blog
Achieving MySQL Failover & Failback on Google Cloud Platform (GCP)

There are numerous cloud providers these days. They can be small or large, local or with data centers spread across the whole world. Many of these cloud providers offer some kind of a managed relational database solution. The databases supported tend to be MySQL or PostgreSQL or some other flavor of relational database.
When designing any kind of database infrastructure it is important to understand your business needs and decide what kind of availability you would need to achieve.
In this blog post, we will look into high availability options for MySQL-based solutions from one of the largest cloud providers – Google Cloud Platform.
Deploying a Highly Available Environment Using GCP SQL Instance
For this blog we want is a very simple environment – one database, with maybe one or two replicas. We want to be able to failover easily and restore operations as soon as possible if the master fails. We will use MySQL 5.7 as the version of choice and start with the instance deployment wizard:
We then have to create the root password, set the instance name, and determine where it should be located:
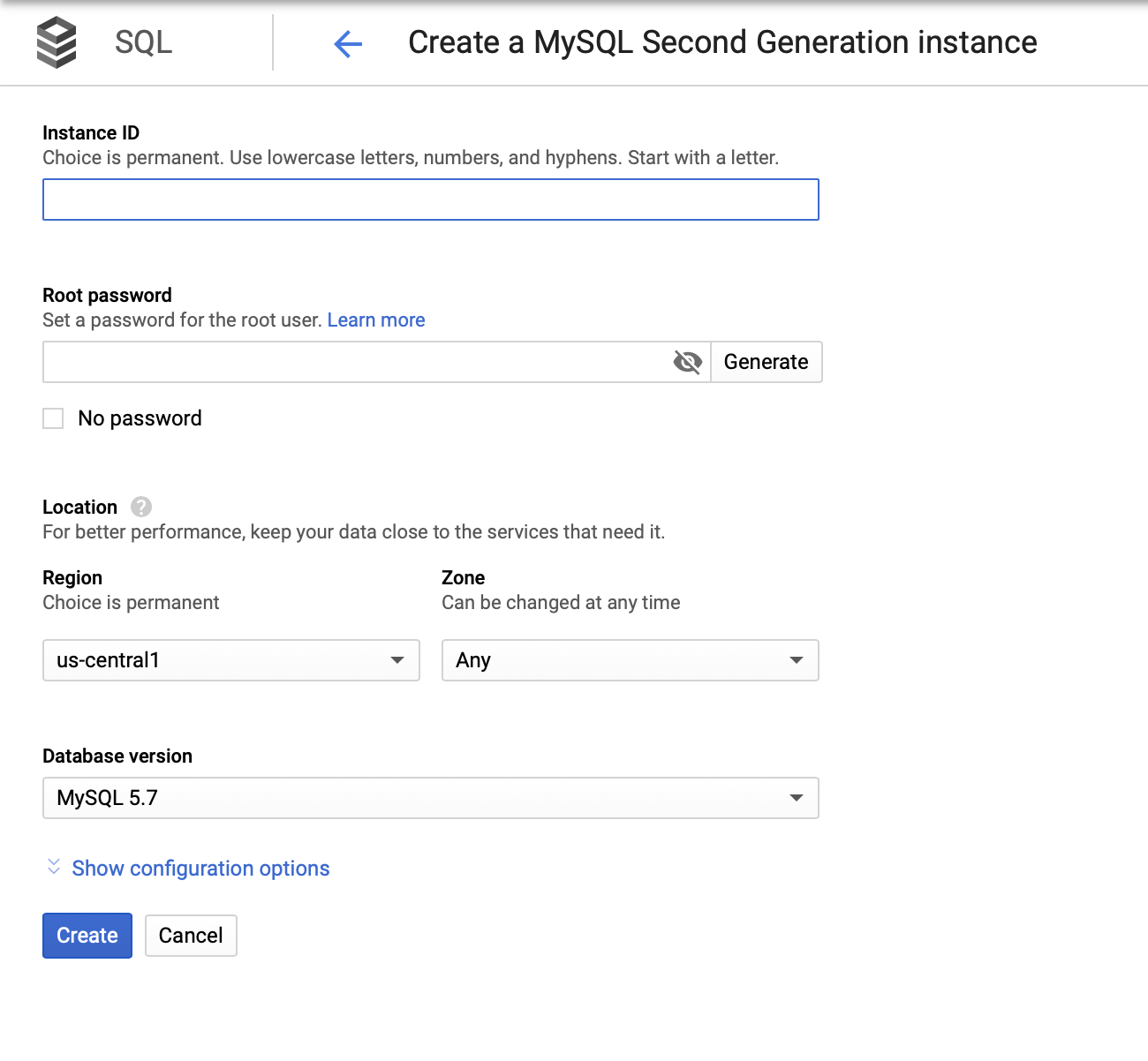
Next, we will look into the configuration options:
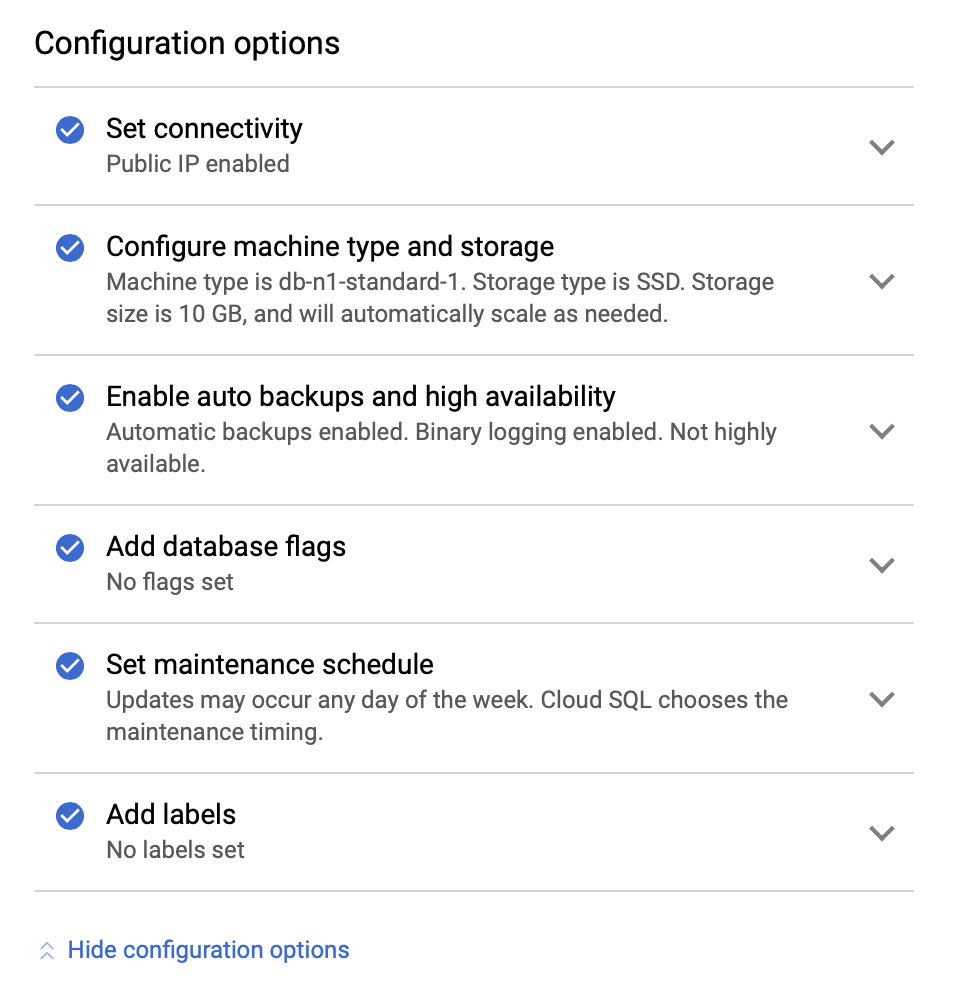
We can make changes in terms of the instance size (we will go with db-n1-standard-4), storage, and maintenance schedule. What is most important for us in this setup are the high availability options:
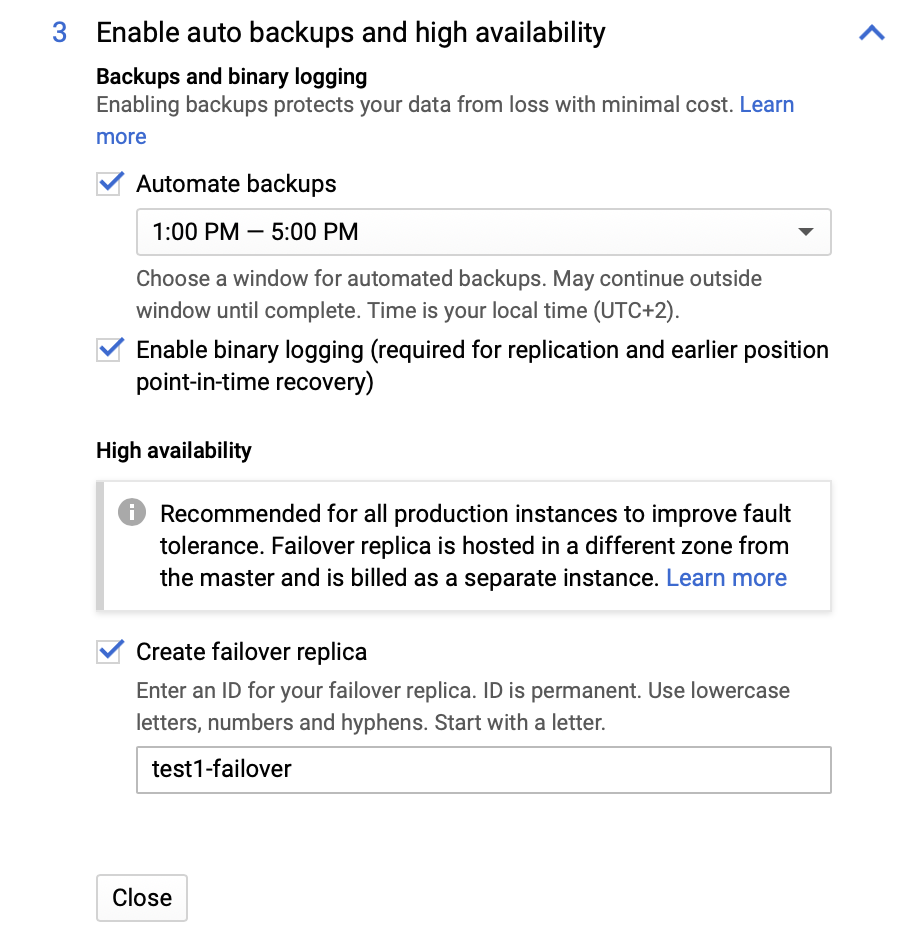
Here we can choose to have a failover replica created. This replica will be promoted to a master should the original master fail.

After we deploy the setup, let’s add a replication slave:
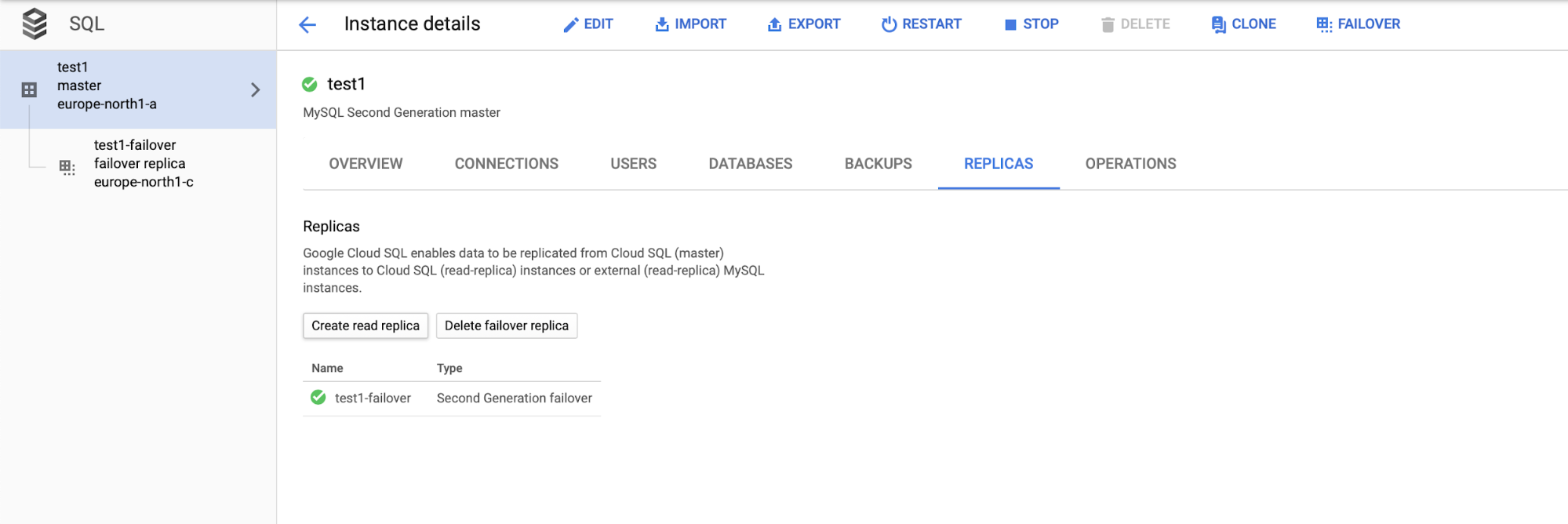
