
I'm pretty sure that if the Stack Overflow survey asked developers what is their greatest fear, the top 1 spot would be held by regular expressions. And while some simple ones are not-so-complicated to make, there is one in particular that I've been avoiding for over a decade before finally trying to understand it... Matching a string literal!
String literals are the way to communicate to your programming language a string of characters that you would like to be loaded as a string object. Basically:
const foo = "bar";
Here the string literal is "bar".
While usually the language handles it, there might be several reasons why you need to parse that string yourself, most likely when you're analyzing one language with another. The last time I did something like this was when writing a tool to patch WordPress SQL dumps.
That's pretty simple to do, until you need to handle "bar \" baz" or "bar\xa0!". In this article, we'll go over the ways to parse the different parts of a string literal.
— Note —
This article is written with JSON-ish strings in mind but will explore various parsing problems and solutions. And of course this is not a definitive guide, many different options exist and that is just a few of them.
The regex syntax is the one from JavaScript.
All regular expressions in this article are linked to Regex101 to help you decode and test the expression. Don't hesitate to click the links!
Simplest case
For now we'll just try to parse a simple string without anything fancy. We'll consider the following test case:
"bar"
const foo = "bar";
foo("bar", "baz");
The first thing I wanted to write was /".*"/.

As you can see, the . also matches ", causing the match to take "bar", "baz" in one go. In order to avoid this you can simply use a *? (lazy) quantifier instead of just *. Let's try /".*?"/

Much better! But not good enough for reasons you'll understand in the next part. Think about our true intent: since we've not defined any escape mechanism, the string can contain literally any character except " which marks the termination of the string.
Any character is the dot . but you can also make blacklists using the [^] syntax. In that case [^"] will match any character except ". So the final expression would be:
/"[^"]*"/
You still get this:
Escaping the quote
There is two ways to escape quotes. Either you double it "say ""foo""", either you backslash it "say \"foo\"". It varies depending on the language. Most languages chose to backslash it but you'll find everything out there. We're going to study both.
Double
The easiest way to handle quotes escapes is probably to double them. That's because it's very easy to think about it. Inside your string, you will allow:
- Not quotes —
[^"] - Two quotes next to each other —
""
When put together you get /"([^"]|"")*"/.

Surprisingly it works from the first try!
Backslash
Let's try to run our previous simple expression on the test phrase.
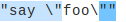
As you can see, it doesn't care much for the backslash and it detects two different strings.
Let's think about what kind of content we want to allow between the two quotes:
- "Not quotes", at least not bare ones. Just like above.
[^"] - Escaped quotes, so
\". If you translate it into regex syntax, you get\\".
That's typically something you can do by putting different alternatives in a matching group. Let's try "([^"]|\\")*".
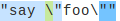
Oh noes, it is broken. Because yes, the backslash does match the [^"] specification. So we actually need to write that in reverse: /"(\\"|[^"])*"/

Now we're getting somewhere. But depending on the order is a little bit trivial and is not so safe. Let's amend what we said earlier:
- Neither quotes, neither backslashes —
[^"\\] - Escaped quotes —
\\" - Backslash followed by anything but a quote —
\\[^"]
Let's try /"([^"\\]|\\"|\\[^"])*"/

And that works fine! But wait, isn't this expression a little bit stupid? Let's factorize it:
-
[^"\\]|\\"|\\[^"]— Any of those three -
[^"\\]|\\("|[^"])— Grouping"and[^"]together -
[^"\\]|\\.— Since"and[^"]together will match "quote or non-quote" it means they will match any character, so they can be replaced by a.
Our final expression is then "([^"\\]|\\.)*"/.
We now have a fully-functional string-extracting regex!
The inside syntax
The code we've seen above guarantees to parse a string even if there is a few escaped " inside of it. However it doesn'g guarantee that the inside of the string makes sense. Most of string parsers will look for the patterns they recognize and leave the rest untouched. Suppose we just handle the regular \n, \r or \t:
1 — The literal
"say \"foo\"\nsay \"bar\!\""
2 — Unquoting using the regex from above
say \"foo\"\nsay \"bar\!\"
3 — Replace the escape characters
say "foo"
say "bar\!"
Please note how the \! stays \!. That's the behavior of Python. If you were to do that in JavaScript it would replace it into just !. It depends on the definition:
- You can either say
\XisXunless a pattern is found (JavaScript does that) - Or
\Xmatches no pattern so it stays as-is (Python's logic) - Or
\Xmatches no pattern so it's a syntax error (what happens in JSON by example)
JSON escape characters
All languages have their own set of escape character, some being quite universal like \0 or \n while others only exist in some cases or even have different meanings in different languages. As we need to pick a side, let's worry about what JSON offers.
Single characters
A lot of the escaped character patterns are actually just one character. Like \n which is just a mapping to the new line. For those you just need to store the mapping and detect it. The regex to match them is /\\(["\\\/bnrt])/ which allows you to see which character was caught in group 1.

