
I recently picked up Crafting Interpreters. The project guides programmers through building their own interpreters for the Lox programming language. The first two chapters discuss what compilers and interpreters do.
I want to grasp this subject as quickly and deeply as I can. As I do, I find myself using many of the techniques we discussed in the leveling up series. These early chapters prompted me to do a lot of active reading. So in this post, I document that process to show you a specific example of how active reading might look.
First, Chapter 2 of Crafting Interpreters shares a high level roadmap of how most compilers and interpreters work. I wanted to see some specific examples to make my understanding more concrete. So after I read the chapter, I perused the code of some open source compilers.
Perusing Compilers
I started with the Swift compiler, since I write a fair amount about Swift.
I found an explanation of the Swift compiler architecture. It says:
Parsing: The parser is a simple, recursive-descent parser (implemented in lib/Parse) with an integrated, hand-coded lexer. The parser is responsible for generating an Abstract Syntax Tree (AST) without any semantic or type information, and emit warnings or errors for grammatical problems with the input source.
I didn’t know what a recursive-descent parser was, so I looked it up:
In computer science, a recursive descent parser is a kind of top-down parser built from a set of mutually recursive procedures (or a non-recursive equivalent) where each such procedure implements one of the nonterminals of the grammar. Thus the structure of the resulting program closely mirrors that of the grammar it recognizes.[1]
A predictive parser is a recursive descent parser that does not require backtracking.[2] Predictive parsing is possible only for the class of LL(k) grammars, which are the context-free grammars for which there exists some positive integer k that allows a recursive descent parser to decide which production to use by examining only the next k tokens of input.
Seeing the LL(k) grammars described like this made me wonder whether LLVM, the compiler framework that Swift uses, gets its name from this. So I checked out the LLVM website. I didn’t find an answer—just some information about where the name “LLVM” doesn‘t come from:
The LLVM Project is a collection of modular and reusable compiler and toolchain technologies. Despite its name, LLVM has little to do with traditional virtual machines. The name “LLVM” itself is not an acronym; it is the full name of the project.
Later (after I finished the chapter and wrote a draft of this post), Bob filled me in on this:
The “LL” in “LLVM” stands for “low-level”, or at least originally did. In “LL(k)” it stands for “left-to-right, leftmost derivation”. There are also LR parsers that do a “rightmost derivation”.
While I was reading, I didn’t want to get stuck on this name thing. I moved on. Here is the code on GitHub for the Swift parser. The lexer is hand-coded rather than generated with Lex or Yacc. I know this because I don’t see any .l or .y files, but I also know this because the explanation of the Swift compiler architecture linked above says that Swift uses “an integrated, hand-coded lexer.”
I poked around in the code some more, but I think I’ll understand better what I’m looking at once I’ve done some hands-on work in later chapters of Crafting Interpreters. Before I moved on to those later chapters, though, I wanted to look for one additional open-source compiler case study in which to root my abstract vision. I Googled around for a bit and found this piece of writing from Tom Lee about the Rust compiler.
That piece walks through the Rust compiler method by method, and I find that format for guided code spelunking extremely helpful. However, the stated intention of the piece is to highlight what makes Rust’s compiler unique. My nascent understanding of compilers and interpreters will grow fastest at this point if I instead focus on the characteristics that they share. (We have talked about concept fragmentation in learning environments before, and one time I even got a little ranty about it.) So I read the piece, appreciated it, and decided to come back to it again later.
I returned to Chapter 2 of Crafting Interpreters with a renewed focus on what happens inside a compiler. Bob has a map of the compilation process at the beginning of the chapter:

The chapter also includes the example output for an individual line of code at the lexing and parsing steps.
Here is the illustration for the line of source code after scanning:
![]()
After lexing:

And after parsing:

I decided to extend this train of illustrations by drawing what I imagine the output for this line of code to look like at each step of the compilation process that the chapter describes. I could then compare these illustrations, I reasoned, to the output of the compilers I’ll build while reading the future chapters and see how accurately I had represented what they did. I find that my most permanent lessons come from my mistakes, so I incorporate opportunities to guess (and thus, make mini-mistakes) into my learning when I can.
Illustrating the Concepts
First, I copied the existing illustrations from Crafting Interpreters onto my sheet of paper. Then I started trying to draw the steps of static analysis:

I quickly realized why the illustrations don’t continue with this code example.
First, the lexing and parsing steps look similar across compilers. At semantic analysis, the process starts to differ depending on the language. For the sake of my drawings I ignored this fact and picked a random language, but it might be hard to convey that in writing.
Second, the drawings needed to show lines of code outside the original source line, like the assignment of the variables. So a specific example at the semantic analysis stage requires more code than examples did for earlier stages.
That trend continued as I moved from static analysis to intermediate representations. Once again, intermediate representations come in many context-dependent flavors. Bob mentioned “a few well-established styles of IRs” in one of his footnotes. So I looked up each of those styles and attempted to illustrate each one. I based my illustrations on the following more complex example of source code:

For each of these examples, I went to the Wikipedia article, read the introductory text at the top about the pattern, and then skipped down to the code examples.
I started with a control flow graph, which looks pretty much the way you would guess based on the name:
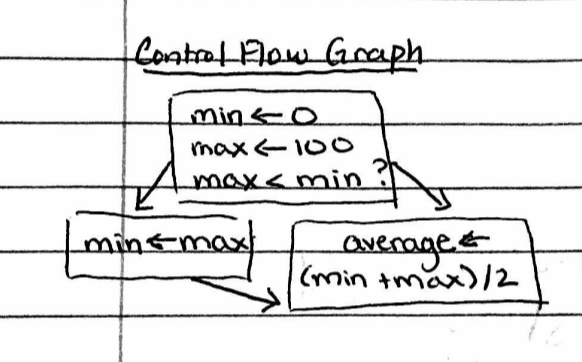
Then I moved on to static single assignment, which dictates that we make a new variable for each new value rather than assigning values back to existing variables. The phi syntax in the third box indicates “one of these two versions of the variable.”

My understanding is that static single assignment gets a lot of use in imperative programming languages like Swift or Java. By contrast, some of the functional programming languages, like Haskell, favor Continuation Passing Style.

I don’t fully understand why yet. I made a cursory attempt to find out, but the resulting answers didn’t seem to even agree that that was the case. One person said it may have more to do with timing than anything else. Many people chimed in with “not an expert, but” (I usually ignore these).
I ended up asking Bob about this, and he cleared things up a bit:
CPS and SSA both exist to make it easier for a compiler to transform code for optimization purposes. Imperative and functional languages have different idioms that optimizers, uh, optimize for, so the two IRs are intended to match those styles better. Optimization is a dark art with a lot of not-written cultural lore, so it’s really hard to separate the material differences between the two forms from the “this is what I was taught and is what I’m most comfortable with”. There’s some research that they have more in common than initially apparent: citeseerx.ist.psu.edu/viewdoc/summar
The final specific style Bob mentioned was Three Address Code, so I drew that one up:

I don’t know that any of these drawings are accurate, and it will be fun to come back later and see what I got wrong. But I do feel much firmer now in my understanding of the steps that get us from source code to an intermediate representation.
I also wanted a firmer understanding of how we get back out to something executable. To Google!
Searching for Examples of Compiler Back Ends
Many of the specific examples described the back end of the Java compiler. Rather than break down the steps, they chiefly discussed the reasons for targeting a virtual machine (in the case of Java, the infamous Java Virtual Machine) rather than the architectures of specific devices. Namely, the bytecode representation ports between devices (though it still has to get translated for each individual device architecture). Andrew Bromage’s response to this quora post also talks about the security of the approach.
I wasn’t looking for why—I was looking for how. So I searched specifically for compiler backend examples. I found this documentation for writing an LLVM back end and skimmed down to “Basic Steps.” It sounds like converting to bytecode involves:
- Identifying the characteristics of the target machine
- Identifying the register of the target machine. I’m not totally clear on what this means yet, but if I understand correctly, register allocation maps the values of the variables in the IR code to specific memory addresses on the target machine.
- Conversion of the expressions in the intermediate representation to machine instructions that the target device can understand.
Once again, I remain unsure about the specific details of compiler back ends, but I have developed a clear enough picture to move into the implementation step with enough background and questions to fully engage with the material there.
Conclusion
While reading the first two chapters of Crafting Interpreters, so far I have:
- Asked questions about the material
- Spelunked open source code in search of answers
- Visualized concrete examples through illustrations
- Expressed my rudimentary understanding of the material
We’re still in the early stages of the learning process. Here, I want to articulate my understanding so that when I find out that the truth differs from it, I register some surprise. That surprise will help to commit what I am learning to memory.
If you liked this piece, you might also like:
The original series on leveling up as a programmer (It’s 20 parts, so brew a cup of tea and strap in.)
watching me refactor toward discoverable code in a React Native app
this video on risk-oriented testing (a concept that’s useful for folks advanced enough to be reading about compiler implementation)
Thanks for the link Chelsea, referrals led me back here. It sounds like your understanding of things might have already progressed past it, but since you were looking for more “real” examples thought I’d mention I’ve got slides from a few OSCON presentations on Python and PHP interpreter internals a few years back that might be of interest: https://tomlee.co/2012/07/oscon-2012-inside-python-php/
If you follow along in the slides and my dodgey, mostly-unhelpful diagrams you should see what the two languages have in common with respect to their implementations, where they diverge, and how it ties back to “real” source code. It might take more “work” on your part to tie the slides back to lines in source files given the format doesn’t lend itself to hyperlinks. 😉
And while I’m on a self-promotion kick there’s also this video from RubyConf 2012: https://www.youtube.com/watch?v=goQZps9vt3o … Unlike the OSCON talks the compiler in question is much more of a toy, but some of the structure of the “compiler” I build there will probably seem familiar if you spend some time studying the slides above.
Anyway: in spite of playing pretend at conferences a few years back I’m no real expert on this stuff, just a tinkerer. I know for a fact Bob can dive into far more depth on any given topic than I ever could, so you’re in good hands with his book. All the best with the study. Have fun!