left_vals) + std::move(scaled_rhs);
- Passing temporary coroutines by rvalue reference to other coroutines is dangerous
Because of how coroutines work, a temporary bound to an rvalue reference passed to a coroutine will often go out of scope before the coroutine you’ve passed it to does, leading to undefined behavior.
For example:
std::generator<double> as_generator(const Vector& vec)
{
for(double val : vec)
co_yield val;
}
std::generator<double> wrapped(std::generator<double>&& gen)
{
while(gen.move_next())
co_yield gen.current_value();
}If we instrument generator<double> to tell us when the generator is destroyed, and run the following code:
Vector vals{1, 2, 3};
auto wrapped_gen = wrapped(as_generator(vals));
while(wrapped_gen.move_next())
std::cout << wrapped_gen.current_value() << " ";
The output we see is actually:
destroying coroutine
1 2 3 destroying coroutine
Demo
(clang 10.0.0 with -fcoroutines-ts)
Even though we successfully printed our values, the wrapped coroutine was actually destroyed beforehand, leaving us with undefined behavior. Similar code will simply segfault if you’re lucky.
- There’s no easy way to create generators of generators (e.g.,
generator<generator<double>>)
The main thing holding us back here is the lack of copy and reference semantics in existing implementations. For the time being, it seems that library writers are going to be overly cautious about these because they’re footguns that can lead to a double-free of an underlying handle to a coroutines activation context.
It is possible, though, if you’re willing to live dangerously. For example.
(*Since actual implementation of promise objects is up to library implementers at the moment, these observations are limited to current range-v3 implementation as well as the dummy simple impl in the Coroutines proposal)
Closing thoughts
Expression templates are dead, long live expression templates!
C++20 brings us two new tools that enable us to write lazily-evaluated expressions with drastically less effort:
- Ranges, and
- Coroutines
For the time being they’re mostly an either-or deal, however I’m confident that we’ll see a lot of mixed usage in the near future.
I presented a very simplified overview of what coroutines are in this post. In reality they’re a much more powerful tool than for making generators. For example, they’ll enable us to represent asynchronous state machines (like a client-server interaction) as a classical function.
I hope you’re as excited as I am for the new tools we’re getting in C++! Feel free to add a comment below with your own forays into ranges and coroutines!

I love these new features and this style of programming. Developers went on similar journey with Python and JavaScript. Took some adjusting, but now its “modern” style in both languages.
Really good article to show the flow from start to end, thanks!
Hi Michal,
Very glad to hear you enjoyed it. I agree with you. I like the direction C++ is headed, but I’m impatient about how long it will take until it feels ergonomically as easy to use as either of those two languages.
Great article. The Demo links are broken would you please update them.
Really broke things down nicely. It’s easy to think of ranges as just working on simple container class situations – avoiding a copy when working with vectors, bread-and-butter stuff, very intuitive to visualise why we need this. Using them for laze in linear algebra adds a whole new dimension on – we are now thinking in terms of time complexity as well as space complexity. Also, coroutines seems to be such a vast new feature, and in typical C++ way, is very flexible and has loads of scope in its implementation. Thus, many posts about it online can go into an awful lot of detail. But this post really breaks it down into core concepts simply.
Have there been any major updates since this was originally written? In particular, to the ability to use ranges and coroutines together. For some minimal sort of tensor BLAS, this interoperability seems like it will be really key.
The good news is that the recently-finalized C++23 standard includes generators (header
generator). The bad news is that there’s no compiler support yet. `ranges::inner_product` does not exist in the standard, so you’d need to roll your own or use the one from the ranges-v3 library. I’m kind of disappointed in the progress made in the 3.5 years since I published this post, but then again I think that standardization efforts were hampered by the pandemic. I have higher hopes for C++26.