As you might know, the JavaScript String.replace() function allows to take a function as replacement. It will receive the matched groups as arguments and its return value will be used as a replacement.
We're going to use that in order to create a function which does the substitution of those characters.
function subSingle(string) {
const re = /\\(["\\\/bnrt])/g;
const map = {
'"': '"',
'\\': '\\',
'/': '/',
b: '\b',
n: '\n',
r: '\r',
t: '\t',
};
return string.replace(re, (_, char) => map[char]);
}
Unicode
JSON also allows you to type an escaped unicode character, like \uf00f. It's a \u followed by 4 hexadecimal characters. In short /\\u([a-fA-F0-9]{4})/.

While we could go through the trouble of encoding this string into UTF-8 or UTF-16 and then converting this to an internal string object from the language you're using, there is probably a function that already does that in the standard library. In JavaScript it's String.fromCodePoint(), in Python it's the built-in chr() and in PHP it's relatively simple.
Again, we'll use a substitution function with our regular expression to do this.
function subUnicode(string) {
const re = /\\u([a-fA-F0-9]{4})/g;
return string.replace(re, (_, hexCodePoint) => (
String.fromCodePoint(parseInt(hexCodePoint, 16))
));
}
Full JSON string parser
We've seen the different ways to parse a string and its components, now let's apply that to parsing a JSON string literal.
The code is going to be twofold:
- Find the different strings in the input text
- Substitute quoted chars in the extracted strings
It's going to be a simple Vue app which takes the input from a textarea and outputs the list of all the strings it can find in the input.
Find the strings
An important variation of JSON strings is that they don't allow control characters, so basically the \x00-\x19 range is forbidden. That includes newline (\n) among others. Let's twist our string-finding expression a little bit to become /"(([^\0-\x19"\\]|\\[^\0-\x19])*)"/. It matches:
- Not-control-character (
\0-\x19), not-quotes (") and not-backslashes (\\) - Or backslashes (
\\) followed by not-control-characters (\0-\x19)
Let's transform that into JavaScript code:
function findStrings(string) {
const re = /"(([^\0-\x19"\\]|\\[^\0-\x19])*)"/g;
const out = [];
while ((m = re.exec(string)) !== null) {
if (m.index === re.lastIndex) {
re.lastIndex++;
}
out.push(m[1]);
}
return out;
}
That function will simply extract all the strings and put them into an array.
Substitute the characters
Now it's time to substitute the escaped characters. Previously we've done two functions to do that but it's dangerous. By example:
- The string is
"\\ud83e\\udd37" - Unquoted it becomes
\\ud83e\\udd37 - Substitute single characters
\ud83e\udd37 - Substitute Unicode
🤷while it was expected to be\ud83e\udd37
For this reason, Unicode and single characters have to be substituted at the same time. In order to do that, we'll simply merge the two expressions from before into /\\(["\\\/bnrt]|u([a-fA-F0-9]{4}))/.
It matches a backslash \\ followed by:
- One of the
\/bnrtcharacters - A Unicode code point like
\uf00f
Let's also merge the JS code:
function subEscapes(string) {
const re = /\\(["\\\/bnrt]|u([a-fA-F0-9]{4}))/g;
const map = {
'"': '"',
'\\': '\\',
'/': '/',
b: '\b',
n: '\n',
r: '\r',
t: '\t',
};
return string.replace(re, (_, char, hexCodePoint) => {
if (char[0] === 'u') {
return String.fromCodePoint(parseInt(hexCodePoint, 16));
} else {
return map[char];
}
})
}
You'll note how we chose not to validate the escaped characters. Indeed, as seen above, if you write \! in JSON you should get a syntax error. However here you'll just get \!. This is for code simplicity's sake. All valid JSON strings will be parsed correctly by this code, but invalid JSON strings will still be parsed without errors.
Put it all together
Now all what is left to do is to create some code that parses the input and transforms it into the output. We can easily do that with a Vue app.
const app = new Vue({
el: '#app',
data() {
return {
input: `const foo = "say \\"foo\\""`,
};
},
computed: {
output() {
return findStrings(this.input).map(subEscapes);
},
},
});
See it in action:
Conclusion
Starting from the simplest possible string-matching regular expression we've grown it into a full-blown JSON string parser. While there is many pitfalls on the way, the final code is reasonably simple and small (about 40 lines). The methodology applied here allowed to build a string parser but can also be applied to build any kind of regular-expression-based code and I hope you will be able to apply it to your projects!





Top comments (7)
Some comments may only be visible to logged-in visitors. Sign in to view all comments.