
As part of recruitment processes one of the most common questions is: “What is the difference between struct and class”, we usually can hear that class is copied by reference and struct by value. But what does it even mean? Let’s start with general introduction to Memory Management
What is memory?
We can try to imagine memory as array of cells, each cell contains an information. Typically size of this information is one byte (e.g. bin: 01100101, hex: 0x65), each cell is associated with address which allows us to write or read value from this particular address. Assuming our app is using 20 Megabytes, we have to use 20 000 000 cells, and each cell contains 8 bits.
On the picture above, on the left there is the address and on the right is the value associated with this address. But what happens when value we want to store is bigger than size of one cell?
Little-endian vs Big-endian
The purpose of both of those terms is to decide in which order bytes are stored in memory. Big-endian stores most significant value at the lowest storage address, little-endian is doing the opposite. Let’s take a look at this examples:
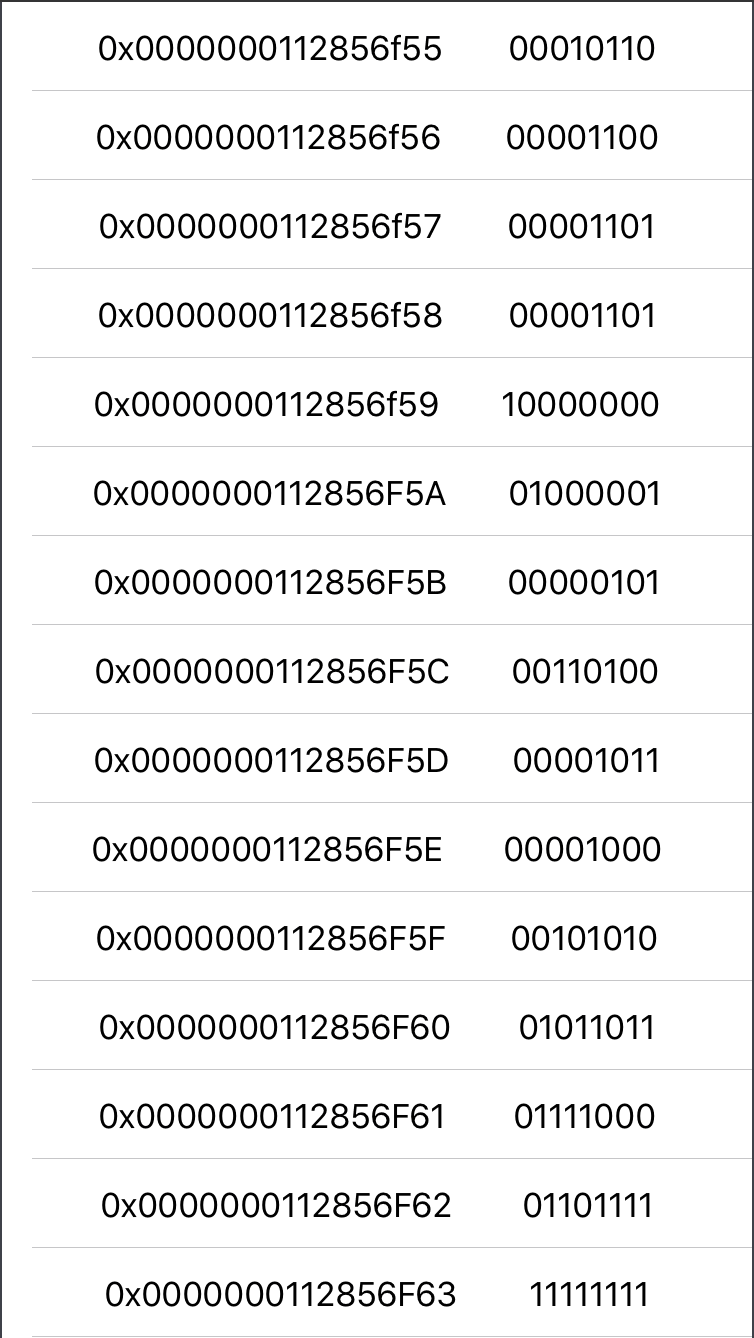
decimalValue: Int16 = 20306
The binary value of this Integer is 100111101010010
So let’s split those bits by size of our cells which is 1 byte.
firstPart = 01001111
secondPart = 01010010
We need two cells, to allocate this value in memory.
Big-endian
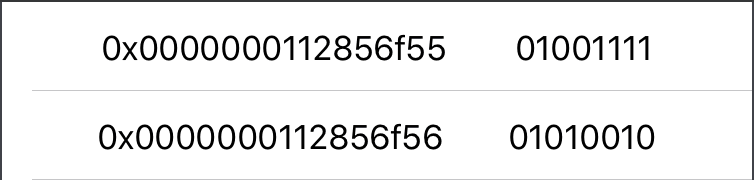
Little-endian
As you can see Big-endian seems more natural for people who read left to right but the problem is with increasing a number, when number growths in binary system, numbers are added to the left side.
bin: 1111 == dec: 15
bin: 0001 1111 == dec: 31
So if our number growths in memory, in Big-endian notation we would have to rewrite all addresses values, in Little-endian we would just append it at the end.
