Admissions

Alright, I admit it. I’ve been relying too much on async / await. It makes it a lot easier for my brain to organize how the code is running. This isn’t a big deal until I am not taking advantage of Node’s awesome asychronous I/O, which does come into play a lot with web scraping.
The code

The example code is pretty simple. I’m using Axios as my request library. It’s a promise based library that is very simple to use and as I discussed in this post, was a library I had more success with not getting blocked by websites.
const websites = [
'https://amazon.com',
'https://google.com',
'https://www.reddit.com/r/Entrepreneur/comments/cwjkcm/launching_a_service_that_provides_business_leads/',
'https://www.reddit.com/r/Entrepreneur/',
'https://bing.com',
'https://reddit.com',
'https://linkedin.com',
'https://yahoo.com',
'https://www.reddit.com/r/funny/',
'https://youtube.com',
'https://twitter.com',
'https://instagram.com',
'https://www.amazon.com/dp/B07HB2KL4C',
'https://www.amazon.com/dp/B01LTHP2ZK', 'https://www.reddit.com/r/funny/comments/cwnmwv/not_a_huge_fan_of_the_new_candy_machine_at_work/',
'https://boise.craigslist.org/',
'https://boise.craigslist.org/d/office-commercial/search/off',
'https://boise.craigslist.org/d/science-biotech/search/sci',
'https://baidu.com',
'https://msn.com',
'https://www.ebay.com/deals/home-garden'
];
// scrapeWithAwait(websites);
scrapeWithoutAwait(websites);
I just have a large list of random websites and then I pass them as an argument to either scrapeWithoutAwait or scrapeWithAwait. scrapeWithAwaitcalls the websites but waits for each one to complete. I’ll admit that I was doing this much too often before without even realizing that it was slowing me down so much. Without even really realizing that there was a better way.
The code for that looks like this:
async function scrapeWithAwait(websites: string[]) {
const overallStartTime = new Date();
for (let i = 0; i < websites.length; i++) {
const startTime = new Date();
let axiosResponse;
try {
axiosResponse = await axios({
method: 'GET',
url: websites[i],
headers: { 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36 " },
timeout: 7000
});
console.log('successful axios call!', axiosResponse.status, Date.now() - +(startTime), websites[i]);
}
catch (error) {
if (error.response) {
console.log(' Error getting website from response', websites[i], error.response.status);
status = error.response.status;
}
else if (error.request) {
console.log(' Error getting website from request', error.request.message, websites[i]);
}
else {
console.log(' Eome other error', error.message);
}
};
}
console.log('Finished with blocking calls', Date.now() - +(overallStartTime));
}
The code starts and simply makes one axios call to the website, waits until it completes, and then calls the next one. This method makes sure we get a result back and we wait until we have that result until we execute the next part of our code. Check the total times for three attempts doing it this way.