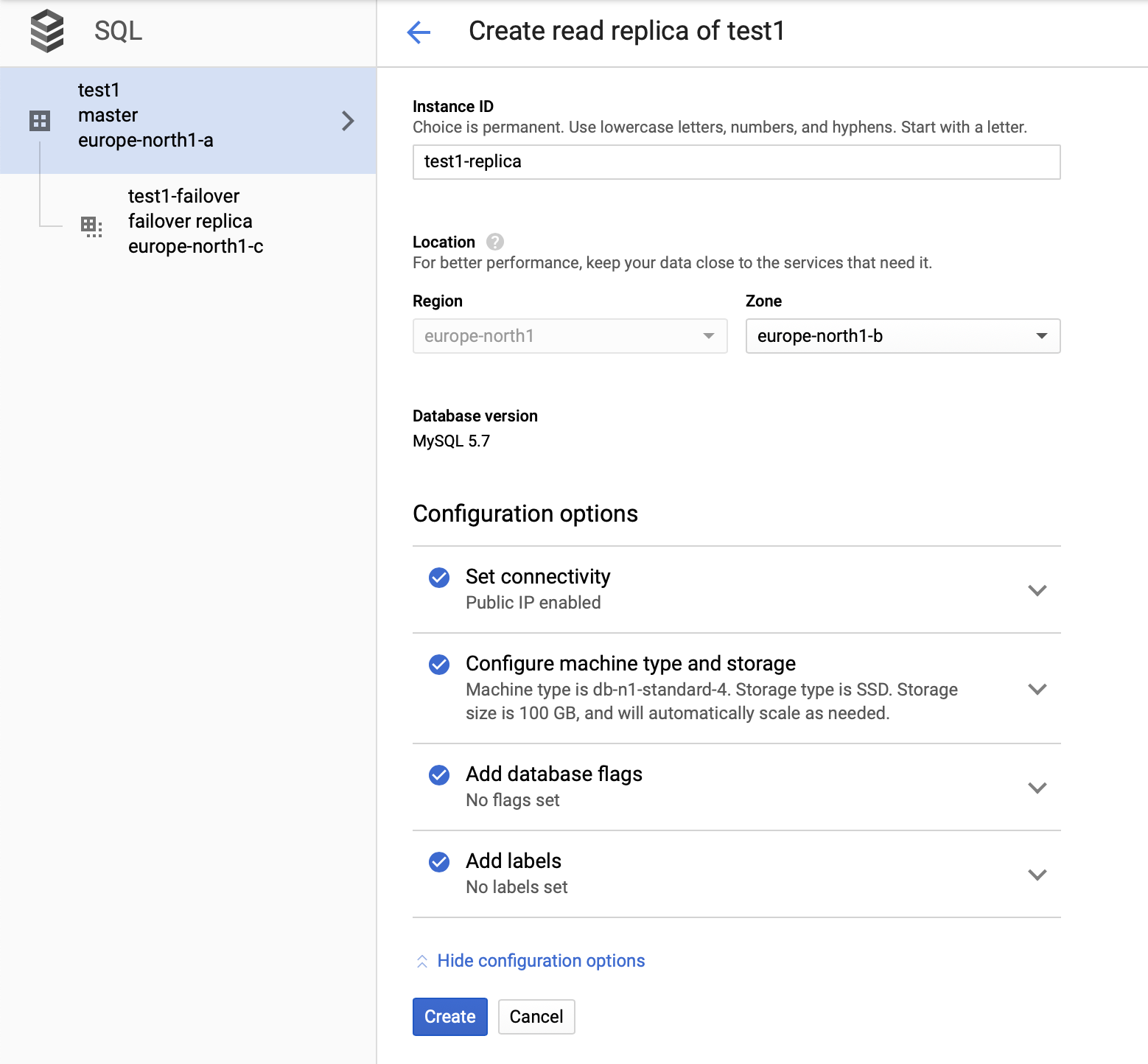
Once the process of adding the replica is done, we are ready for some tests. We are going to run test workload using Sysbench on our master, failover replica, and read replica to see how this will work out. We will run three instances of Sysbench, using the endpoints for all three types of nodes.
Then we will trigger the manual failover via the UI:
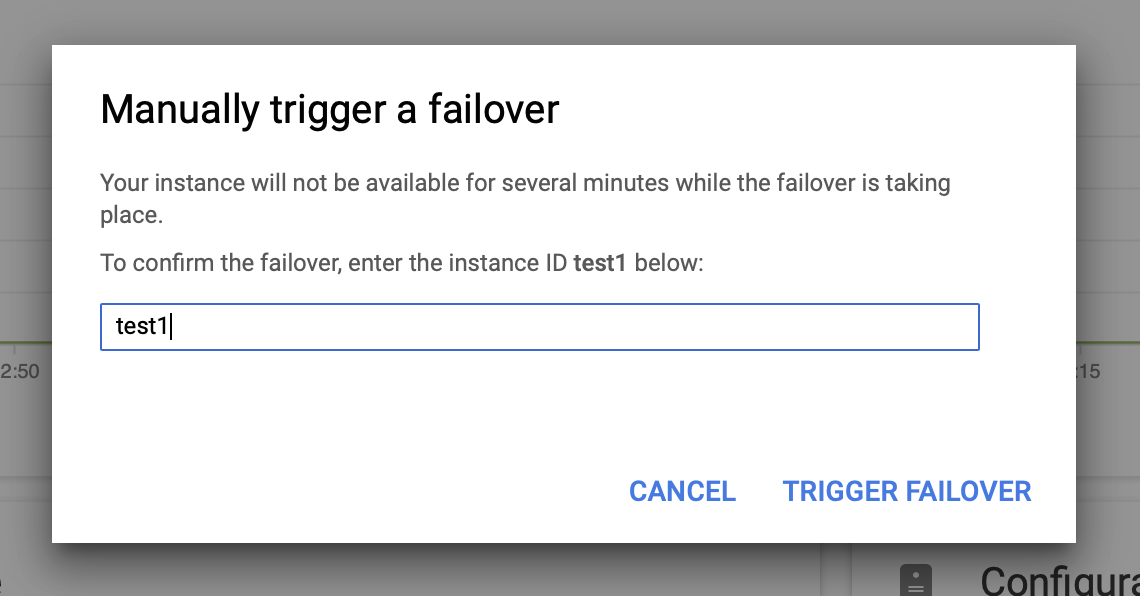
Testing MySQL Failover on Google Cloud Platform?
I have got to this point without any detailed knowledge of how the SQL nodes in GCP work. I did have some expectations, however, based on previous MySQL experience and what I’ve seen in the other cloud providers. For starters, the failover to the failover node should be very quick. What we would like is to keep the replication slaves available, without the need for a rebuild. We would also like to see how fast we can execute the failover a second time (as it is not uncommon that the issue propagates from one database to another).
What we determined during our tests…
- While failing over, the master became available again in 75 – 80 seconds.
- Failover replica was not available for 5-6 minutes.