1) decimalValue = 255 //bin: 1111 1111
2) decimalValue += 256 // bin: 0000 0001 1111 1111 dec: 511
1)

Big-endian
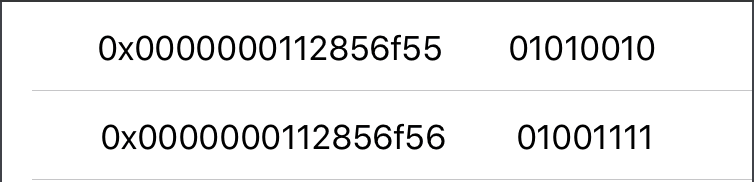
2)

As you can see the value from memory address 0x0000000112856f55 was rewritten to 0x0000000112856f56
Little-endian
2)

New value was assigned at the end (new memory address)
Why do I care? Swift vs bits
You will seldom have to know the difference between Big-endian and Little-endian, or even understand how memory looks like. But if you’d like to grow as a developer and understand how things work under the hood - continue reading.
Xcode and Memory Viewer
import Foundation
var helloWorld = “Hello, World!”
withUnsafePointer(to: &helloWorld) { print($0) }
print(helloWorld)
Let’s put a breakpoint on print, when the breakpoints fires, we can activate memory viewer in Xcode! (Yes it exists ❤️) , when execution is paused on breakpoint just go to Debug -> Debug Workflow -> View Memory.
In our console we can see printed hexadecimal memory address, thanks to it we know address of memory we want to show in our viewer, just paste address and press enter.
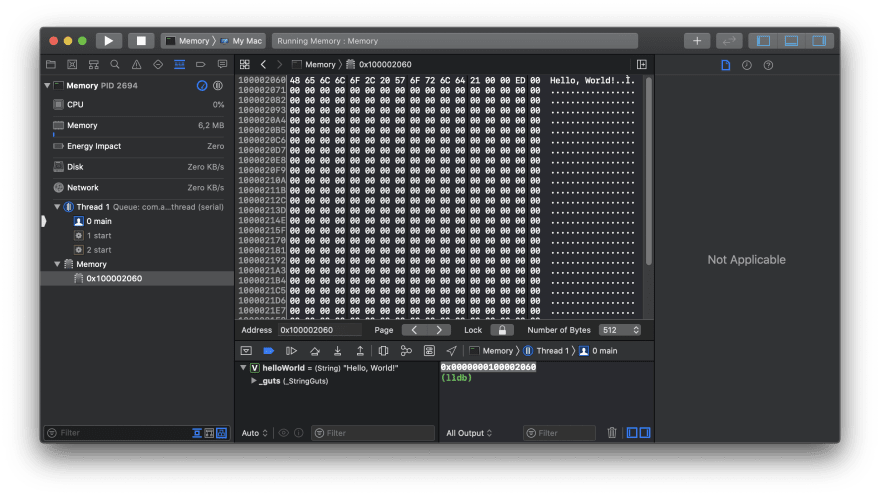
Now we can check how is it stored on my Mac!
In the left column we can see the addresses of the first cells in each row written in hexadecimal, we can change it to decimal by tapping on left column.
In the center there are cells with their values. Each cell value is one Byte, so value stored under address 0x100002060 is 48 hexadecimal, which means character H, because this string is encoded in UTF-8 whose representation is the same as ASCII for Latin alphabet, here is simple Ascii table - representing values associated with characters, if you’d like to know more about ascii, encoding and decoding please let me know!
In the right column we can see preview of memory Hello, World!í this is our value displayed in preview.
There are few questions that comes to mind:
Is it Big-endian or Little-endian?
It is Little-endian, just replace the string value with 511 from example above and compare results, value is also hexadecimal, we would expect that value isFF 01It’s hard to debug it on characters, because ascii strings arearraysof single byte values, that’s why endianness does not affect the order.What is this special character, and why is it prefixed with 2 bytes of 0x00?
My system is 64 bits so size of this string is not 13 bytes, even if it only contains 13 characters, it’s 2*8 bytes, last byte has a special value to indicate end of string.
We can easily check size of this string by running
print(MemoryLayout.size(ofValue: helloWorld)) //prints 16
Copy by reference
Look at this example:
//
// Created by Michał Rogowski on 27/09/2019.
