Fighting referral spam
Published on ; updated on
Occasionally I like to look through this site’s http logs to get an idea of how many people read my articles and find out when someone links to one of them.
At some point I noticed that the visitor numbers inflated and most referrers became fake. But this wasn’t the referral spam that I was used to, when the referrer points to the spammer’s website.
Quite the opposite, referrals often pointed to other Haskell-related blogs — byorgey.wordpress.com, blog.ezyang.com, blog.plover.com etc. I suspect these were harvested from Planet Haskell.

Yet it was clear that the referrers were fake. The referring and referred articles were not related in any meaningful way, and upon inspection the referring articles indeed did not refer to this site. For example, the logs indicated that Mark Dominus linked to my article about stable pointers from his article about a Turkish John Doe, or that FPComplete found my intro to golden tests integral to measuring the success of devops.
But that left me puzzled — if this was spam, where’s the message? Who would profit from sending me to these seemingly relevant but unrelated articles on legit blogs?
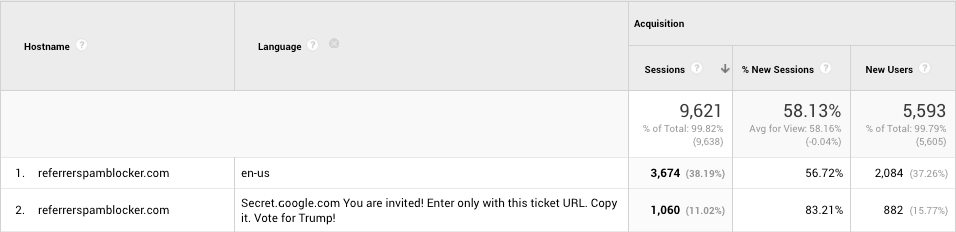
My searches led me to this article by now defunct project Referrerspamblocker.com. Turns out the message is nowadays placed in the http headers such as Accept-Language, which are not traditionally logged by the web servers but shown by the spammers’ main target, Google Analytics.
Finding spammers’ IP addresses
Most of the spam IP addresses I observed came from two hosting providers: OVH and Online SAS. Both companies are French, and both have been noticed by webmasters before (OVH, Online SAS). A small fraction of spam requests also came from Tiscali France B2B, apparently a French division of an Italian telecom company.
So I needed to collect the IP addresses that belong to these hosting providers. Since they are not ISPs, I was not worried about blocking legitimate users.
Once I had the IP addresses, I could
- clean up the existing http logs, and
- block the future spam traffic to avoid wasting resources.
I used the method described here to extract
all RIPE addresses whose maintainers matched
(?:OVH|ONLINESAS)-MNT|MNT-TISCALIFR-B2B. All of these are
French companies, so most of their IP addresses are in the RIPE
database.
However, OVH also has some Canadian IPs, which are covered by ARIN.
Sadly, ARIN does
not provide its IP address database for bulk download like RIPE
does. For now I manually added the block 158.69.0.0/16,
which I recovered via WHOIS from a couple of IP addresses in my
logs.
You can download the final list of IPv4 ranges here.
Cleaning up the existing logs
I used the R packages iptools, purrr, and
dplyr to filter the referral spam:
refspam_ranges <- scan("refspam.txt", what=character())
is_refspam_ip <- function(ips) {
map(refspam_ranges, function(range) ip_in_range(ips, range)) %>%
reduce(`|`)
}
remove_refspam <- function(d) filter(d, !is_refspam_ip(address))Blocking the spam using firewalld
I expect something like this to work:
xargs -n 1 -I{} firewall-cmd --permanent --add-rich-rule="rule family='ipv4' source address='{}' drop" < refspam.txtBut I haven’t blocked them just yet. Instead, I’ve added
$http_accept_language to the nginx’s
log_format and am now anxious to finally learn what the
spammers have been trying to tell me for so long.
Also, see the next section.