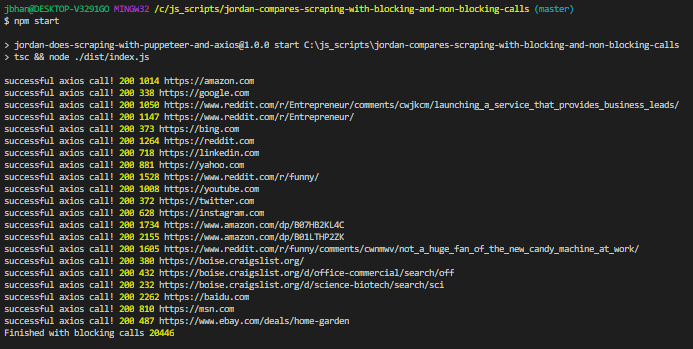
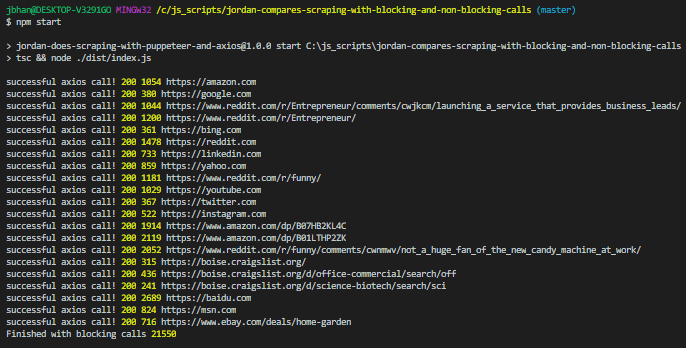
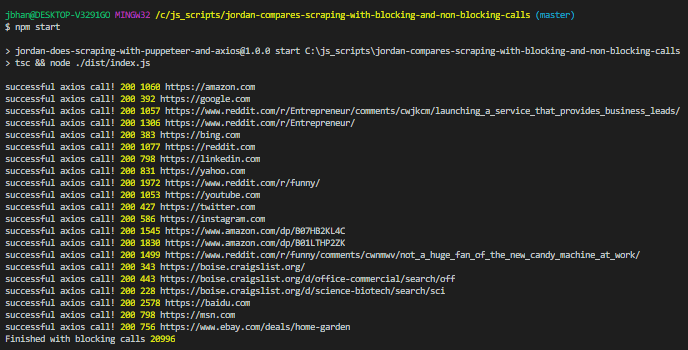
The three attempts each completed in about 20 seconds.
Now I’ll look at the code without blocking calls.
async function scrapeWithoutAwait(websites: string[]) {
const overallStartTime = new Date();
const promises: any[] = [];
for (let i = 0; i < websites.length; i++) {
const startTime = new Date();
promises.push(axios({
method: 'GET',
url: websites[i],
headers: { 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36 " },
timeout: 7000
}).then(axiosResponse => {
console.log('successful axios call!', axiosResponse.status, Date.now() - +(startTime), websites[i]);
}).catch(error => {
if (error.response) {
console.log(' Error getting website from response', websites[i], error.response.status);
status = error.response.status;
}
else if (error.request) {
console.log(' Error getting website from request', error.request.message, websites[i]);
}
else {
console.log(' Eome other error', error.message);
}
}));
}
await Promise.all(promises);
console.log('Finished without blocking calls', Date.now() - +(overallStartTime));
}
This code is similar to the one above except it doesn’t wait for the request to complete. It takes advantage of .then to make sure the response is handled whenever it completes.
In this example, I am using an array and storing the promises in it. Because I want to know when I am completely finished, I use await Promise.all(promises). That will block my final portion of code, the console.log from executing until all of the promises are complete but it won’t block execution of the other items from the loop.
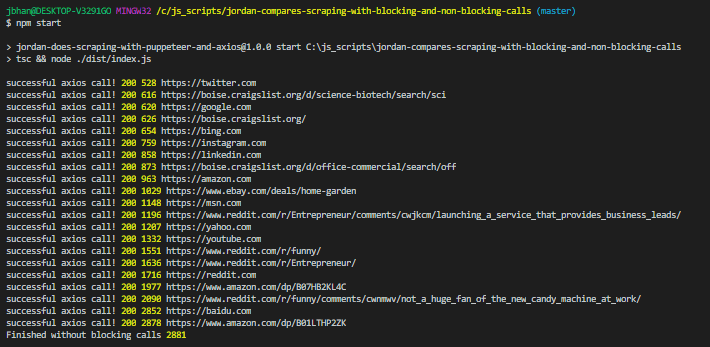

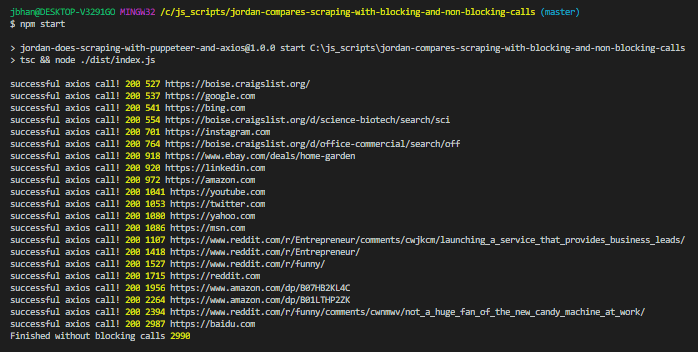
The time difference is very significant, between 3 seconds without blocking and 20 with blocking.
