
When we left off in the last post, our users kept running this query, and they want it to be really fast:
|
1 2 3 4 |
SELECT Id FROM dbo.Users WHERE LastAccessDate > '2014/07/01' ORDER BY LastAccessDate; |
Let’s pre-bake the data by creating a copy of the table sorted in a way that we can find the right rows faster:
|
1 2 |
CREATE INDEX IX_LastAccessDate_Id ON dbo.Users(LastAccessDate, Id); |
This builds a separate copy of our table (also stored in 8KB pages) that looks like this:
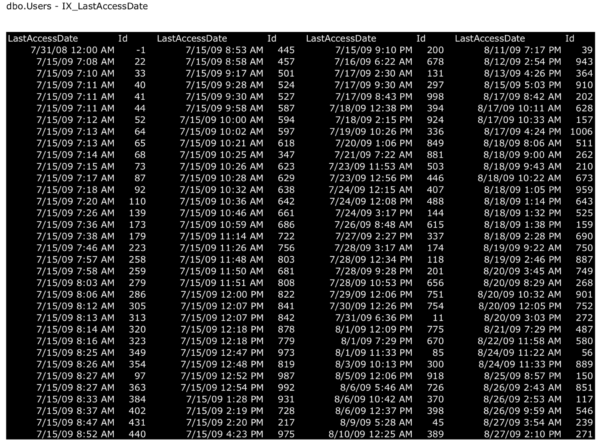
This index slows down inserts and deletes.
The first thing to notice is that you now have two physical copies of the table. Every time you insert a new row, you have to add it in two places. Every time you delete a row, you have to delete it in two places. You’ve effectively doubled the amount of writes that your storage has to do. (Updates are a little trickier – more on that in another post.)
The second thing to notice is that the nonclustered index (black page) is denser: you can fit more users per 8KB page on that because we chose to store less fields. You can see that by running sp_BlitzIndex and looking at the top result set, which shows how big each index is:
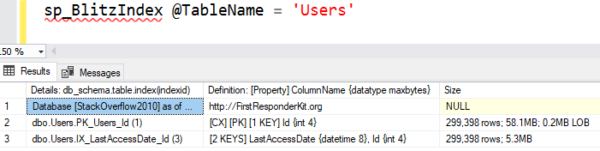
The clustered index (marked CX PK) has ~300K rows and takes up 58.1MB space on disk because it contains all the columns of the table.
The nonclustered index has the same number of rows, but it only takes up 5.3MB space because we’re only storing LastAccessDate and Id on it. The more columns you add to an index – whether they’re in the key, or in the includes – they make the object larger on disk. (I’ll talk more about index design as this series continues.)
But this index pays off dramatically for selects.
Try our select query again – and here, I’m running two queries back to back. I’m running the first query with INDEX = 1 as a hint to show the cost of the clustered index scan. (Index #1 is your clustered index.)
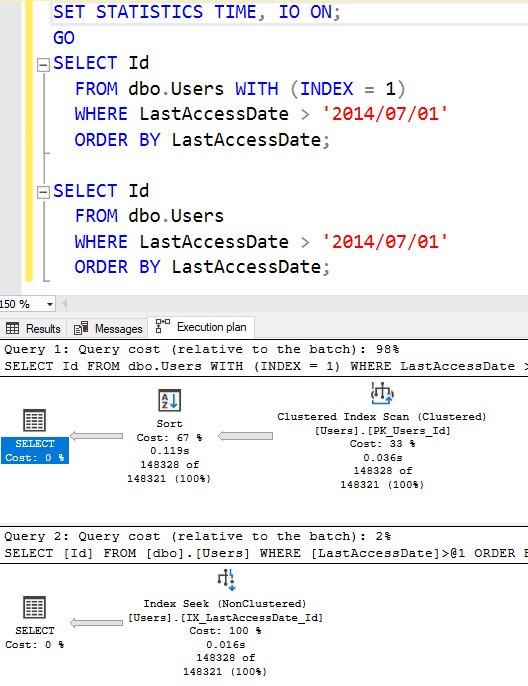
Our new bottom plan is much simpler:
- We get a seek, not a scan – because SQL Server is able to jump right to the rows where LastAccessDate > 2014/07/01. It doesn’t need to scan the whole object to find ’em.