- Read replica was available during the failover process, but it became unavailable for 55 – 60 seconds after the failover replica became available
What we’re not sure about…
What is happening when the failover replica is not available? Based on the time, it looks like the failover replica is being rebuilt. This makes sense, but then the recovery time would be strongly related to the size of the instance (especially I/O performance) and the size of the data file.
What is happening with read replica after the failover replica would have been rebuilt? Originally, the read replica was connected to the master. When the master failed, we would expect the read replica to provide an outdated view of the dataset. Once the new master shows up, it should reconnect via replication to the instance (which used to be failover replica and which has been promoted to master). There is no need for a minute of downtime when CHANGE MASTER is being executed.
More importantly, during the failover process there is no way to execute another failover (which sort of makes sense):
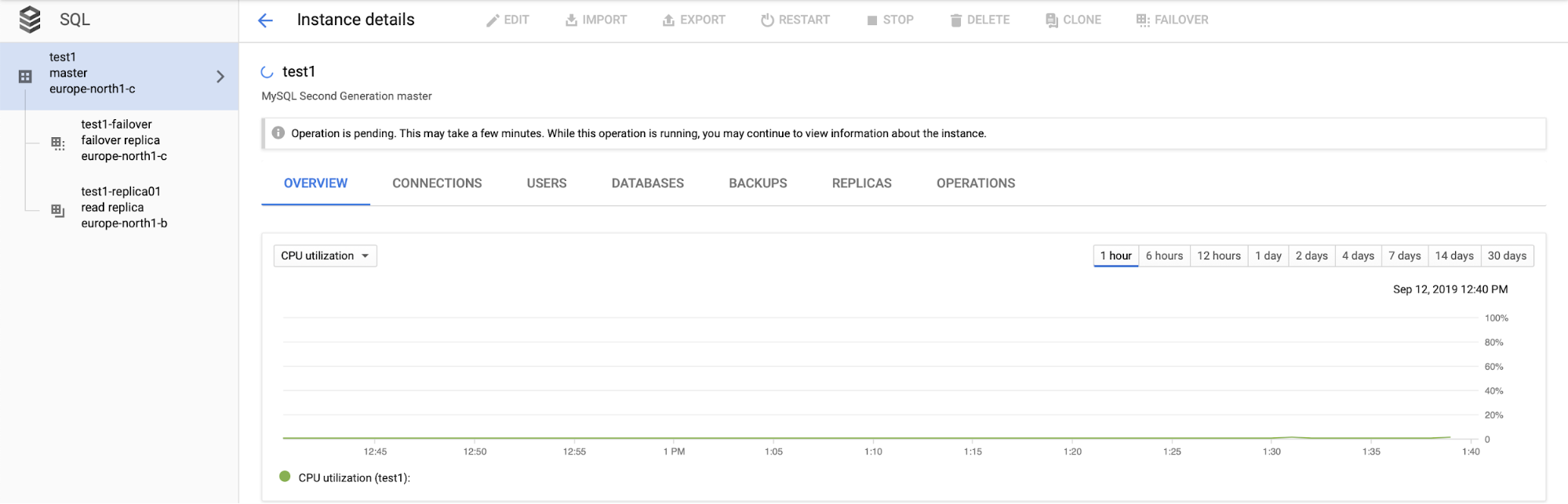
It is also not possible to promote read replica (which not necessarily makes sense – we would expect to be able to promote read replicas at any time).

It is important to note, relying on the read replicas to provide high availability (without creating a failover replica) is not a viable solution. You can promote a read replica to become a master, however a new cluster would be created; detached from the rest of the nodes.
There is no way to slave your other replicas off the new cluster. The only way to do this would be to create new replicas, but this is a time-consuming process. It is also virtually non-usable, making the failover replica to be the only real option for high availability for SQL nodes in Google Cloud Platform.
Conclusion
While it is possible to create a highly-available environment for SQL nodes in GCP, the master will not be available for roughly a minute and a half. The whole process (including rebuilding the failover replica and some actions on the read replicas) took several minutes. During that time we weren’t able to trigger an additional failover, nor we we able to promote a read replica.
Do we have any GCP users out there? How are you achieving high availability?