Don’t Ddos

One thing to always be sensitive of when web scraping is the burden you are placing on the scraped website. In this scenario, I’m spreading out my requests over many different websites so there is no real concern of overburden on a website.
If you are scraping one website without any kind of limiting or blocking with many requests, you are going to slam dangerously hard. I tested it on this website to get a little feel for how bad it would hurt.
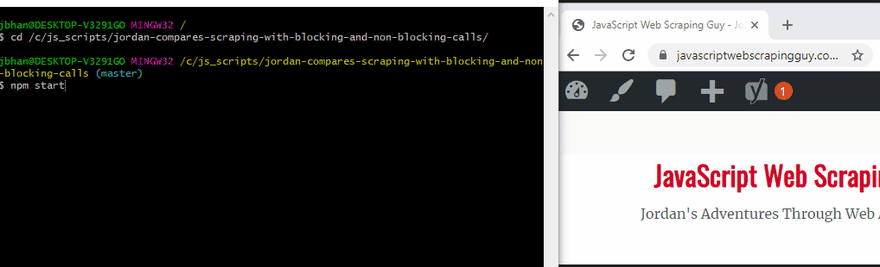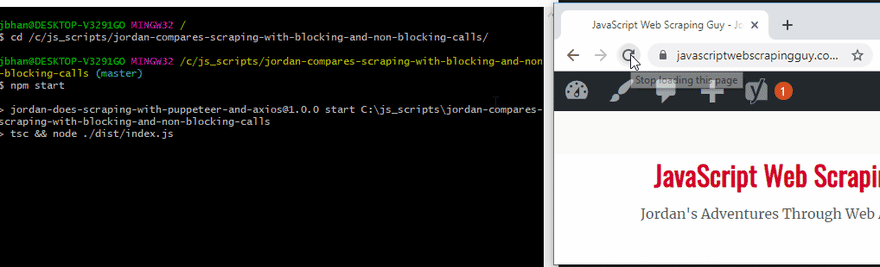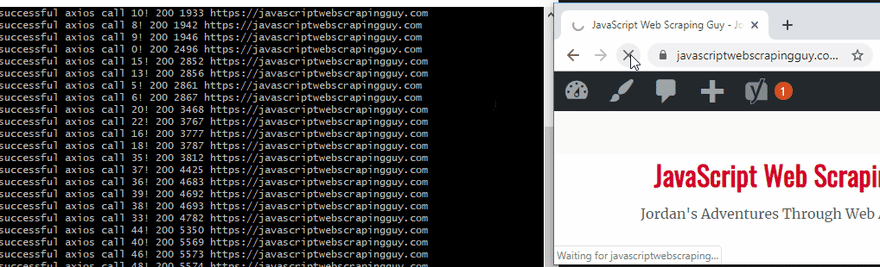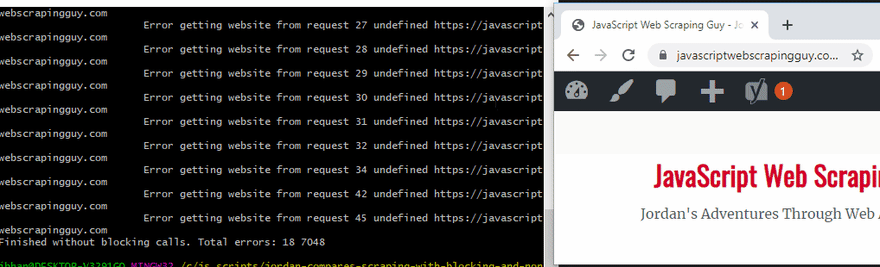
The above is me hitting this site 50 times. You see the load time increase significantly once it starts hitting it.