- We don’t need a sort – because as we read the data out, it’s already sorted by LastAccessDate.
The index seek’s cost is lower for two reasons: it doesn’t need the sort, and it reads less 8KB pages. To see how much less, let’s check out the messages tab:
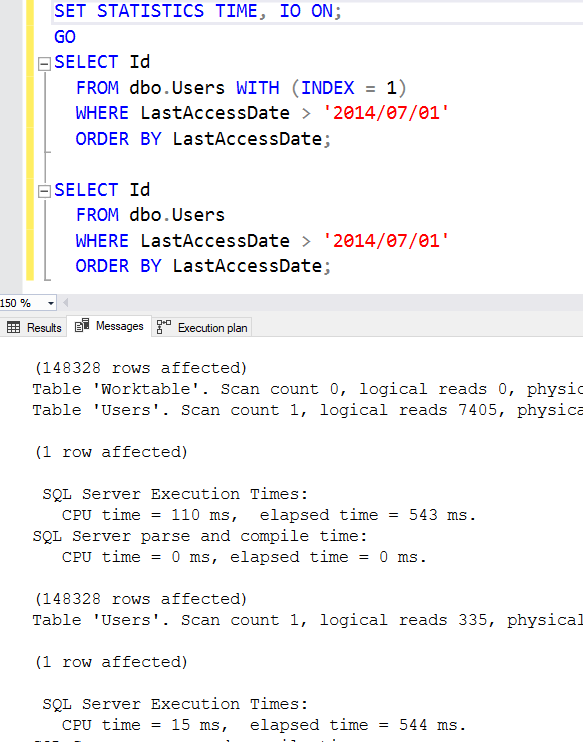
The clustered index scan read 7,405 pages and took 110ms of CPU time to do the ORDER BY.
The new nonclustered index only read 335 pages – like 20X less! – and didn’t need CPU time for ORDER BY. Really good index designs like this are how you can quickly get 20X (or much higher) improvements in your queries without rewriting the queries. Do I wish every query was perfectly tuned? Sure – but even if it was, you’re still gonna need to give the engine a helping hand by organizing the data in more searchable ways.
This index is called a covering index.
The index perfectly covers this query, satisfying everything it needs in a quick, efficient way. The term “covering” isn’t a special kind of index that you create with different syntax – “covering” just refers to the combination of this index AND this query. If you change the query at all – like we’re going to do here shortly – then the index may no longer be covering, and we’ll have to do more work again.
So our plan has an index seek – that’s as good as a plan can get, right? No, as we’ll see in the next episode.

21 Comments. Leave new
Thanks Brent, very understanding thread.
Is including the ID column as part of the secondary index redundant? I was under the impression that the clustered index was included as part of secondary indexes. Are the query plans different if you exclude the ID from the secondary index?
Same here. If the ID is needed I have a lot of rework to do.
It’s not – stay tuned! That’s covered soon in the series.
Oh? Well that is not what is in the Microsoft Documentation and I am depending on that.
https://docs.microsoft.com/en-us/sql/relational-databases/indexes/clustered-and-nonclustered-indexes-described?view=sql-server-ver15
From the second bullet under Nonclustered:
The pointer from an index row in a nonclustered index to a data row is called a row locator. The structure of the row locator depends on whether the data pages are stored in a heap or a clustered table. For a heap, a row locator is a pointer to the row. For a clustered table, the row locator is the clustered index key.
Stephen – the “no” was to your second question, “Are the query plans different if you exclude the ID from the secondary index?” In this case, there’s no difference. (Sorry, I didn’t realize you asked two questions in the comment!)