//
import Foundation
class TestClassByReference {
var value1 = “test”
var value2 = “test2”
var value3 = “test3”
var value4 = “test4”
var value5 = “test5”
var value6 = “test6”
var address: UnsafeMutableRawPointer {
return Unmanaged.passUnretained(self).toOpaque()
}
}
var testObject = TestClassByReference()
var copyTestObject = testObject
print(“testObject:”)
print(testObject.address)
print(“copyTestObject:”)
print(copyTestObject.address)
copyTestObject.value1 = “change”
print(“testObject address after change:”)
print(testObject.address)
print(“copyTestObject address after change:”)
print(copyTestObject.address)
print(testObject)
We should add two break points, on copyTestObject.value1 = “change” and on last print.
On first breakpoint we can notice that two addresses are the same, so jump to memory viewer!
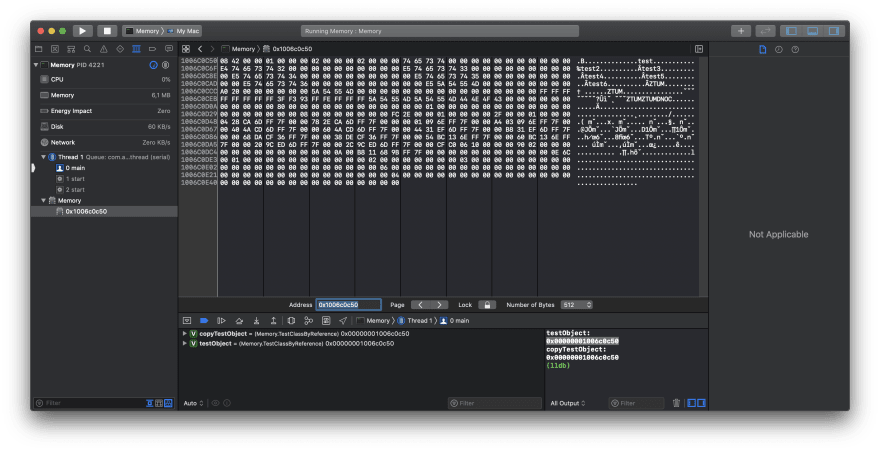
On the right column, our properties values are visible (test, test2, test3 etc.), now we can continue program execution, address of variables did not change, so we can move to memory viewer again.
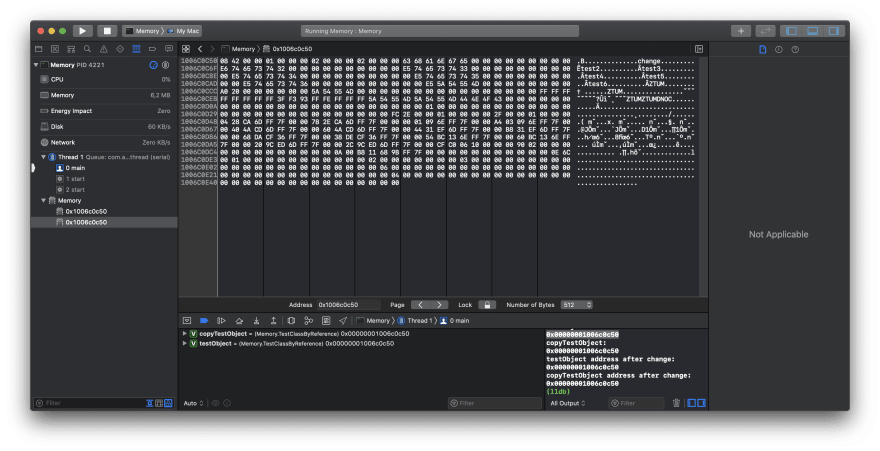
Value test was changed and the memory reflects that by presenting a new string value in a place of previous one! Both instances point to same address - share a single copy of data. This explains the first category of instances types supported by Swift which is Reference Type.
Copy-on-Write
//
// Created by Michał Rogowski on 27/09/2019.
//
import Foundation
extension Array where Element == String {
var address: UnsafePointer<String>? {
withUnsafeBufferPointer { $0.baseAddress }
}
}
var testObject = [“test”, “test2”, “test3”, “test4”, “test5”, “test6”]
var copyTestObject = testObject
print(“testObject:”)
print(testObject.address)
print(“copyTestObject:”)
print(copyTestObject.address)
copyTestObject[0] = “change”
print(“testObject address after change:”)
print(testObject.address)
print(“copyTestObject address after change:”)
print(copyTestObject.address)
print(testObject)
Now we can debug it step by step, compare the addresses of both arrays before changing value in our copy. Addresses are the same, but what happens after our change.