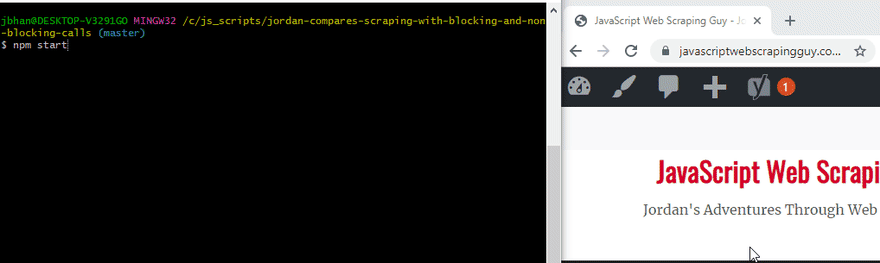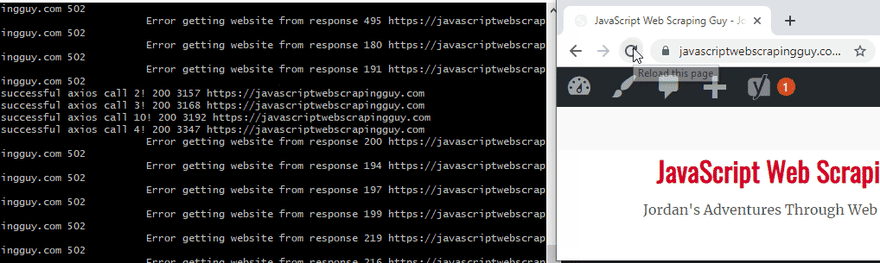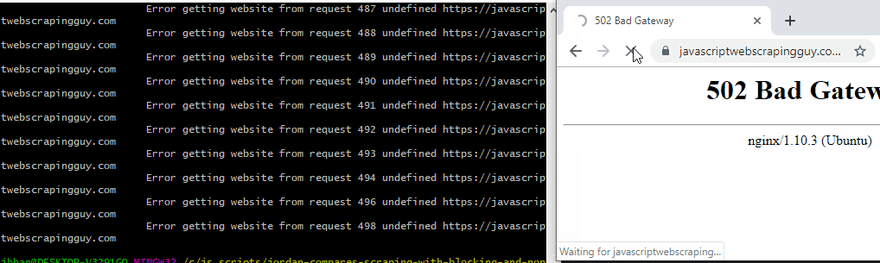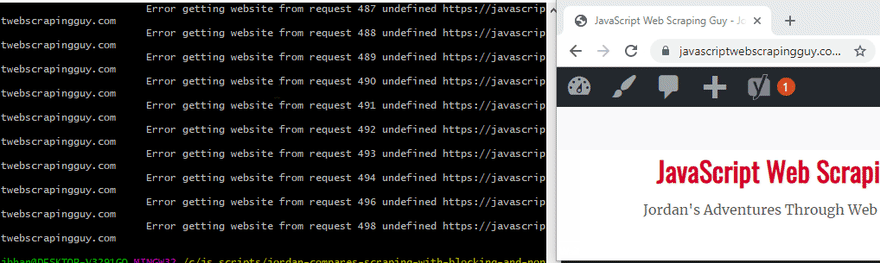
Now let’s try hitting it 500 times. Ouch, did you see the 502 gateway error? I have successfully Ddos’d myself very simply. “In the US, denial of service attacks may be considered a federal crime under the Computer Fraud and Abuse Act with penalties that include years of imprisonment.” – Wikipedia. Ouch. Let’s not do that.
I’m not saying that using blocking calls is a proper rate limiting technique but I am saying to be careful when using the speed that non blocking allows on a single host.
Looking for business leads?
Using the techniques talked about here at javascriptwebscrapingguy.com, we’ve been able to launch a way to access awesome business leads. Learn more at Cobalt Intelligence!
The post Jordan Compares Scraping with Blocking and Non Blocking Calls appeared first on JavaScript Web Scraping Guy.





Top comments (0)