I thought using a clustered index key as a row locator in a non-clustered index was analogous to translating
CREATE INDEX IX_LastAccessDate_Id ON dbo.Users(LastAccessDate);
to
CREATE INDEX IX_LastAccessDate_Id ON dbo.Users(LastAccessDate) INCLUDE(ID)
This is not the same as what Brent used.
Some high level differences between keys and included columns:
1. An included column cannot be used to narrow the search space (Not applicable to Brent’s query, since he did not filter on ID).
2. Modifying a key column may force the data to be physically repositioned (modifying identity columns is uncommon).
Hahaha, hang on, wait. Lots of good discussion in here, but there’s a lot of stuff related coming up in the next few posts around these very questions. Hold tight before you go too deep into Trivial Pursuit territory. 😉
Will you get similar results if you include the ID column as an included column like
CREATE INDEX IX_LastAccessDate_Id
ON dbo.Users(LastAccessDate)
INCLUDE (id)
Uche – yep, the leaf pages of the index will look identical to the black pages I’m showing above. In the leaf pages, whether you put a column as part of the key or part of the includes, in both cases, the column will be there.
Thanks Brent, interesting fact is that when i tested it out, both NC indexes shared the 100% query cost equally, but after clearing cache and running the original query again SQL chose the included column index as the most optimal i guess very weird no?
Uche – nah, not really. It doesn’t really make any difference at all in the query shown in this post. In subsequent posts in the series, we have much more complex queries where the key order definitely matters, and matters a lot. Stay tuned!
Thanks
What about processes with multiple DML statements? Any advantage to DISABLING indexes before DML and then REBUILD after DML? Plus adding a filtered Index in between just to populate my temp table that is souce for DML? I know, this is when you wish the ‘COMMENT’ option wasn’t available!!
Louis – yeah, that’s pretty far beyond the scope of this blog post, but it’s something we talk about in my Mastering Index Tuning class.
I thought that sorting of results wasn’t guaranteed unless you a) used an order by, or b) returned the clustered index column?
Brian – sorting is *only* guaranteed if you use an order by. Returning the clustered index column isn’t enough to get it.
To see for yourself, create the index described in this post, and then run:
SELECT TOP 1000 Id FROM dbo.Users;
But don’t put an order by in there. Check out what comes back, and to understand why, look at the execution plan.
Sorry Brent, I misread part of your post. Here you must have been referring to not needing the sort operator in the execution plan, rather than not needing a sort (order by) clause in the query:
“We don’t need a sort – because as we read the data out, it’s already sorted by LastAccessDate.”
Brian – no worries! But definitely make sure you run that query I described though – that’s going to be a big eye-opener for you about assumption #2.
Hi Brent, In this example the LastAccessedDate (last time the user logs in) is really not in ASC order with the ID and thus the Nonclustered index you added (LastAccessedDate, ID) would not be sorted.
You said:
“We don’t need a sort – because as we read the data out, it’s already sorted by LastAccessDate”
Wouldn’t the LastAccessDate really be the Clustered index here? Or am I jumping into something else here?
Really enjoy all your posts! Thanks!
Max – if you create an index on LastAccessDate, Id like this:
CREATE INDEX IX_LastAccessDate_Id ON dbo.Users(LastAccessDate, Id);
Then the data really is sorted like how it looks in the black pages in the post. To see it for yourself, run this query after creating the index:
SELECT LastAccessDate, Id FROM dbo.Users ORDER BY LastAccessDate, Id;
And then look at the execution plan. You’ll see a scan of the index, without a sort operation, and the data will be ordered by LastAccessDate, then Id. The fact that there’s no sort in the execution plan is your proof that the data in the index is indeed sorted in that order – SQL Server is able to just scan the data out without doing any work.
If you disagree, go ahead and show me your question using real index creation statements & queries from the database we’re using here in the post. Thanks!