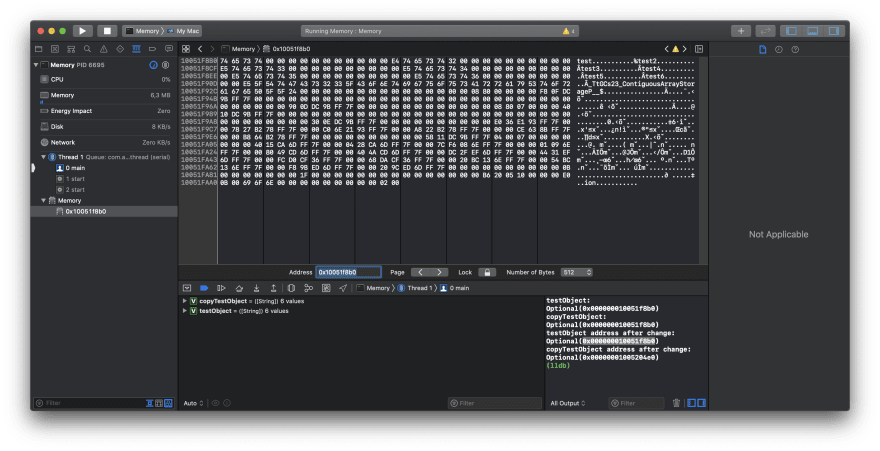

Address was changed and whole array was rewritten.
We have to notice that Copy-on-Write is only implemented for certain types, for example Arrays. If you’d like to use it for your structures-to optimise memory, you would have to create value wrapper, as described by Apple Here
Copy by value
Second category that is supported by Swift are Value Types. That means each instance keeps unique memory location for its data. Take a look
//
// Created by Michał Rogowski on 27/09/2019.
//
import Foundation
struct MyStruct {
let value = 5
}
var firstStruct = MyStruct()
var copyStruct = firstStruct
withUnsafePointer(to: &firstStruct) { print($0) } //print 0x00000001000040b0
withUnsafePointer(to: ©Struct) { print($0) } //print 0x00000001000040b8
Both properties have different addresses since the begging, in this case the memory addresses are allocated by 8 Bytes (Because of 64-bit system).
As you can read in Swift Documentation:
/// A signed integer value type.
///
/// On 32-bit platforms, `Int` is the same size as `Int32`, and
/// on 64-bit platforms, `Int` is the same size as `Int64`.
Why should we waste 8 bytes for variable that needs only 1 byte? What would happen if we change default Int in our structure to Int8? Change declaration of Int in MyStruct
struct MyStruct {
let value: Int8 = 5
}
And those are allocated addresses for this two structs:
0x0000000100004088
0x0000000100004089
Now the difference between addresses is only 1 Byte. We were able to free 7 bytes of memory per instance of MyStruct just by changing declaration to Int8, on the other hand you have to be careful to choose correct size because integer overflow may cause unintended behaviour.
Value Types are usually defines as a struct, enum, or tuple (Int in Swift is also a Struct).
In-Out Parameters
We can think about memory efficiency not only by allocating one Byte integers instead of eight Byte, but there is also In-Out Parameter
As Swift documentations states Here:
In-out parameters are passed as follows:
1. When the function is called, the value of the argument is copied.
2. In the body of the function, the copy is modified.
3. When the function returns, the copy’s value is assigned to the original argument.
This behaviour is known as copy-in copy-out or call by value result.
struct InoutStruct {
var value = “test”
mutating func printAddress() {
withUnsafePointer(to: &self) { print(“address = \($0)”) }
}
}
func addTestInout(to inoutStruct: inout InoutStruct) {
inoutStruct.value += “ test”
inoutStruct.printAddress()
}
func addTest(to normalStruct: InoutStruct) -> InoutStruct {
var inoutStructCopy = normalStruct
inoutStructCopy.value += “ test”
inoutStructCopy.printAddress()
return inoutStructCopy
}
var inoutStruct = InoutStruct()
var normalStruct = InoutStruct()
inoutStruct.printAddress() //0x0000000100003090
normalStruct.printAddress() //0x00000001000030a0
addTestInout(to: &inoutStruct) //0x0000000100003090
normalStruct = addTest(to: normalStruct) //0x00007ffeefbff270
inoutStruct.printAddress() //0x0000000100003090
normalStruct.printAddress() //0x00000001000030a0
We’ve done the “same” operation twice to separate instances of InoutStruct, if you go through Memory View, you can check that, in the memory we have 3 instances of InoutStruct. One of those is variable inoutStructCopy. It’s clear now that, inout parameter is memory efficient if we want to change instance that is Value Type in function. There is no extra rewrite, which means you wan’t have to waste time and memory when changing really big Value Type instances.
Thanks!




{kind=link}
Top comments (3)
great one thank you
Very interesting and insightful content, thanks for writing it! However, your english level in this article is quite low, please work on it cause it's a bit hard to consume :)
Best regards
Thanks! I know you’re right, I hope next article will be more consumable :)