Legitimate bots
(Added on 2018-03-26.)
Mark Dominus wrote to me to say that he also had this problem and also added:
Is your idea that because the sources are hosting providers rather than ISPs, you will only be blocking bots running on hosted services? But isn’t there still a concern that you might also block legitimate bots hosted at the same providers?
Fair point. I ran a query to see if there were any self-identified bots coming from those addresses, and I was very surprised to see so many (n is the number of requests made in the last 90 days):
| agent | n |
|---|---|
| Mozilla/5.0 (compatible; AhrefsBot/5.2; +http://ahrefs.com/robot/) | 2142 |
| Barkrowler/0.7 (+http://www.exensa.com/crawl) | 1387 |
| CommaFeed/2.5.0-SNAPSHOT (https://github.com/Athou/commafeed) | 398 |
| Mozilla/5.0 (compatible; AhrefsBot/5.2; News; +http://ahrefs.com/robot/) | 296 |
| Mozilla/5.0 (compatible; MJ12bot/v1.4.8; http://mj12bot.com/) | 148 |
| Mozilla/5.0 (compatible; MJ12bot/v1.4.7; http://mj12bot.com/) | 106 |
| Mozilla/5.0 (compatible; PaperLiBot/2.1; http://support.paper.li/entries/20023257-what-is-paper-li) | 64 |
| FeedHQ/2017.07.18.1500363079 (https://github.com/feedhq/feedhq; ping; https://github.com/feedhq/feedhq/wiki/fetcher; like FeedFetcher-Google) | 32 |
| Mozilla/5.0 (compatible; HackerfallBot; +http://hackerfall.com/help/bot) | 30 |
| python-requests/2.18.4 | 22 |
| LivelapBot/0.2 (http://site.livelap.com/crawler) | 17 |
| python-requests/2.11.1 | 10 |
| SocialRankIOBot; http://socialrank.io/about | 5 |
| Tiny Tiny RSS/17.12 (e35a467) (http://tt-rss.org/) | 3 |
| FeedHQ/2018.03.21.1521618317 (https://github.com/feedhq/feedhq; ping; https://github.com/feedhq/feedhq/wiki/fetcher; like FeedFetcher-Google) | 2 |
| Mozilla/5.0 (compatible; ImageFetcher/7.0; +http://images.weserv.nl/) | 2 |
| Mozilla/5.0 (compatible; yiphysearchbot; +http://37.187.121.74/bot.php) | 2 |
| node-superagent/0.18.2 | 2 |
| Python-urllib/3.5 | 2 |
| curl/7.57.0 | 1 |
| GuzzleHttp/6.2.1 curl/7.47.0 PHP/7.1.11-1+ubuntu16.04.1+deb.sury.org+1 | 1 |
| Mozilla/5.0 (compatible; Grobbot/2.2; +https://grob.it) | 1 |
| Tiny Tiny RSS/17.12 (http://tt-rss.org/) | 1 |
| Wget/1.14 (linux-gnu) | 1 |
Self-identified bots accounted for 14% of all http requests coming from OVH et al (the rest must be spammers). Most of these bots look legit. Moreover, several are RSS readers, which I most certainly don’t want to block. So I won’t be adding any firewall rules after all.
Are these bots self-aware?
(Added on 2018-04-08.)
Since I published this post, the spammy referrers magically stopped.

The total number of requests from the identified IP ranges dropped sharply, and the remaining ones had either no referrer or a sane referrer like ro-che.info or planet.haskell.org.
These are some hypotheses as to what could happen, although none of them strikes me as very likely.
- These bots are self-aware; they found out that I exposed them and altered their behavior.
- The bots’ owners found my article and altered their bots’ behavior.
- Around the same time as I wrote this article, I moved the site from a server in Germany to one in the UK. Was there something preventing the bots from updating their DNS records for two weeks?
- Or maybe they are not interested in spamming British servers?